Python学习:列表、元组、字典、集合
转载:https://www.cnblogs.com/xc-718/p/9632942.html
- 列表/元组
列表和元组都是序列结构,它们本身很相似,但又有一点不同;
列表是用方括号标记,如:a=[1,2,3] 列表可以被修改



remove:按照元素删除
li = ['xcsd', 'cdc', [1, 5, 2], 'eht', '辛辰']
li.remove('xcsd')
print(li) #['cdc', [1, 5, 2], 'eht', '辛辰']
元组是用圆括号标记,如:b=(4,5,6) 元组是只读列表,只能查询;儿子不能改,孙子是列表则可以改;只有一个元素,不加逗号,是原数据类型;否则是元祖类型
如:
1 tu1 = (1)
2 tu2 = (1,)
3 print(tu1,type(tu1)) #1 <class 'int'>
4 print(tu2,type(tu2)) #(1,) <class 'tuple'>
5
6 tu3 = ([1])
7 tu4 = ([1],)
8 print(tu3,type(tu3)) #[1] <class 'list'>
9 print(tu4,type(tu4)) #([1],) <class 'tuple'>
元组的基本操作

tu = (1,2,3,'alex',[2,3,4,'xxcc'],'egon')
print(tu[2]) #3
print(tu[0:4]) #(1, 2, 3, 'alex')
for i in tu:
print(i) #循环打印元祖
tu[4][3] = tu[4][3].upper() #把xxcc改为大写
print(tu) #(1, 2, 3, 'alex', [2, 3, 4, 'XXCC'], 'egon')
tu[4].append('sb') #在xcxc后面增加sb
print(tu) #(1, 2, 3, 'alex', [2, 3, 4, 'XXCC', 'sb'], 'egon')
tu[4].insert(4,'bs') #在元组的索引为4的元素列表的索引为4的地方添加bs
print(tu) #(1, 2, 3, 'alex', [2, 3, 4, 'XXCC', 'bs', 'sb'], 'egon')
tu[4].extend('xc') #在元组的索引为4的元素列表中迭代增加xc
print(tu) #(1, 2, 3, 'alex', [2, 3, 4, 'XXCC', 'sb', 'bs', 'x', 'c'], 'egon')
其他常用操作
(1)split:字符串转换成列表 str--->list
s = 'xcsd_cdc_eht_辛辰'
print(s.split('_')) #['xcsd', 'cdc', 'eht', '辛辰']
s1 = 'xc sdc dc eht辛 辰'
print(s1.split(' ')) #['xc', 'sdc', 'dc', 'eht辛', '辰']
(2)join:列表转换成字符串 list--->str
join(可迭代对象iterable) split
可迭代对象iterable:list,str,元祖
li = ['xcsd', 'cdc', 'eht', '辛辰']
s = ''.join(li)
print(s) #xcsdcdceht辛辰
s1 = '_'.join(li)
print(s1) #xcsd_cdc_eht_辛辰
(3)range:顾头不顾尾——相当于有序的数字列表(可以反向,加步长)
for i in range(2,6):
print(i)
for i in range(3): #从0开始,0可省略
print(i)
for i in range(1,10,2): #起始,截至,步长
print(i)
for i in range(10,0,-2): #倒着打印输出
print(i) #笔试题:成功运行,不输出任何结果,不报错
for i in range(0,10,-1):
print(i)
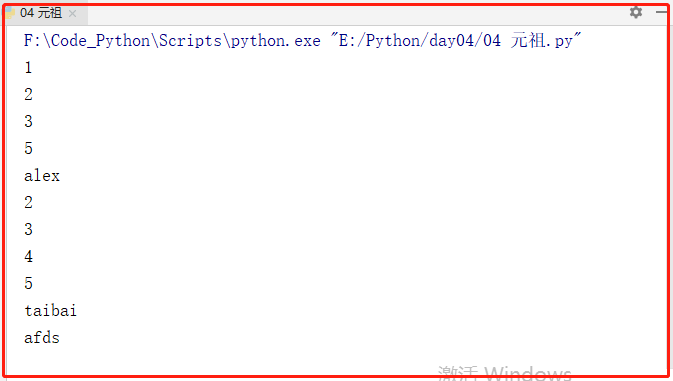
应用实例:
#Q&A:循环打印,列表里遇到列表也需要循环打印
li = [1,2,3,5,'alex',[2,3,4,5,'taibai'],'afds']
for i in li:
if type(i) == list:
for n in i:
print(n)
else:
print(i)
运行结果:
- 字典

1. 定义
(1)数据类型划分:
可变(不可哈希)数据类型 : list,dict,set,
不可变(可哈希)数据类型 : 元祖,bool,int,str,
(2)dict
