Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理)
Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理)
http://xiguada.org/spark-shuffle-direct-buffer-oom/
问题描述
Spark-1.6.0已经在一月份release,为了验证一下它的性能,我使用了一些大的SQL验证其性能,其中部分SQL出现了Shuffle失败问题,详细的堆栈信息如下所示:
16/02/17 15:36:36 WARN server.TransportChannelHandler: Exception in connection from /10.196.134.220:7337
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306)
at io.netty.buffer.PoolArena$DirectArena.newChunk(PoolArena.java:645)
at io.netty.buffer.PoolArena.allocateNormal(PoolArena.java:228)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:212)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:132)
at io.netty.buffer.PooledByteBufAllocator.newDirectBuffer(PooledByteBufAllocator.java:271)
at io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:155)
at io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:146)
at io.netty.buffer.AbstractByteBufAllocator.ioBuffer(AbstractByteBufAllocator.java:107)
at io.netty.channel.AdaptiveRecvByteBufAllocator$HandleImpl.allocate(AdaptiveRecvByteBufAllocator.java:104)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:117)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
at java.lang.Thread.run(Thread.java:744)
从失败信息可以看出,是堆外内存溢出问题,为什么会出现堆外内存溢出呢?
Spark的shuffle部分使用了netty框架进行网络传输,但netty会申请堆外内存缓存(PooledByteBufAllocator ,AbstractByteBufAllocator);Shuffle时,每个Reduce都需要获取每个map对应的输出,当一个reduce需要获取的一个map数据比较大(比如1G),这时候就会申请一个1G的堆外内存,而堆外内存是有限制的,这时候就出现了堆外内存溢出。
Shuffle不使用堆外内存
为Executor增加配置-Dio.netty.noUnsafe=true,就可以让shuffle不使用堆外内存,但相同的作业还是出现了OOM,这种方式没办法解决问题。
java.lang.OutOfMemoryError: Java heap space
at io.netty.buffer.PoolArena$HeapArena.newUnpooledChunk(PoolArena.java:607)
at io.netty.buffer.PoolArena.allocateHuge(PoolArena.java:237)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:215)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:132)
at io.netty.buffer.PooledByteBufAllocator.newHeapBuffer(PooledByteBufAllocator.java:256)
at io.netty.buffer.AbstractByteBufAllocator.heapBuffer(AbstractByteBufAllocator.java:136)
at io.netty.buffer.AbstractByteBufAllocator.heapBuffer(AbstractByteBufAllocator.java:127)
at io.netty.buffer.CompositeByteBuf.allocBuffer(CompositeByteBuf.java:1347)
at io.netty.buffer.CompositeByteBuf.consolidateIfNeeded(CompositeByteBuf.java:276)
at io.netty.buffer.CompositeByteBuf.addComponent(CompositeByteBuf.java:116)
at org.apache.spark.network.util.TransportFrameDecoder.decodeNext(TransportFrameDecoder.java:148)
at org.apache.spark.network.util.TransportFrameDecoder.channelRead(TransportFrameDecoder.java:82)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:308)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:294)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:846)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:131)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
当数据量大时能否直接写磁盘
MapReduce中Shuffle数据量大时,会把Shuffle数据写到磁盘。
Spark Shuffle通信机制
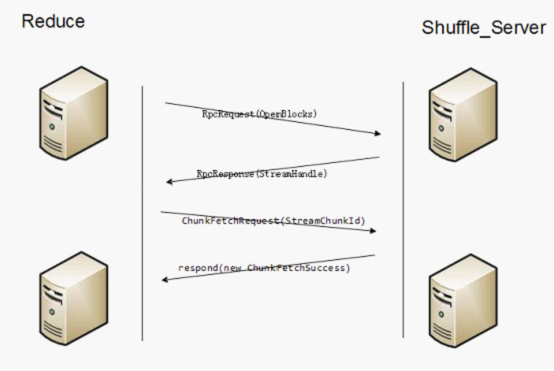
上图显示了Shuffle的通信原理。
服务端会启动Shuffle_Service。
(1)客户端代码调用堆栈
