Spark集群新增节点方法
Spark集群处理能力不足需要扩容,如何在现有spark集群中新增新节点?本文以一个实例介绍如何给Spark集群新增一个节点。
1. 集群环境
现有Spark集群包括3台机器,用户名都是cdahdp,主目录/home/ap/cdahdp,配置是2C8G虚拟机,集群基于yarn架构。
Master:128.196.54.112/W118PC01VM01
Slave1:128.196.54.113/W118PC02VM01
Slave2:128.196.54.114/W118PC03VM01
相关软件版本:jdk1.7、scala2.10.4、hadoop2.6.0、spark1.1
现在需要新增一个节点:128.196.54.115/W118PC04VM01,2C8G
首先停止当前集群:停止spark,停止hdfs和yarn。
2. 新节点要求
(1)新节点需要增加用户cdahdp,主目录/home/ap/cdahdp。与集群现有机器一致。
(2)修改所有节点的/etc/hosts文件,更新新节点的ip hostname配置。
(3)配置ssh,使新节点与集群中各节点能够无密码互相ssh登录。
(4)在新节点上安装jdk、scala、hadoop和spark。其版本,安装目录,环境变量设置与集群中现有节点保持一致。比如可以直接从集群节点赋值。
3. 配置文件修改
(1)修改$HADOOP_HOME/etc/hadoop/slaves文件,增加新节点作为slave节点。
(2)修改$SPARK_HOME/conf/slaves文件,增加新节点作为slave节点。
(3)格式化新节点的namenode:
cd $HADOOP_HOME/bin
./hdfs namenode -format
4. 启动新集群
启动hdfs,yarn,以及spark。
cd $HADOOP_HOME/sbin
./start-dfs.sh && ./start-yarn.sh
cd $SPARK_HOME/sbin
./start-all.sh
扩容以前:
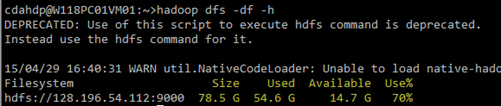
扩容以后:

5. 集群的负载均衡
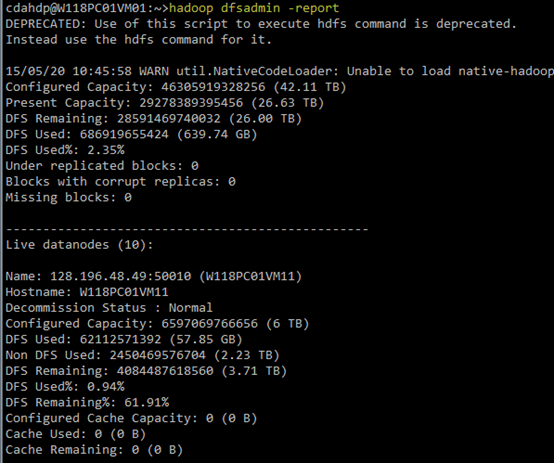
(1)查看HDFS集群的基本信息:执行hadoop dfsadmin -report
(2)负载均衡:在$HADOOP_HOME/sbin/下执行start-balancer.sh
说明:balancer操作是一个较慢的过程,所以在后台执行。balance过程中,数据在各节点之间迁移的速度默认是1M/s。
负载均衡之前:
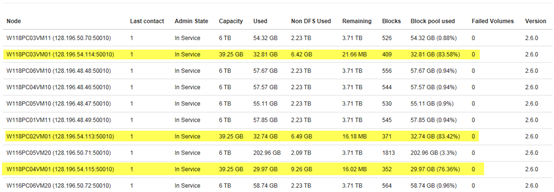
执行负载均衡:

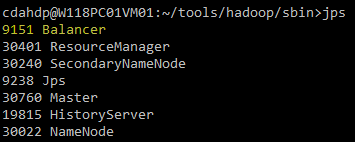
负载均衡之后:

