scrapyd的安装和scrapyd-client
1.创建虚拟环境 ,虚拟环境名为sd

mkvirtualenv sd #方便管理
2. 安装 scrapyd
pip3 install scrapyd
3. 配置
mkdir /etc/scrapyd vim /etc/scrapyd/scrapyd.conf

写入一下配置
参考官网:https://scrapyd.readthedocs.io/en/stable/config.html#config
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
#bind_address = 127.0.0.1
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root [services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
bind_address:默认是本地127.0.0.1,修改为0.0.0.0,可以让外网访问。
一. 部署&运行
deploy: 部署scrapy爬虫程序 # scrapyd-deploy 部署服务器名 -p 项目名称
scrapyd-deploy ubuntu -p douyu
run : 运行 #curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
curl http://127.0.0.1:6800/schedule.json -d project=douyu -d spider=dy
stop: 停止 #curl http://localhost:6800/cancel.json -d project=project_name -d job=jobid
curl http://127.0.0.1:6800/cancel.json -d project=douyu -d job=$1 二. 允许外部访问配置
定位配置文件: default_scrapyd.conf find /home/wg -name default_scrapyd.conf cd /home/wg/scrapy_env/lib/python3.6/site-packages/scrapyd
允许外部访问: vim default_scrapyd.conf bind_address = 0.0.0.0
三. 远程监控-url指令:
