Neo4j百万级数据导入只需30s
先上图:425万nodes、180万relationships只用了30s 243ms
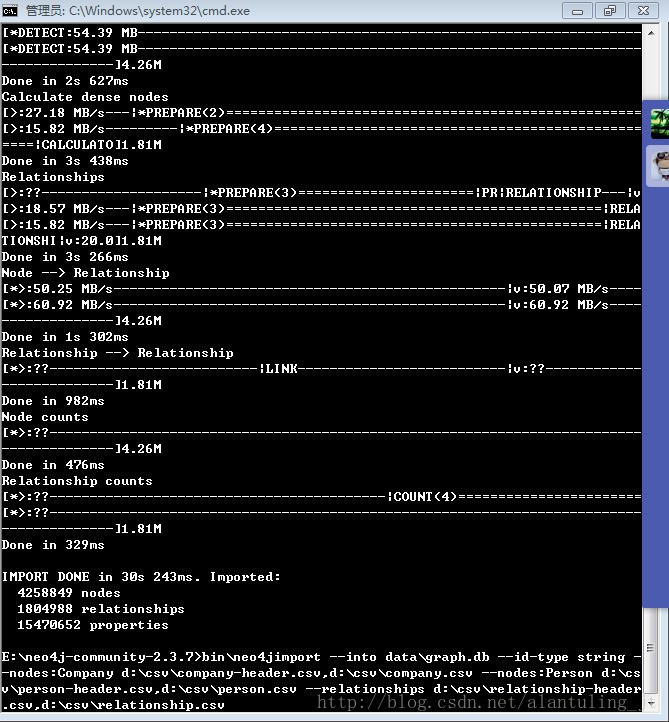
项目需要生成关系图,开始考虑的是用Neo4j官网提供的REST API,从solr中查出2组数据先创建节点再创建关系,过程相当痛苦,速度非常慢,一天都处理不完;
后来改用cypher语句,通过load csv方法,先将数据生成cvs节点文件和关系文件,再通过load csv file create 语法创建,但文件超过30万条时,服务就出错了,遂放弃;
以上2种方法适合小数据量的图库操作,和局部插入更新,不适合大量数据的导入,生成关系图;
后来通过使用官方提供的Neo4jImport 命令行导入数据成功。命令格式在上图中最下面部分有。
首先是要通过查库生成一定格式的csv数据,按node,relationship分别生成,这个可以通过java写代码生成,格式如下:
例子:
节点文件:
文件名:person.csv
文件内容:
id:ID,name,sex,age
p123,jobs,male,28
文件名:company-header.csv
文件内容:
id:ID,entName
文件名:company.csv
文件内容:
c111,Apple
关系文件:
文件名:relationship-header.csv
文件内容:
:START_ID,:END_ID,:TYPE
文件名:relationship.csv
文件内容:
p123,c111,founder
说明:其中一个文件可以分两部分写,一部分写文件头部信息,这些可能需要人为更改,较方便;内容部分一般是代码生成,数据量大,打开修改很费事,一般不动,所以建议分开写,如例子中company-header.csv和company.csv文件就分属于头部文件和内容文件。
:ID表示此列的值作为接连值,并会创建索引,所以如果这列的值有重复,在创建的时候会报错;
:START_ID表示起始节点的ID值;
:END_ID表示结束节点的ID值;
:TYPE表示关系值;
例子中表示的是jobs是Apple公司的创始人;
当然还有其他一些格式,比如:
:LABEL 给列设置标签,可以设置多个标签,用分号分隔;
:IGNORE该列不创建properties
:START_ID(Company)指定该列只能是company中ID的值,前提是company中id:ID(Company)也这样写。
另外,有问题可以留言探讨,我也是刚研究了一周。
原文地址:https://www.jianshu.com/p/0aff60f766f3
Neo4j百万级数据导入只需30s的更多相关文章
- 详解如何挑战4秒内百万级数据导入SQL Server(转)
对于大数据量的导入,是DBA们经常会碰到的问题,在这里我们讨论的是SQL Server环境下百万级数据量的导入,希望对大家有所帮助.51CTO编辑向您推荐<SQL Server入门到精通&g ...
