利用haohedi ETL将数据库中的数据抽取到hadoop Hive中
采用HIVE自带的apache 的JDBC驱动导入数据基本上只能采用Load data命令将文本文件导入,采用INSERT ... VALUES的方式插入速度极其慢,插入一条需要几十秒钟,基本上不可用。
Hive 2.1.1需要依赖的jar包有:
hadoop-common-2.6.0.jar
hive-common-2.1.0.jar
hive-jdbc-2.1.0.jar
hive-metastore-2.1.0.jar
hive-serde-2.1.0.jar
hive-service-2.1.0.jar
hive-service-rpc-2.1.0.jar
hive-shims-2.1.0.jar
libthrift-0.9.3.jar
可通过这里查找下载:https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc/2.1.1
如果想从各种数据源直接抽取数据导入Hive,且数据量不算太大的话,建议使用CDATA的驱动,但这个驱动是收费的,有一个月的试用期,试用期到期用新的邮箱地址继续申请也可以。
下载地址:https://www.cdata.com/drivers/hive/jdbc/
下载后解压并运行setup.jar(双击运行),安装到本地磁盘后,打开安装后的目录,里边有三个文件

将jar和lic文件导入到HHDI\WEB-INF\lib下,到期后重新卸载安装该驱动后,将lic文件更新即可
在HHDI驱动管理中,添加如下驱动
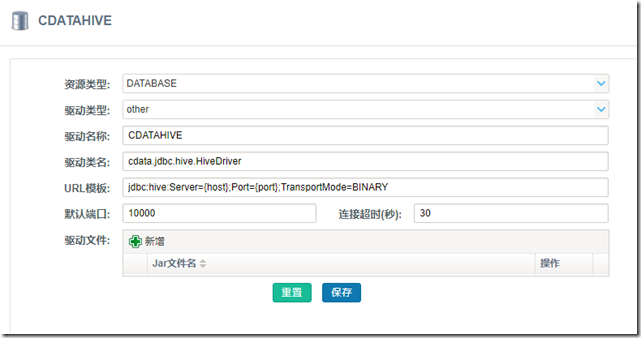
cdata.jdbc.hive.HiveDriver
jdbc:hive:Server={host};Port={port};TransportMode=BINARY
数据连接配置:

数据抽取从Oracle到Hive,1w条记录大约用时50秒,数据量不算太大时,尚可接受。

海量数据导入,还是建议先将数据导出到txt并上传到hdfs,用loaddata命令导入,如下:

关于如何从数据库导出文本并导入Hive,请看另外一篇文章:
https://www.cnblogs.com/haohedi/p/10417902.html
HaoheDI让ETL变得简单,http://www.haohedi.com
利用haohedi ETL将数据库中的数据抽取到hadoop Hive中的更多相关文章
- 把数据库里面的stu表中的数据,导出到excel中
# 2.写代码实现,把我的数据库里面的stu表中的数据,导出到excel中 #编号 名字 性别 # 需求分析:# 1.连接好数据库,写好SQL,查到数据 [[1,'name1','男'],[1,'na ...
- C# Unity游戏开发——Excel中的数据是如何到游戏中的 (二)
本帖是延续的:C# Unity游戏开发——Excel中的数据是如何到游戏中的 (一) 上个帖子主要是讲了如何读取Excel,本帖主要是讲述读取的Excel数据是如何序列化成二进制的,考虑到现在在手游中 ...
- C# Unity游戏开发——Excel中的数据是如何到游戏中的 (三)
本帖是延续的:C# Unity游戏开发——Excel中的数据是如何到游戏中的 (二) 前几天有点事情所以没有继续更新,今天我们接着说.上个帖子中我们看到已经把Excel数据生成了.bin的文件,不过其 ...
- C# Unity游戏开发——Excel中的数据是如何到游戏中的 (四)2018.4.3更新
本帖是延续的:C# Unity游戏开发--Excel中的数据是如何到游戏中的 (三) 最近项目不算太忙,终于有时间更新博客了.关于数据处理这个主题前面的(一)(二)(三)基本上算是一个完整的静态数据处 ...
- vlookup函数基本使用--如何将两个Excel表中的数据匹配;excel表中vlookup函数使用方法将一表引到另一表
vlookup函数基本使用--如何将两个Excel表中的数据匹配:excel表中vlookup函数使用方法将一表引到另一表 一.将几个学生的籍贯匹配出来‘ 二.使用查找与引用函数 vlookup 三. ...
- excel中的数据粘贴不全到plsql中,excel 粘贴后空白,Excel复制粘贴内容不全
http://zhidao.baidu.com/link?url=pHZQvfWJzI-lQjl4uP86q4GLcpYHu4o-fdjiYegJS0Cy5HEq5oz0YrUye3iHjmv5CJ3 ...
- hbase使用MapReduce操作4(实现将 HDFS 中的数据写入到 HBase 表中)
实现将 HDFS 中的数据写入到 HBase 表中 Runner类 package com.yjsj.hbase_mr2; import com.yjsj.hbase_mr2.ReadFruitFro ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- sql之将一个表中的数据注入另一个表中
sql之将一个表中的数据注入另一个表中 需求:现有两张表t1,t2,现需要将t2的数据通过XZQHBM相同对应放入t1表中 t1: t2: 思路:left join 语句: select * from ...
随机推荐
- jq扩展
方法一(不常用)$.myjq = function(){alert("hello myjQuery);}方法二声明:$.fn.myjq=function(){$(this).text(&qu ...
- leetcode-palindrome partitioning-ZZ
http://yucoding.blogspot.com/2013/08/leetcode-question-132-palindrome.html Analysis:When face the &q ...
- java Date中方法toLocaleString过时的替代方案
DateFormat ddf = DateFormat.getDateInstance(); DateFormat dtf = DateFormat.getTimeInstance(); DateFo ...
- Python学习---重点模块之pickle
仅仅支持Python里面的函数等相关功能的实现,而且pickle写入的内容是看不出来的,读取的时候要求有原内容 pickled的写入: import pickle def fun(): print(' ...
- System IPC 与Posix IPC(共享内存)
系统v(共享内存) 1.对于系统V共享内存,主要有以下几个API:shmget().shmat().shmdt()及shmctl(). 2.shmget()用来获得共享内存区域的ID,如果不存在指定的 ...
- wampserver的安装与配置
一.安装:wamp的安装很简单,只需要按照提示并根据自己的需求操作即可,这里不再赘述. 二.配置:wamp安装完后,需进行如下配置才能正常工作. 1.修改MySQL的登录密码 (1)启动WampSer ...
- 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
015-08-09 杨尚刚 高可用架构 此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美 ...
- HashMap和Hashtable的详细区别
1.Hashtable是线程安全,HashMap是非线程安全 HashMap的性能会高于Hashtable,我们平时使用时若无特殊需求建议使用HashMap,在多线程环境下若使用HashMap需要使用 ...
- HDU 2030 汉字统计(汉字Asics码为负,占两个char)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=2030 汉字统计 Time Limit: 2000/1000 MS (Java/Others) M ...
- Linux 文件系统 的 学习
学习参考大神:http://www.cnblogs.com/yyyyy5101/articles/1901842.html 总结:简介 http://linux.chinaunix.net/tech ...