1、获取状态 http://127.0.0.1:6800/daemonstatus.json 2、获取项目列表 http://127.0.0.1:6800/listprojects.json 3、获取项目下已发布的爬虫列表 http://127.0.0.1:6800/listspiders.json?project=myproject 4、获取项目下已发布的爬虫版本列表 http://127.0.0.1:6800/listversions.json?project=myproject 5、获取爬虫运行状态 http://127.0.0.1:6800/listjobs.json?project=myproject 6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫) http://127.0.0.1:6800/schedule.json (post方式,data={"project":myproject,"spider":myspider}) 7、删除某一版本爬虫 http://127.0.0.1:6800/delversion.json (post方式,data={"project":myproject,"version":myversion}) 8、删除某一工程,包括该工程下的各版本爬虫 http://127.0.0.1:6800/delproject.json(post方式,data={"project":myproject}) 四. 常用脚本
循环任务: while true
do
curl http://127.0.0.1:6800/schedule.json -d project=FXH -d spider=five_sec_info
sleep 10
done 实时时间打印: echo "$(date +%Y-%m-%d:%H:%M.%S), xx-spider定时启动--"
项目部署
启动:
scrapyd
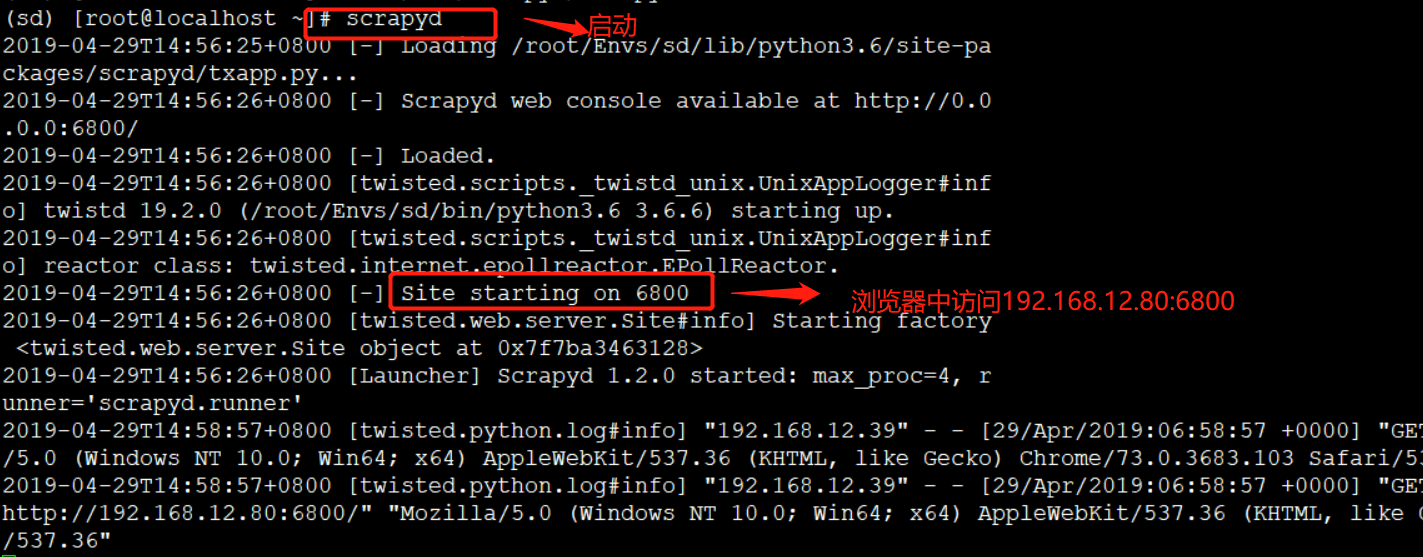
查看本机ip:
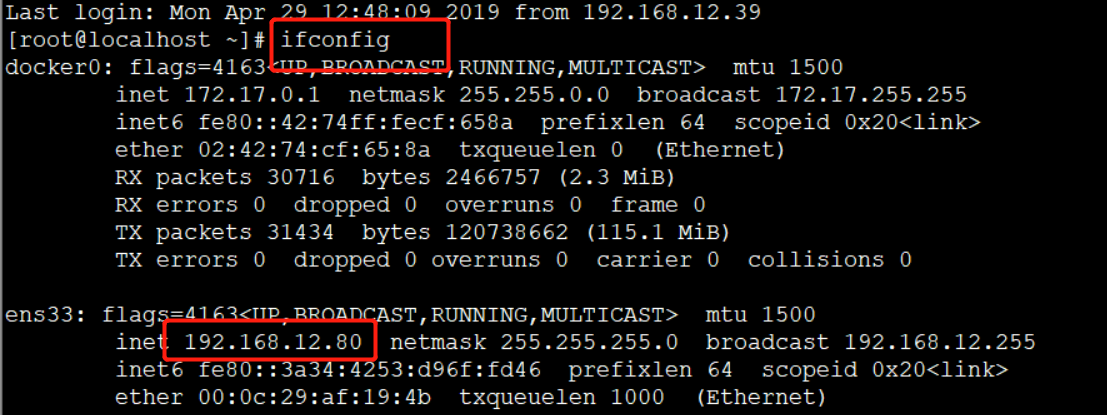
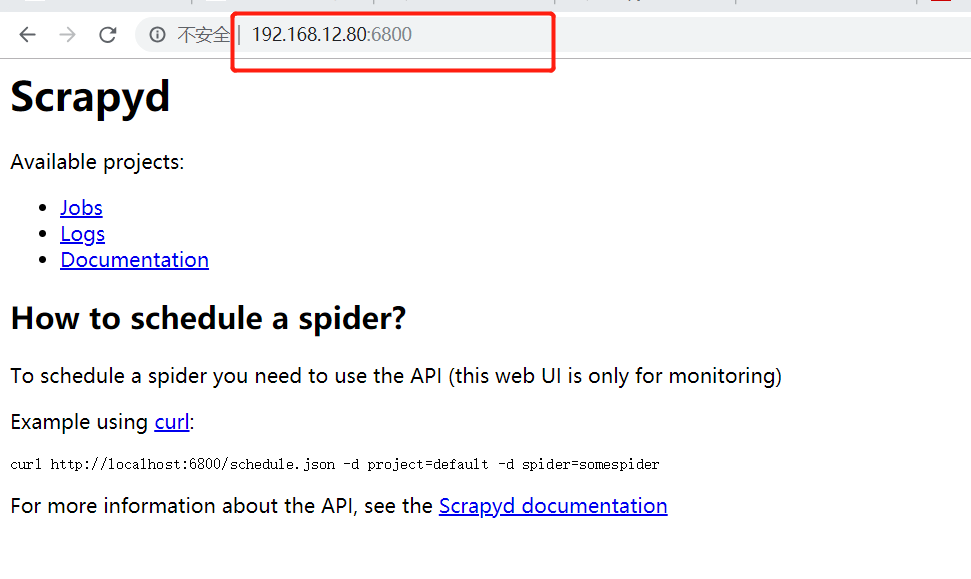
浏览器中访问:
192.168.12.80:6800
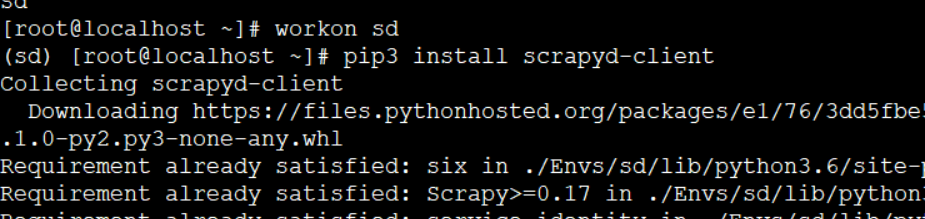
scrapyd-client 及部署
1. 安装scrapyd-client
pip3 install scrapyd-client
2.