BlockStoreShuffleReader.read
ShuffleBlockFetcherIterator.sendRequest
ExternalShuffleClient.fetchBlocks
OneForOneBlockFetcher.start
TransportClient.sendRpc
发送RpcRequest(OpenBlocks)信息
(2)服务端代码调用堆栈
TransportRequestHandler.processRpcRequest
ExternalShuffleBlockHandler.receive
ExternalShuffleBlockHandler.handleMessage
ExternalShuffleBlockResolver.getBlockData(shuffle_ShuffleId_MapId_ReduceId)
ExternalShuffleBlockResolver.getSortBasedShuffleBlockData
FileSegmentManagedBuffer
handleMessage会把所需的appid的一个executor需要被fetch的block全部封装成List<ManagedBuffer>,然后注册为一个Stream,然后把streamId和blockid的个数返回给客户端,最后返回给客户端的信息为RpcResponse(StreamHandle(streamId, msg.blockIds.length))。
(3)客户端
客户端接收到RpcResponse后,会为每个blockid调用:
TransportClient.fetchChunk
Send ChunkFetchRequest(StreamChunkId(streamId, chunkIndex))
(4)服务端
TransportRequestHandler.processFetchRequest
OneForOneStreamManager.getChunk
返回respond(new ChunkFetchSuccess(req.streamChunkId, buf))给客户端,buf就是某一个blockid的FileSegmentManagedBuffer。
(5)客户端
OneForOneBlockFetcher.ChunkCallback.onSuccess
listener.onBlockFetchSuccess(blockIds[chunkIndex], buffer)
ShuffleBlockFetcherIterator.sendRequest.BlockFetchingListener.onBlockFetchSuccess
results.put(new SuccessFetchResult(BlockId(blockId), address, sizeMap(blockId), buf))
客户端的另外一个线程
ShuffleBlockFetcherIterator.next
(result.blockId, new BufferReleasingInputStream(buf.createInputStream(), this))
Download文件的通信原理
另外还有一个stream通信协议,客户端首先需要构造StreamRequest请求,StreamRequest中包含待下载文件的URL。
(1)客户端调用堆栈
Executor.updateDependencies...
org.apache.spark.util.Utils.fetchFile
org.apache.spark.util.Utils.doFetchFile
NettyRpcEnv.openChannel
TransportClient.stream
Send StreamRequest(streamId) streamId为文件的目录。
(2)服务端处理流程
TransportRequestHandler.handle
TransportRequestHandler.processStreamRequest
OneForOneStreamManager.openStream
返回new StreamResponse(req.streamId, buf.size(), buf)
(3)客户端处理流程
TransportResponseHandler.handle
TransportFrameDecoder.channelRead
TransportFrameDecoder.feedInterceptor
StreamInterceptor.handle
callback.onData即NettyRpcEnv.FileDownloadCallback.onData
然后返回client.stream(parsedUri.getPath(), callback)给Utils.doFetchFile,最后org.apache.spark.util.Utils.downloadFile
问题分析:
当前spark shuffle时使用Fetch协议,由于使用堆外内存存储Fetch的数据,当Fetch某个map的数据特别大时,容易出现堆外内存的OOM。而申请内存部分在Netty自带的代码中,我们无法修改。
另外一方面,Stream是下载文件的协议,需要提供文件的URL,而Shuffle只会获取文件中的一段数据,并且也不知道URL,因此不能直接使用Stream接口。
解决方案:
新增一个FetchStream通信协议,在OneForOneBlockFetcher中,如果一个block小于100M(spark.shuffle.max.block.size.inmemory)时,使用原有的方式Fetch数据,如果大于100M时,则使用新增的FetchStream协议,服务端在处理FetchStreamRequest和FetchRequest的区别在于,FetchStreamRequest返回数据流,客户端根据返回的数据量写到本地临时文件,然后构造FileSegmentManagedBuffer给后续处理流程。
Spark Shuffle 堆外内存溢出问题与解决(Shuffle通信原理)的更多相关文章
- Java堆外内存之六:堆外内存溢出问题排查
一.堆外内存组成 通常JVM的参数我们会配置 -Xms 堆初始内存 -Xmx 堆最大内存 -XX:+UseG1GC/CMS 垃圾回收器 -XX:+DisableExplicitGC 禁止显示GC -X ...
- Java堆外内存管理
Java堆外内存管理 1.JVM可以使用的内存分外2种:堆内存和堆外内存: 堆内存完全由JVM负责分配和释放,如果程序没有缺陷代码导致内存泄露,那么就不会遇到java.lang.OutOfMemo ...
- Java堆外内存之三:堆外内存回收方法
一.JVM内存的分配及垃圾回收 对于JVM的内存规则,应该是老生常谈的东西了,这里我就简单的说下: 新生代:一般来说新创建的对象都分配在这里. 年老代:经过几次垃圾回收,新生代的对象就会放在年老代里面 ...