key(键)必须是不可变数据类型,可哈希
value(值)任意数据类型
(3)dict 优点:二分查找去查询
存储大量的关系型数据
(4)特点:<=3.5版本无序,3.6以后都是有序
2. 增
(1)dic['键'] = 值
dic1 = {'age':18,'name':'xc','sex':'female'}
dic1['height'] = 165
print(dic1) #没有键值对,增加--{'age': 18, 'name': 'xc', 'sex': 'female', 'height': 165}
dic1['age'] = 21
print(dic1) #有键值对,则修改--{'age': 21, 'name': 'xc', 'sex': 'female', 'height': 165}
(2)setdefault
dic1 = {'age':18,'name':'xc','sex':'female'}
dic1.setdefault('weight',120)
print(dic1) #没有键值对,增加--{'age': 18, 'name': 'xc', 'sex': 'female', 'weight': 120}
dic1.setdefault('name','aa')
print(dic1) #有键值对,不做任何操作--{'age': 18, 'name': 'xc', 'sex': 'female', 'weight': 120}
3. 删
删除优先使用pop(有返回值,要删除的内容不存在时不报错),而不是del
(1) pop
dic1 = {'age':18,'name':'xc','sex':'female'}
print(dic1.pop('age')) #有age直接删除---有返回值,按键删除
print(dic1) #18 {'name': 'xc', 'sex': 'female'}
print(dic1.pop('erge','没有此键/None')) #没有erge----可设置返回值:没有此键/None
print(dic1) #没有此键/None {'name': 'xc', 'sex': 'female'}
(2) popitem
dic1 = {'age':18,'name':'xc','sex':'female'}
print(dic1.popitem()) #('sex', 'female')
#随机删除:有返回值-----返回元祖:删除的键值
(3) clear
dic1 = {'age':18,'name':'xc','sex':'female'}
dic1.clear() #清空元祖
print(dic1) #{}
(4) del
dic1 = {'age':18,'name':'xc','sex':'female'}
del dic1['name'] #有,则删除
# del dic1['name1'] #没有,则报错
print(dic1) #{'age': 18, 'sex': 'female'}
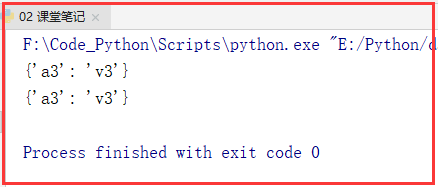
应用实例:
#dict:删除键中有k的键和值
dic = {'k1':'v1','k2':'v2','a3':'v3'}
# (1)
dic1 = {}
for i in dic:
if 'k' not in i:
dic1.setdefault(i,dic[i])
print(dic1)
dic = dic1
print(dic)
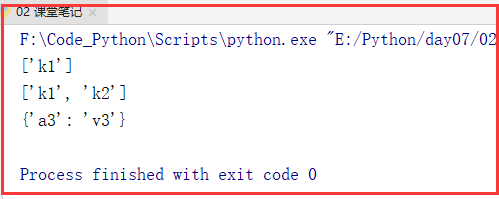
# (2)
l = []
for i in dic:
if 'k' in i:
l.append(i)
print(l)
for k in l:
del dic[k]
print(dic)
运行结果:
4. 改
dic = {'age':18,'name':'xc','sex':'female'}
dic2 = {'name':'alex','weight':'168'}
dic2.update(dic) #有则更新覆盖,没有则增加
print(dic) #{'age': 18, 'name': 'xc', 'sex': 'female'}
print(dic2) #{'name': 'xc', 'weight': '168', 'age': 18, 'sex': 'female'}
5. 查------得到键值,首选get
dic1 = {'age':18,'name':'xc','sex':'female'}
print(dic1.keys(),type(dic1.keys())) #键
print(dic1.values()) #值