安装成功后会有一个可用命令,叫作scrapyd-deploy,即部署命令。
我们可以输入如下测试命令测试Scrapyd-Client是否安装成功:
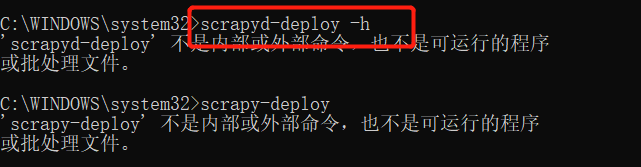
3. crapyd-deploy 不是内部命令,所以需要进行项目配置
windows下的scrapyd-deploy无法运行的解决办法
.进到c:/python/Scripts 目录下,创建两个新文件:
scrapy.bat
scrapyd-deploy.bat

编辑两个文件:
scrapy.bat文件中输入以下内容 :
@echo off
"C:\Python36" "C:\Python36\Scripts\scrapy" %*
scrapyd-deploy.bat 文件中输入以下内容:
@echo off
"C:\Python36\python" "C:\Python36\Scripts\scrapyd-deploy" %*
4.再次查看
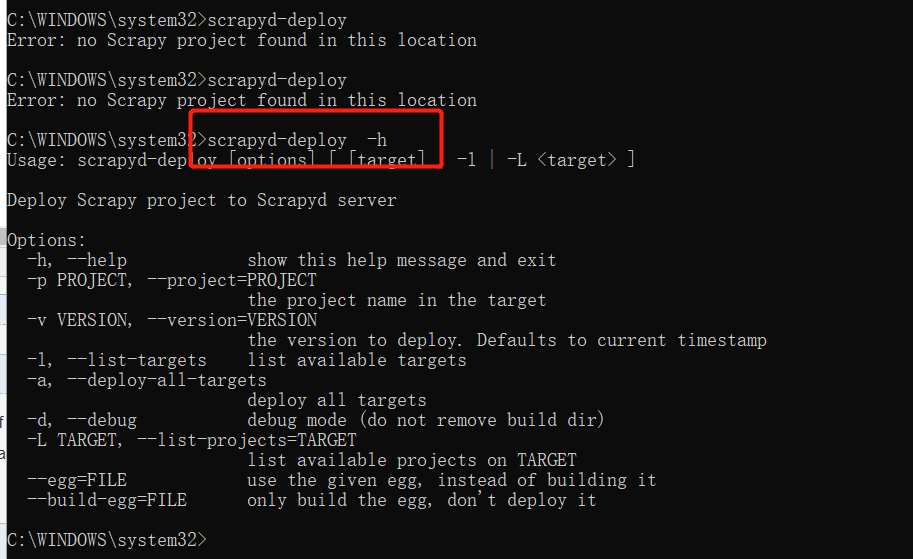
可以了。
scrapyd的安装和scrapyd-client的更多相关文章
- 芝麻HTTP:Scrapyd的安装
Scrapyd是一个用于部署和运行Scrapy项目的工具,有了它,你可以将写好的Scrapy项目上传到云主机并通过API来控制它的运行. 既然是Scrapy项目部署,基本上都使用Linux主机,所以本 ...
