IMDB-二分类问题
from keras.datasets import imdb
from keras.utils.np_utils import to_categorical
import numpy as np
from keras import models
from keras import layers
import matplotlib.pyplot as plt
#one-hot编码
def vectorize_sequences(sequences,dimension = 10000):
results = np.zeros((len(sequences),dimension))
for i,sequence in enumerate(sequences):
results[i,sequence] = 1
return results
#imdb是一个二分类问题
#一共有5w条数据,2.5w用于训练,2.5w用于测试
#每条数据是一个list,list里保存的是英文单词对应的排序
#num_words=10000表示保留前1w个常出现的单词
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=10000)
#下面的代码用来解码第一条数据的内容
data = x_train[0]
#word_index是一个dict,保存的是英文单词:单词排序位置
word_index = imdb.get_word_index()
index_word = dict((index,word) for (word,index) in word_index.items())
#i-3是because 0, 1 and 2 are reserved indices for "padding", "start of sequence", and "unknown".
data = ''.join(index_word.get(i-3,'?') for i in data)
######################################################
#神经网络的输入得是一个张量,使用one-hot编码处理数据
x_train = vectorize_sequences(x_train)
x_test = vectorize_sequences(x_test)
#keras的输入数据要转换为float类型,y是int类型,做一个类型转换 #构建神经网络
network = models.Sequential()
network.add(layers.Dense(16,activation='relu'))
network.add(layers.Dense(16,activation='relu'))
network.add(layers.Dense(1,activation='sigmoid')) #选择优化器、损失函数、评估准则
network.compile('rmsprop',loss='binary_crossentropy',metrics=['accuracy']) #训练模型
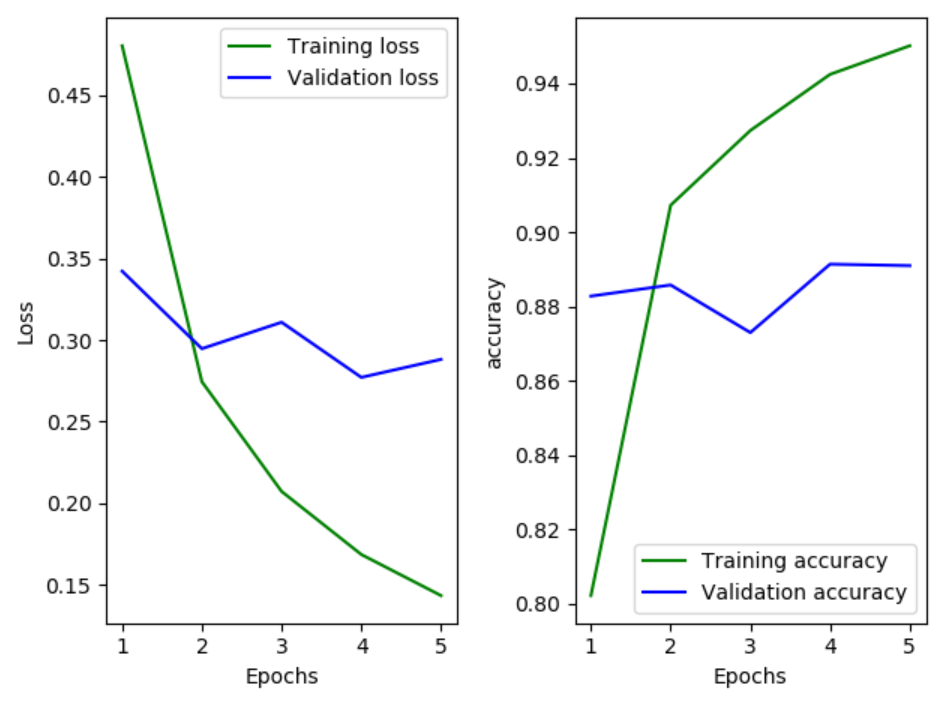
history = network.fit(x_train,y_train,epochs=5,batch_size=512,validation_split=0.2) history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
acc = history_dict['acc']
val_acc = history_dict['val_acc'] epochs = range(1,6)
#loss的图
plt.subplot(121)
plt.plot(epochs,loss,'g',label = 'Training loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
#显示图例
plt.legend() plt.subplot(122)
plt.plot(epochs,acc,'g',label = 'Training accuracy')
plt.plot(epochs,val_acc,'b',label = 'Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show() pre = network.predict(x_test)
print(pre)
print(y_test)
IMDB-二分类问题的更多相关文章
- 基于Keras的imdb数据集电影评论情感二分类
IMDB数据集下载速度慢,可以在我的repo库中找到下载,下载后放到~/.keras/datasets/目录下,即可正常运行.)中找到下载,下载后放到~/.keras/datasets/目录下,即可正 ...