print(dic1.items()) #元祖[(‘键’,值),(‘键’,值),(‘键’,值)]
# 得到键值,首选get
print(dic1['name']) #有则打印
#print(dic1['name1']) #没有则报错
print(dic1.get('name')) #有name直接输出---有返回值
print(dic1.get('name1','没有此键')) #没有name1----可设置返回值:没有此键/None
for i in dic1:
print(i) #循环打印键(默认为键)
for i in dic1.keys():
print(i) #循环打印键
for i in dic1.values():
print(i) #循环打印值
for i in dic1.items():
print(i) #循环打印键值对
for k,v in dic1.items():
print(k,v) #打印键和值
6. 字典的嵌套
dic = {
'name':['alex','wusir','xinchen'],
'py9':{
'time':'1213',
'study_fee':19800,
'addr':'CBD',
},
'age':21
}
dic['age'] = 56 #找到age,再更新为56
print(dic)
dic['name'].append('rt') #找到name,在添加名字
print(dic)
dic['name'][1] = dic['name'][1].upper() #找到name,再把wusir变为大写
print(dic)
dic['py9']['female'] = 6 #找到元祖,增加键值对female:6
print(dic)
应用实例:
#输入一串字符,遇到字母,转换为‘_’,并打印输出
info = input('请输入:')
for i in info:
if i.isalpha():
info = info.replace(i,'_')
print(info)
运行结果:

- 集合

1. 定义
集合:可变的数据类型,里面的元素必须是不可变的数据类型
无序----每次运行结果都不一定一样
不重复----列表去重:先转换为集合,再转换成列表即可
set1 = set({1,2,3})
print(set1) #{1, 2, 3}
set2 = {1,2,3,[2,3],{'name':'xc'}} #列表是可变的(不可哈希),所以出错
print(set2) #TypeError: unhashable type: 'list'
2. 基本操作
(1)增
set1 = {'alex','wusir','ritian','egon','barry'}
# (1)add #因为集合是无序的,所以每次运行结果不一定一样,增加的位置也不一定一样
set1.add('nvshen') #{'ritian', 'nvshen', 'egon', 'wusir', 'alex', 'barry'}
print(set1)
# (2)update
set1.update('xc') #迭代添加,依然是无序的
print(set1) #{'egon', 'x', 'wusir', 'nvshen', 'c', 'alex', 'ritian', 'barry'}
(2)删
set1 = {'alex','wusir','ritian','egon','barry'}
#(1)pop--随机删除
print(set1.pop()) #egon:有返回值,返回本次删除的内容
print(set1) #{'barry', 'alex', 'wusir', 'ritian'}
#(2)remove——指定元素删除
set1.remove('alex')
print(set1) #{'egon', 'wusir', 'barry', 'ritian'}
#(3)clear--清空
set1.clear()
print(set1) #空集合:set()
#(4)del
del set1 #删除之后集合不存在,报错
print(set1) #NameError: name 'set1' is not defined
(3)不能改
无序;
集合中的元素是不可变数据类型
(4)查
set1 = {'alex','wusir','ritian','egon','barry'}
for i in set1:
print(i)
运行结果:

(5)集合之间的操作
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
#交集
print(set1 & set2) #(1) {4, 5}
print(set1.intersection(set2)) #(2) {4, 5}