- scrapyd的安装
.安装 pip3 install scrapyd 二.配置 安装完毕之后,需要新建一个配置文件/etc/scrapyd/scrapyd.conf,Scrapyd在运行的时候会读取此配置文件. 在Scr ...
- 谷歌(Chrome)安装Advanced REST Client插件
进入Extensions(工具——>扩展程序) 点击Get More extensions或新建标签页点击网上应用店 如果加载太慢,出现chrome网上应用店无法打开,显示暂时无法加载该应用的画 ...
- 安装好Oracle Client以后没有tnsnames.ora文件
安装好Oracle Client以后没有tnsnames.ora文件 安装完Oracle Client以后,发现相应目录中没有tnsnames.ora文件,其实只要手动建立一个就可以了.在 oracl ...
- 如何安装Oracle Instant Client
Oracle Instant Client是Oracle发布的轻量级数据库客户端,下面我们来看看官方的定义: Instant Client allows you to run your applica ...
- CentOS 6.5安装TortoiseSVN svn client
TortoiseSVN: TortoiseSVN 是 Subversion 版本号控制系统的一个免费开源client,能够超越时间的管理文件和文件夹. 文件保存在中央版本号库,除了能记住文件和文件夹的 ...
- 安装java memcached client到本地maven repository
由于目前java memcached client没有官方的maven repository可供使用,因此使用时需要手动将其安装到本地repository.java memcached client的 ...
- CentOS-7.2安装SQuirreL SQL Client连接Hive
一,SQuirreL SQL Client干吗的? SQuirreL SQL Client是一款功能强大的服务器配置管理软件,该软件能够帮助用户快速.高效的配置服务器,且支持用户查看数剧库的结构并发出 ...
- PLSQLDeveloper_免安装自带client
PLSQLDeveloper_解压版 免安装并且自带有client客户端. 要安装解压附带的readme.txt进行配置. 一. 目录结构 D:\install\PLSQL |-- instantcl ...
随机推荐
- PHP filter_var 函数用法
先介绍下PHP Filter PHP手册地址:http://php.net/manual/zh/ref.filter.php PHP 过滤器用于对来自非安全来源的数据(比如用户输入)进行验证和过滤. ...
- C# 数组在内存中的存储
C# 数组是引用类型,那么在内存中是如何存储的呢? 在VS中调试C#程序,如何查看内存.寄存器.反汇编 在这篇文章里看到了如何在VS 中查看内存 先断点打在数组创建后语句那里,点debug->W ...
- 关于表格table嵌套,边框合并问题的解决方法,table嵌套(转)
原文地址:http://www.cnblogs.com/zhangym118/archive/2016/05/16/5496931.html [问题] 外层table与内层table嵌套,内外表格都需 ...
- react问题解决的一些方法
原文链接: https://segmentfault.com/a/1190000007811296?utm_source=tuicool&utm_medium=referral 初学者对Rea ...
- HTML学记笔记
<!DOCTYPE html><html lang="zh-CN"><head> <meta charset="UTF-8&qu ...
- [转载]ISO 8601规则
1.每年有52周或者53周2.周一至周日为一个完整周.3.每周的周一是该周的第1天.周日是该周的第7天4.每年的第一周 为 每年的第一个周四所在的周.比如 2017年1月5日为当年的第一个周四,那么 ...
- TeamCity 创建jar构建步骤
1 创建工程 2 配置工程代码来源信息 2.1 From a repository URL 表示从代码仓库创建工程. 2.1.1 parent project 指定父工程,默认是root projec ...
- vue/iview使用moment.js
方法一 main.js引入moment 获取当前时间 this.time = this.$moment()._d; // 当前时间 this.time0 =this.$moment().subtrac ...
- 使用littleTools简化docker/kubectl的命令
littleTools littleTools是我根据日常运维时编写的一个小工具,开源在了https://github.com/xuxinkun/littleTools上. littleTools包含 ...
- 为input标签绑定事件的几种方式
为input标签绑定事件的几种方式 1.JavaScript原生态的方式,直接复制下面的代码就会有相应的效果 <!DOCTYPE html><html><head> ...