- 电影评论分类:二分类问题(IMDB数据集)
IMDB数据集是Keras内部集成的,初次导入需要下载一下,之后就可以直接用了. IMDB数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的250 ...
- Python深度学习案例1--电影评论分类(二分类问题)
我觉得把课本上的案例先自己抄一遍,然后将书看一遍.最后再写一篇博客记录自己所学过程的感悟.虽然与课本有很多相似之处.但自己写一遍感悟会更深 电影评论分类(二分类问题) 本节使用的是IMDB数据集,使用 ...
- Python深度学习读书笔记-6.二分类问题
电影评论分类:二分类问题 加载 IMDB 数据集 from keras.datasets import imdb (train_data, train_labels), (test_data, t ...
- 二分类问题 - 【老鱼学tensorflow2】
什么是二分类问题? 二分类问题就是最终的结果只有好或坏这样的一个输出. 比如,这是好的,那是坏的.这个就是二分类的问题. 我们以一个电影评论作为例子来进行.我们对某部电影评论的文字内容为好评和差评. ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- keras框架下的深度学习(二)二分类和多分类问题
本文第一部分是对数据处理中one-hot编码的讲解,第二部分是对二分类模型的代码讲解,其模型的建立以及训练过程与上篇文章一样:在最后我们将训练好的模型保存下来,再用自己的数据放入保存下来的模型中进行分 ...
- 【原】Spark之机器学习(Python版)(二)——分类
写这个系列是因为最近公司在搞技术分享,学习Spark,我的任务是讲PySpark的应用,因为我主要用Python,结合Spark,就讲PySpark了.然而我在学习的过程中发现,PySpark很鸡肋( ...
- Kaggle实战之二分类问题
0. 前言 1. MNIST 数据集 2. 二分类器 3. 效果评测 4. 多分类器与误差分析 5. Kaggle 实战 0. 前言 "尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
随机推荐
- Linux下的crontab
Ubuntu服务器/var/log下没有cron日志,这里记录一下如何ubuntu server如何查看crontab日志 crontab记录日志 修改rsyslog sudo vim /etc/rs ...
- C: printf参数执行顺序与前置后置自增自减的影响
起源: 今天在了解副作用side-effect的过程中,看到了下面的网页,把我带到了由printf引起的一系列问题,纠结了一整天,勉强弄懂. 第一个代码没什么好解释的.而第二个printf(" ...
- 遍历HashMap的四种方式
转至:https://www.cnblogs.com/Berryxiong/p/6144086.html public static void main(String[] args) { Map< ...
- protobuf使用详解
https://blog.csdn.net/skh2015java/article/details/78404235 原文地址:http://blog.csdn.net/lyjshen/article ...
- AI佳作解读系列(三)——深度学习中的合成数据研究
Below are some investigation resources for synthetic datasets: 1. Synthetic datasets vs. real images ...
- Linux(Ubuntu)使用日记------部署JavaWeb项目到服务器
0.前言 本博文内容是建立在你可以通过SSH连接到远程服务器的基础上的,如果你还没有用SSH连接到远程服务器,请参考此文(腾讯云服务器): http://www.cnblogs.com/hwtblog ...
- Python爬虫beautifulsoup4常用的解析方法总结
摘要 如何用beautifulsoup4解析各种情况的网页 beautifulsoup4的使用 关于beautifulsoup4,官网已经讲的很详细了,我这里就把一些常用的解析方法做个总结,方便查阅. ...
- tornado之用户验证装饰器
authenticated装饰器 为了使用Tornado的认证功能,我们需要对登录用户标记具体的处理函数.我们可以使用@tornado.web.authenticated装饰器完成它.当我们使用这个装 ...
- Nginx从入门到实践(二)
静态资源web服务 静态资源类型 CDN CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工 ...
- Spring定时器配置与运用,及Cron表达式的详解
一:首先在spring的配置文件里配置一个定时器 <task:executor id="executor" pool-size="5" /> < ...