#并集
print(set1 | set2) #(1) {1, 2, 3, 4, 5, 6, 7, 8}
print(set1.union(set2)) #(2) {1, 2, 3, 4, 5, 6, 7, 8}
#反交集--除交集以外的其他元素
print(set1 ^ set2) #(1) {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) #(2) {1, 2, 3, 6, 7, 8}
#差集--前者独有的
print(set1 - set2) #(1) {1, 2, 3}
print(set1.difference(set2)) #(2) {1, 2, 3}
print(set2 - set1) #(1) {8, 6, 7}
print(set2.difference(set1)) #(2) {8, 6, 7}
#子集与超集
set3 = {1,2,3,4,5}
set4 = {1,2,3,4,5,6,7,8}
print('------ set3是set4的子集 ------')
print(set3 < set4) #True
print(set3.issubset(set4)) #True
print('------ set4是set3的超集 ------')
print(set4 > set3) #True
print(set4.issuperset(set3)) #True
(6)frozenset
#将set(可变数据类型)转换为不可变数据类型(只读)
s1 = set('nvshen')
print(s1,type(s1)) #{'s', 'h', 'n', 'v', 'e'} <class 'set'>
s = frozenset('nvshen')
print(s,type(s)) #frozenset({'h', 'n', 's', 'v', 'e'}) <class 'frozenset'>
for i in s:
print(i) #可以循环打印(只读),但不能增加修改删除
公共方法
(1)排序
a. 正向排序:sort()
li = [1,5,4,2,6,7,3]
li.sort()
print(li) #[1, 2, 3, 4, 5, 6, 7]
b. 倒序排序:li.sort(reverse = True).()
li = [1,5,4,2,6,7,3]
li.sort(reverse = True)
print(li) #[7, 6, 5, 4, 3, 2, 1]
c. 反转:li.reverse()
li = [1,5,4,2,6,7,3]
li.reverse()
print(li) #[3, 7, 6, 2, 4, 5, 1]
d. 补充:字符串列表排序——根据字符串的第一个字符对应的ASCII码排序
li = ['ojhy','asa','cvd','hdk']
li.sort()
print(li) #['asa', 'cvd', 'hdk', 'ojhy']
(2) count() 数元素出现的次数
li = ['xcsd', 'cdc', '辛辰',[1, 5, 2], 'eht', '辛辰']
num = li.count('辛辰')
print(num) #2:'辛辰'出现2次
(3)len() 计算列表的长度
li = ['xcsd', 'cdc', '辛辰',[1, 5, 2], 'eht', '辛辰']
l = len(li)
print(l) #6:列表长度为6
(4)li.index('元素') 查看索引
li = ['xcsd', 'cdc', '辛辰',[1, 5, 2], 'eht', '辛辰']
print(li.index('eht')) #4:'eht'的索引为4元祖
Python学习:列表、元组、字典、集合的更多相关文章
- python中列表 元组 字典 集合的区别
列表 元组 字典 集合的区别是python面试中最常见的一个问题.这个问题虽然很基础,但确实能反映出面试者的基础水平. (1)列表 什么是列表呢?我觉得列表就是我们日常生活中经常见到的清单.比如,统计 ...
- **python中列表 元组 字典 集合
列表 元组 字典 集合的区别是python面试中最常见的一个问题.这个问题虽然很基础,但确实能反映出面试者的基础水平. 1.列表 列表是以方括号“[]”包围的数据集合,不同成员以“,”分隔. 列表的特 ...
- python 中列表 元组 字典 集合的区别
先看图片解释 (1)列表 什么是列表呢?我觉得列表就是我们日常生活中经常见到的清单.比如,统计过去一周我们买过的东西,把这些东西列出来,就是清单.由于我们买一种东西可能不止一次,所以清单中是允许有重复 ...