至此,在spark集群增加新节点完毕。
Spark集群新增节点方法的更多相关文章
- Elastic search集群新增节点(同一个集群,同一台物理机,基于ES 7.4)
一开始,在电脑上同一个集群新增节点(node)怎么试也不成功,官网guide又语焉不详?集群健康值yellow(表示主分片全部可用,部分复制分片不可用) 最后,在stackoverflow上找到了答案 ...
- redis 集群新增节点,slots槽分配,删除节点, [ERR] Calling MIGRATE ERR Syntax error, try CLIENT (LIST | KILL | GET...
redis reshard 重新分槽(slots) https://github.com/antirez/redis/issues/5029 redis 官方已确认该bug redis 集群重新(re ...
- CDH5.16.1集群新增节点
如果是全新安装集群的话,可以参考<Ubuntu 16.04上搭建CDH5.16.1集群> 下面是集群新增节点步骤: 1.已经存在一个集群,有两个节点 192.168.100.19 hado ...
- 使用fabric解决百度BMR的spark集群各节点的部署问题
前言 和小伙伴的一起参加的人工智能比赛进入了决赛之后的一段时间里面,一直在构思将数据预处理过程和深度学习这个阶段合并起来.然而在合并这两部分代码的时候,遇到了一些问题,为此还特意写了脚本文件进行处理. ...
- k8s集群新增节点
节点为centos7.4 一.node节点基本环境配置 1.配置主机名 2.配置hosts文件(master和node相互解析) 3.时间同步 ntpdate pool.ntp.org date ec ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
- 十、scala、spark集群搭建
spark集群搭建: 1.上传scala-2.10.6.tgz到master 2.解压scala-2.10.6.tgz 3.配置环境变量 export SCALA_HOME=/mnt/scala-2. ...
- 【Spark】Spark必不可少的多种集群环境搭建方法
目录 Local模式运行环境搭建 小知识 搭建步骤 一.上传压缩包并解压 二.修改Spark配置文件 三.启动验证进入Spark-shell 四.运行Spark自带的测试jar包 standAlone ...
随机推荐
- nodejs的get与post
index.html <html> <body> <form action="/api/v1/records" method="post&q ...
- 廖雪峰JavaScript练习题2
请把用户输入的不规范的英文名字,变为首字母大写,其他小写的规范名字.输入:['adam', 'LISA', 'barT'],输出:['Adam', 'Lisa', 'Bart'] 肯定有更简单的方法, ...
- Codeforces Round #412 A Is it rated ?
A. Is it rated? time limit per test 2 seconds memory limit per test 256 megabytes Is it rated? Her ...
- 基于Tag的Docker自动构建
构建规则 一旦您的Tag符合“release-v$version"的形式,将触发自动构建:1)若您有$version相关的Tag构建规则,则以$version的Tag规则帮您构建:2)若您没 ...
- 【OBJC】数字转中文大写
博客园都不知道怎么外链图片…… - (void)numToString:(double)num{ ; NSMutableString *szChMoney = [[NSMutableString al ...
- hook的函数传入类
简单记录 比如要hook一个app包中一个类的private void c(dmp dmp1),其中dmp是个类,这种的处理的方式如下: 用cydiasubstrate hook框架 1.先通过hoo ...
- androidcarsh
package com.oval.cft; import java.io.File;import java.io.FileOutputStream;import java.io.PrintWriter ...
- 微信小程序——小程序的能力
小程序启动 通过app.json里pages字段可以获得页面路径,而写在 pages 字段的第一个页面就是这个小程序的首页(打开小程序看到的第一个页面),就像下面的代码中,小程序启动后的第一个页面就是 ...
- ArrayList排序Sort()方法(转)
//使用Sort方法,可以对集合中的元素进行排序.Sort有三种重载方法,声明代码如下所//示. public void Sort(); //使用集合元素的比较方式进行排序 public void S ...
- NS Simulation: Scheduling Events (examples inside)
NS Simulation: Scheduling Events Simulation time A similation system (such as NS) must have a built- ...