- NEO4J亿级数据导入导出以及数据更新
1.添加配置 apoc.export.file.enabled=true apoc.import.file.enabled=true dbms.directories.import=import db ...
- 实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- 【转 】实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- Excel导入数据库百万级数据瞬间插入
Excel导入数据库百万级数据瞬间插入 百万级别,瞬间,有点吊哇
- Sql Server中百万级数据的查询优化
原文:Sql Server中百万级数据的查询优化 万级别的数据真的算不上什么大数据,但是这个档的数据确实考核了普通的查询语句的性能,不同的书写方法有着千差万别的性能,都在这个级别中显现出来了,它不仅考 ...
- EF查询百万级数据的性能测试--多表连接复杂查询
相关文章:EF查询百万级数据的性能测试--单表查询 一.起因 上次做的是EF百万级数据的单表查询,总结了一下,在200w以下的数据量的情况(Sql Server 2012),EF是可以使用,但是由于 ...
- 【eclipse jar包】在编写java代码时,为方便编程,常常会引用别人已经实现的方法,通常会封装成jar包,我们在编写时,只需引入到Eclipse中即可。
Eclipse中导入外部jar包 在编写java代码时,为方便编程,常常会引用别人已经实现的方法,通常会封装成jar包,我们在编写时,只需引入到Eclipse中即可. 工具/原料 Eclipse 需要 ...
- MSSQL、MySQL 数据库删除大批量千万级百万级数据的优化
原文:https://blog.csdn.net/songyanjun2011/article/details/7308414 SQL Server上面删除1.6亿条记录,不能用Truncate(因为 ...
随机推荐
- 【JAVA】 04-Java中的多线程
链接: 笔记目录:毕向东Java基础视频教程-笔记 GitHub库:JavaBXD33 目录: <> <> 内容待整理: 多线程引入 概述 多线程: 进程:正在执行中的程序,其 ...
- CSS-06 外部JS,CSS文件的寻址问题
如果js.css外部文件有使用到相对路径,其相对路径的基准是不一样的 当一个index.html中引入外部的JS和CSS文件时: 在index.css文件中,相对路径的写法是以css文件相对于img图 ...
- JDBC的ResultSet游标转spark的DataFrame,数据类型的映射以TeraData数据库为例
1.编写给ResultSet添加spark的schema成员及DF(DataFrame)成员 /* spark.sc对象因为是全局的,没有导入,需自行定义 teradata的字段类型转换成spark的 ...
- git 报错
-bash: git: command not found export PATH=$PATH:/usr/local/git/bin 使用git clone出现 fatal: unable to ac ...
- 脚本_监控 HTTP 服务器的状态
#!bin/bash#功能:监控 HTTP 服务器的状态(测试返回码) #作者:liusingbon#设置变量,url 为你需要检测的目标网站的网址(IP 或域名)url=http://192.168 ...
- [BJOI2006]狼抓兔子(网络流)
题目描述 现在小朋友们最喜欢的"喜羊羊与灰太狼",话说灰太狼抓羊不到,但抓兔子还是比较在行的,而且现在的兔子还比较笨,它们只有两个窝,现在你做为狼王,面对下面这样一个网格的地形: ...
- 第五节:从一条记录说起——InnoDB记录结构
<MySQL 是怎样运行的:从根儿上理解 MySQL>第五节:从一条记录说起——InnoDB记录结构 准备工作 现在只知道客户端发送请求并等待服务器返回结果. MySQL什么方式来访 ...
- 【串线篇】sql映射文件-分布查询(上)association 1-1
1.场景 1把钥匙带1把锁 JavaBean:private Lock lock;//当前钥匙能开哪个锁: 1). interface KeyDao: public Key getKeyByIdSim ...
- P4707 重返现世 扩展 MinMax 容斥+DP
题目传送门 https://www.luogu.org/problem/P4707 题解 很容易想到这是一个 MinMax 容斥的题目. 设每一个物品被收集的时间为 \(t_i\),那么集齐 \(k\ ...
- 103、Linux 编译 Kaldi 语音识别工具
由于这个开源的语音识别工具Kaldi只能在Linux下面成功编译, 所以这一小节来写如何成功地在Linux下面编译Kaldi工具 (1)第一步,去github 上面把 Kaldi下载下来 git cl ...