- Python学习-列表元组字典操作
一.列表 列表是Python的基本数据类型之一,它是以 [] 括起来的,内部成员用逗号隔开.里面可以存放各种数据类型. # 例如: list2 = ['jason', 2, (1, 3), ['war ...
- Python入门基础学习(列表/元组/字典/集合)
Python基础学习笔记(二) 列表list---[ ](打了激素的数组,可以放入混合类型) list1 = [1,2,'请多指教',0.5] 公共的功能: len(list1) #/获取元素 lis ...
- Python学习---列表/元组/字典/字符串/set集合/深浅拷贝1207【all】
1.列表 2.元组 3.字典 4.字符串 5.set集合 6.深浅拷贝
- python的列表元组字典集合比较
定义 方法 列表 可以包含不同类型的对象,可以增减元素,可以跟其他的列表结合或者把一个列表拆分,用[]来定义的 eg:aList=[123,'abc',4.56,['inner','list'],7- ...
- python3笔记十八:python列表元组字典集合文件操作
一:学习内容 列表元组字典集合文件操作 二:列表元组字典集合文件操作 代码: import pickle #数据持久性模块 #封装的方法def OptionData(data,path): # ...
- python_列表——元组——字典——集合
列表——元组——字典——集合: 列表: # 一:基本使用# 1.用途:存放多个值 # 定义方式:[]内以逗号为分隔多个元素,列表内元素无类型限制# l=['a','b','c'] #l=list([' ...
- python的学习笔记01_4基础数据类型列表 元组 字典 集合 其他其他(for,enumerate,range)
列表 定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素 特性: 1.可存放多个值 2.可修改指定索引位置对应的值,可变 3.按照从左到右的顺序定义列表元素,下标从0开始顺序访问 ...
随机推荐
- 提示Unused default export错误,如何解决
问题描述如下: 这个错误提示其实是webstorm的变量语法检查提示,修改一下它的配置就好了. 1.点击Webstorm右下角的小人,点击Configure inspections 2.在搜索框中输入 ...
- python3 操作配置文件
一 json文件 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. JSON采用完全独立于语言的文本格式,但是也使用 ...
- dos脚本1章
第一节 常用批处理内部命令简介 批处理定义:顾名思义,批处理文件是将一系列命令按一定的顺序集合为一个可执行的文本文件,其扩展名为BAT或者CMD.这些命令统称批处理命令.小知识:可以在键盘上按下Ctr ...
- sql注入1
一.函数 1.version() MYsql版本 2.user() 数据库用户名 3.database() 数据库名 4.@@datadir 数据库路径 5.@@version_compi ...
- 虚拟机中ubuntu不能联网问题的解决——NAT方式
困惑我多时的Ubuntu联网问题终于解决啦,开心!!!现记录如下,方便日后取用. 可先直接尝试第3步,若不行,则走完全程. 1.查看/设置下NAT的网络 打开VMware Workstation, 点 ...
- Java中语法与C/CPP的区别
static不能在成员方法中定义,只能作为类变量定义.
- 天转凉了,注意保暖,好吗(需求规格说明书放在github了)
团队项目——AI五子棋(小程序) 一.团队展示: 队名:未来的将来的明天在那里等你 小组 队员: 龙天尧(队长)(3116005190),林毓植(3116005188),黄晖朝(3116005178) ...
- C#参考教程 http://www.csref.cn
推荐 C#参考教程 http://www.csref.cn
- 《HTTP权威指南》读书笔记(二) :URL与资源
1.URL是什么 URL就是因特网资源的标准化名称.URL指向一条电子信息片段,告诉你它们位于何处,以及如何与之交互.通俗来说,就是浏览器寻找信息所需的资源位置. URI是一类更通用的资源标识符,UR ...
- JMeter在linux服务器上使用
环境部署: 1.在Linux服务器先安装jdk:此步骤省略,可参考百度经验:https://jingyan.baidu.com/article/6b18230980c294ba59e15967.htm ...