image-to-image translation with conditional adversarial networks文献笔记
Image-to-Image Translation with Conditional Adversarial Networks
(基于条件gan的图像转图像)
作者:Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
全文链接:https://arxiv.org/abs/1611.07004
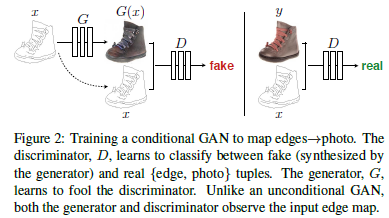
GANs是一种生成模型,它学习从随机噪声向量z到输出图像y的映射。条件GAN学习从观测图像x和随机噪声向量z到y的映射。生成器G经过训练后产生的输出不能通过反向训练的判别器D从“真实”图像中分辨出来,D经过训练以尽可能好地检测生成的“赝品”。这个训练过程如图2所示。
条件GAN的目标可以表示为:

在对抗中,G试图将这个目标最小化,D试图使它最大化,G* = arg minG maxD LcGAN(G;D).
鉴别器的工作保持不变,但生成器的任务不仅是欺骗鉴别器,而且在L2意义上接近真值输出。基于这个需求,使用L1距离而不是L2作为参数。L1鼓励减少模糊。
目标函数变为:
生成器和鉴别器都使用卷积-BN处理- relu格式的模块。Pix2pix网络能够让图像和目标图像的像素值一一对应。
生成器采用Unet结构,跳层连接的方式。

马尔可夫链的鉴别器(PatchGAN):给高频信息更高的关注,关注局部图像块。将判别器设计为对块进行单独判别的结构。判别器对于每张图片的判断,都将图片分割为N*N的块,判断这个N*N的图形块是生成的图形或者是真实图像。我们通过对图像进行卷积来运行这个鉴别器,对所有响应进行平均,从而得到D的最终输出。一个较小的PatchGAN的参数更少,运行速度更快,可以应用于任意大的图像。
假设像素之间的独立距离大于一个patch的直径,这种鉴别器可以有效地将图像建模为一个马尔可夫随机场。
为了优化网络,遵循标准方法:在D上的梯度下降步骤和G上的梯度下降步骤之间交替进行。
image-to-image translation with conditional adversarial networks文献笔记的更多相关文章
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 阅读笔记
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (使用循环一致的对抗网络的非配对图像-图 ...
- (Pixel2PixelGANs)Image-to-Image translation with conditional adversarial networks
Introduction 1. develop a common framework for all problems that are the task of predicting pixels f ...
- 《Image-to-Image Translation with Conditional Adversarial Networks》论文笔记
出处 CVPR2017 Motivation 尝试用条件GAN网络来做image translation,让网络自己学习图片到图片的映射函数,而不需要人工定制特征. Introduction 作者从不 ...
- 《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》论文笔记
Code Address:https://github.com/junyanz/CycleGAN. Abstract 引出Image Translating的概念(greyscale to color ...
- CIAGAN: Conditional Identity Anonymization Generative Adversarial Networks阅读笔记
CIAGAN: Conditional Identity Anonymization Generative Adversarial Networks 2020 CVPR 2005.09544.pdf ...
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks(使用循环一致的敌对网络进行不成对的图像到图像转换)
作者:朱俊彦,朱俊彦博士是计算机图形学领域现代机器学习应用的开拓者.他的论文可以说是第一篇用深度神经网络系统地解决自然图像合成问题的论文.因此,他的研究对这个领域产生了重大影响.他的一些科研成果,尤其 ...
- CycleGAN --- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
文章地址:http://openaccess.thecvf.com/content_ICCV_2017/papers/Zhu_Unpaired_Image-To-Image_Translation_I ...
- 语音合成论文翻译:2019_MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
论文地址:MelGAN:条件波形合成的生成对抗网络 代码地址:https://github.com/descriptinc/melgan-neurips 音频实例:https://melgan-neu ...
随机推荐
- Windows 环境下进行的jenkins持续集成
一台服务器作为代码仓库,一条服务器做持续集成代码仓库目前常见的github.gitlab.gitee持续集成常用Jenkins 服务器的配置这边都以Windows为例进行介绍 1. 安装Jenkins ...
- R语言 重命名目录下所有文件
myfilepath <- "F:/paper2/climateExposure/wjj_mec/second/paths/" setwd(myfilepath) allty ...
- 又谈T检验
今天有同学的论文被指摘了,就是又用了T检验,又用了ANOVA,reviewer直接说用ANOVA就行了.所以回想下了T检验. 简而言之,T检验就是用来比较均值的,样本均值和已知总体均值是否有差异.(也 ...
- Flutter工程无法找到Android真机或Android模拟器
之前的Flutter的工程链接真机还好好的 结果电脑抽抽了过了个年就连不到真机了 一点run就提示 No connected devices found; please connect a devic ...
- 正向代理or反向代理
正向代理 我访问不了某网站比如www.google.com,但是我能访问一个代理服务器 这个代理服务器呢,它能访问那个我不能访问的网站,于是我先连上代理服务器,告诉它我需要那个无法访问网站的内容,代理 ...
- python-文件读写
python对文件的操作对文件操作的步骤:1.打开文件2.读写文件3.关闭文件 一.读取文件的方法有三种:read(),readline(),readlines()f.readline() #每次读出 ...
- web service 上传file说明
之前做过一个接口,PI发布WEB SERVICE给对方调,传附件到SAP... 接口中包含文件名称,文件类型,文件流... 1.SOAPUI新建项目: 文件内容的地方会自动带上一个ID,这个ID对应文 ...
- centos6.0和7.4默认网卡配置
6.0 vim /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0" NM_CONTROLLED="yes&qu ...
- thymeleaf下拉框从后台动态获取集合数据并回显选中
今天遇到从后台集合中取出对象在前台页面下拉列表展示: <select name="signature" lay-search="" class=" ...
- 记录Datagrid使用的一些事项
1.将两个列的文本拼接到一起并显示,如列1为name,列2为code,需要显示name(code).如:小明(123) 则初始化datagrid时在columns[]里加入:列1添加formatter ...