- JVM源码分析之堆外内存完全解读
JVM源码分析之堆外内存完全解读 寒泉子 2016-01-15 17:26:16 浏览6837 评论0 阿里技术协会 摘要: 概述 广义的堆外内存 说到堆外内存,那大家肯定想到堆内内存,这也是我们 ...
- 【Spark篇】---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优
一.前述 Spark中调优大致分为以下几种 ,代码调优,数据本地化,内存调优,SparkShuffle调优,调节Executor的堆外内存. 二.具体 1.代码调优 1.避免创建重复的RDD,尽 ...
- 从内存泄露、内存溢出和堆外内存,JVM优化参数配置参数
内存泄漏 内存泄漏是指程序在申请内存后,无法释放已申请的内存空间,无用对象(不再使用的对象)持续占有内存或无用对象的内存得不到及时释放,从而造成内存空间的浪费.内存泄漏最终会导致OOM. 造成内存泄漏 ...
- [转]perftools查看堆外内存并解决hbase内存溢出
最近线上运行的hbase发现分配了16g内存,但是实际使用了22g,堆外内存达到6g.感觉非常诡异.堆外内存用一般的工具很难查看,可以通过google-perftools来跟踪: http://cod ...
- perftools查看堆外内存并解决hbase内存溢出
最近线上运行的hbase发现分配了16g内存,但是实际使用了22g,堆外内存达到6g.感觉非常诡异.堆外内存用一般的工具很难查看,可以通过google-perftools来跟踪: http://cod ...
- spark-调节executor堆外内存
什么时候需要调节Executor的堆外内存大小? 当出现一下异常时: shuffle file cannot find,executor lost.task lost,out of memory 出现 ...
随机推荐
- AC日记——红色的幻想乡 洛谷 P3801
红色的幻想乡 思路: 线段树+容斥原理: 代码: #include <bits/stdc++.h> using namespace std; #define maxn 100005 #de ...
- mac 远程桌面连接分享
mac 远程桌面连接分享 8.0版本 https://pan.baidu.com/s/1wgVvAmQreGwYZAhLST764w 10.0版本 https://pan.baidu.com/s/1Y ...
- 定位所用的class
方案 为解决类冲突,我们可以使用下述的方案定位一个class所在的位置 ClassName. package cn.j2se.junit.classpath; import static org.ju ...
- 31、Flask实战第31天:cms后台修改密码
cms后台修改密码界面布局 先创建cms_resetpwd.html页面,继承cms_base.html {% extends 'cms/cms_base.html' %} {% block titl ...
- 计算机基础-day3
网络基础 什么是互联网协议? 互联网协议是计算机网络中为进行数据交换而建立的规则.标准或约定的集合,其定义了计算机如何接入internet,以及接入internet的计算机间通信的一系列统一标准, 为 ...
- JZYZOJ 1385 拉灯游戏 状态压缩 搜索
http://172.20.6.3/Problem_Show.asp?id=1385 刚开始想的时候一直以为同一排不同的拉灯顺序对结果是有影响的,手推了好多遍才发现拉灯结果只和拉的灯有关,这也要打 ...
- 【线性基】hdu3949 XOR
给你n个数,问你将它们取任意多个异或起来以后,所能得到的第K小值? 求出线性基来以后,化成简化线性基,然后把K二进制拆分,第i位是1就取上第i小的简化线性基即可.注意:倘若原本的n个数两两线性无关,也 ...
- 【分块】【树套树】bzoj2141 排队
考虑暴力更新的情况,设swap的是L,R位置的数.swap之后的逆序对数应该等于:之前的逆序对数+[L+1,R-1]中比 L位置的数 大的数的个数-[L+1,R-1]中比 L位置的数 小的数的个数-[ ...
- bzoj 4602: [Sdoi2016]齿轮
4602: [Sdoi2016]齿轮 Description 现有一个传动系统,包含了N个组合齿轮和M个链条.每一个链条连接了两个组合齿轮u和v,并提供了一个传动比x : y.即如果只考虑这两个组合 ...
- [PKUSC2018]最大前缀和
[PKUSC2018]最大前缀和 题目大意: 有\(n(n\le20)\)个数\(A_i(|A_i|\le10^9)\).求这\(n\)个数在随机打乱后最大前缀和的期望值与\(n!\)的积在模\(99 ...