配置Spark
参考《深入理解Spark:核心思想与源码分析》
Spark使用Scala进行编写,而Scala又是基于JVM运行,所以需要先安装JDK,这个不再赘述。
1.安装Scala
安装获取Scala:
wget http://download.typesafe.com/scala/2.11.5/scala-2.11.5.tgz
将下载的文件移动到自家想要放置的目录。
修改压缩文件的权限为755(所有者读写执行,同组成员读和执行,其他成员读和执行)
chmod 755 scala-2.11.5.tgz
解压缩:
tar -xzvf scala-2.11.5.tgz
打开/etc/profile,添加scala的环境变量
vim /etc/profile

查看scala是否安装成功:
scala

2.安装完scala后,就要安装spark了
只接从网站上下载了spark安装包:
http://spark.apache.org/downloads.html
将安装包移动到自己指定的位置,解压缩。
配置环境变量:
vim /etc/profile
添加spark环境变量

使环境变量生效:
source /etc/profile
进入spark的conf文件目录,
cd /home/hadoop/spark/spark-2.1.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
在spark-env.sh目录中添加java hadoop scala的环境变量

启动spark:
cd /home/hadoop/spark/spark-2.1.0-bin-hadoop2.7/sbin
./start-all.sh
打开浏览器,输入http://localhost:8080
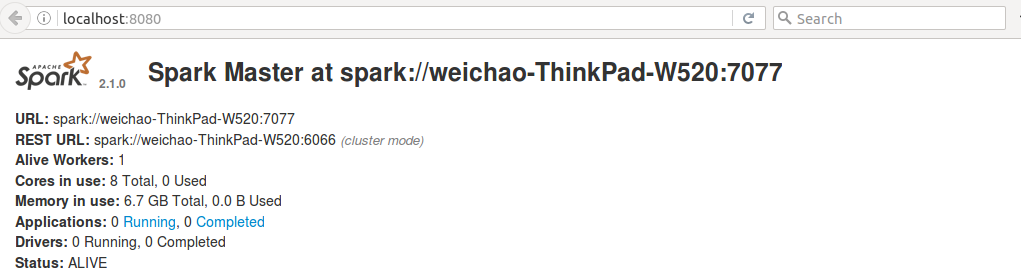
可见Spark已经运行了。
http://blog.csdn.net/wuliu_forever/article/details/52605198这个博客写的很好
配置Spark的更多相关文章
- 配置Spark on YARN集群内存
参考原文:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 运行文件有几个G大,默 ...
- CentOS 7.0下面安装并配置Spark
安装环境: 虚拟机:VMware® Workstation 8.0.1(网络桥接) OS:CentOS 7 JDK版本:jdk-7u79-linux-x64.tar Scala版本:scala-2.1 ...
- spark快速入门之最简配置 spark 1.5.2 hadoop 2.7 配置
配置的伪分布式,ubuntu14.04上 先配置hadoop,参见这个博客,讲的很好 http://www.powerxing.com/install-hadoop/, 但是我在配的过程中还是遇到了问 ...
- 安装配置Spark集群
首先准备3台电脑或虚拟机,分别是Master,Worker1,Worker2,安装操作系统(本文中使用CentOS7). 1.配置集群,以下步骤在Master机器上执行 1.1.关闭防火墙:syste ...
- Linux中安装配置spark集群
一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoop MapReduce所 ...
- 配置spark集群
配置spark集群 1.配置spark-env.sh [/soft/spark/conf/spark-env.sh] ... export JAVA_HOME=/soft/jdk 2.配置slaves ...
- linux上配置spark集群
环境: linux spark1.6.0 hadoop2.2.0 一.安装scala(每台机器) 1.下载scala-2.11.0.tgz 放在目录: /opt下,tar -zxvf scal ...
- 在win10环境下IED配置spark项目
eclipse在对spark的支持上并不友好,所以需要新下载并安装IntelliJ IDEA 2019.1.我下载安装的是专业版的,直接在网上搜索了破解码进行破解. 1. 配置java和scala I ...
- Windows32或64位下载安装配置Spark
[学习笔记] Windows 32或64位下载安装配置Spark:1)下载地址:http://spark.apache.org/downloads.html 马克-to-win @ 马克java社区: ...
- Jupyter配置Spark开发环境
兄弟连大数据培训和大家一起探究Jupyter配置 Spark 开发环境 简介 为Jupyter配置Spark开发环境,可以安装全家桶–Spark Kernel或Toree,也可按需安装相关组件. 考虑 ...
随机推荐
- sqlmap基础入门超详细教程
前言: 总算进入了自己喜欢的行业. 要时刻记得当初自己说过的话, 不忘初心. Come on! 资料: 感谢超哥分享的干货.. sqlmap干货点击直达 学习环境: 本次学习使用的是kali集成的s ...
- [译]Ocelot - Tracing
原文 Ocelot是使用的Butterfly这个项目来实现这个的. 在ocelot要使用tracing, 首先得安装相应的包: Install-Package Ocelot.Tracing.Butte ...
- 2.9 while循环
while循环 <1>while循环的格式 while 条件: 条件满足时,做的事情1 条件满足时,做的事情2 条件满足时,做的事情3 ...(省略)... demo i = 0 whil ...
- Highcharts开发图表
1.折线图 显示一个静态的折线图,显示如下数据 星期 温度 周一 9~14 周二 4~10 周三 1~7 周四 4~9 周五 5~11 周六 8~13 周天 7~10 新建demo1.html < ...
- Django REST Framework API Guide 08
1.Filtering 2.Pagination FIltering GenericAPIView的子类筛选queryset的简单方法是重写.get_quueryset()方法. 1.根据当前用户进行 ...
- Solr简单使用
1.添加索引 // 第一步:把solrJ的jar包添加到工程中. // 第二步:创建一个SolrServer,使用HttpSolrServer创建对象. SolrServer solrServer = ...
- java----Maven
下载地址 http://maven.apache.org/download.cgi 介绍 bin:运行脚本 windows 输入mvn可以运行这些脚本 boot:包含一个类加载器的框架,maven使用 ...
- Swift 使用 日常笔记
//------------------- var totalPrice: Int = { willSet(newTotalPrice) { //参数使用new+变量名且变量名首地址大写 printl ...
- numpy array分割-【老鱼学numpy】
有合并,就有分割. 本节主要讲述如何通过numpy对数组进行横向/纵向分割. 横向/纵向分割数组 首先创建一个6行4列的数组,然后我们对此数组按照横向进行切割,分成3块,这样每块应该有2行,见例子: ...
- MyCat-简介
一MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : corba. 是阿里开发的数据库中间件.实现M ...