Python之Unittest和Requests库详解
1.按类来执行
import unittest class f1(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_001(self):
pass
def test_002(self):
pass
'''按类来执行'''
if __name__ == '__main__':
suite = unittest.TestSuite(unittest.makeSuite(f1))
unittest.TextTestRunner(verbosity=).run(suite)
2.加载测试模块来执行
import unittest
from selenium import webdriver
class BaiduLink(unittest.TestCase):
def setUp(self):
self.driver=webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait()
self.driver.get(url="htttp://www.baidu.com")
def tearDown(self):
self.driver.quit()
def test_001(self):
self.driver.find_element_by_link_text("新闻").click()
def test_002(self):
self.driver.find_element_by_link_text("地图").click()
'''加载测试模块来执行(TestLoader)'''
if __name__ == '__main__':
suite=unittest.TestLoader().loadTestsFromModule(BaiduLink)
# suite=unittest.TestLoader().loadTestsFromModule("f2.py")
unittest.TextTestRunner(verbosity=).run(suite)
3.优化测试套件
import unittest
from selenium import webdriver
class BaiduLink(unittest.TestCase):
def setUp(self):
self.driver=webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait()
self.driver.get(url="htttp://www.baidu.com")
def tearDown(self):
self.driver.quit()
def test_001(self):
self.driver.find_element_by_link_text("新闻").click()
def test_002(self):
self.driver.find_element_by_link_text("地图").click()
def suite(self):
suite = unittest.TestLoader().loadTestsFromModule(BaiduLink)
return suite
'''加载测试模块来执行(TestLoader)'''
if __name__ == '__main__':
unittest.TextTestRunner(verbosity=).run(BaiduLink.suite())
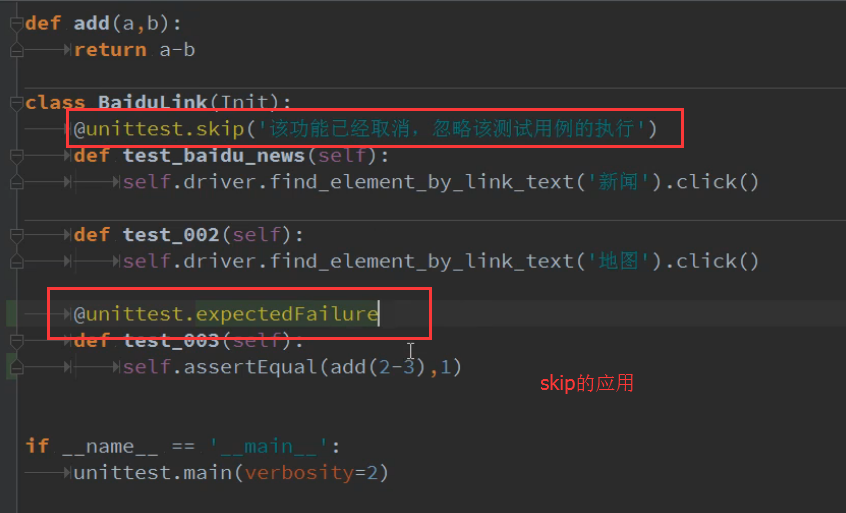
4.skip的应用
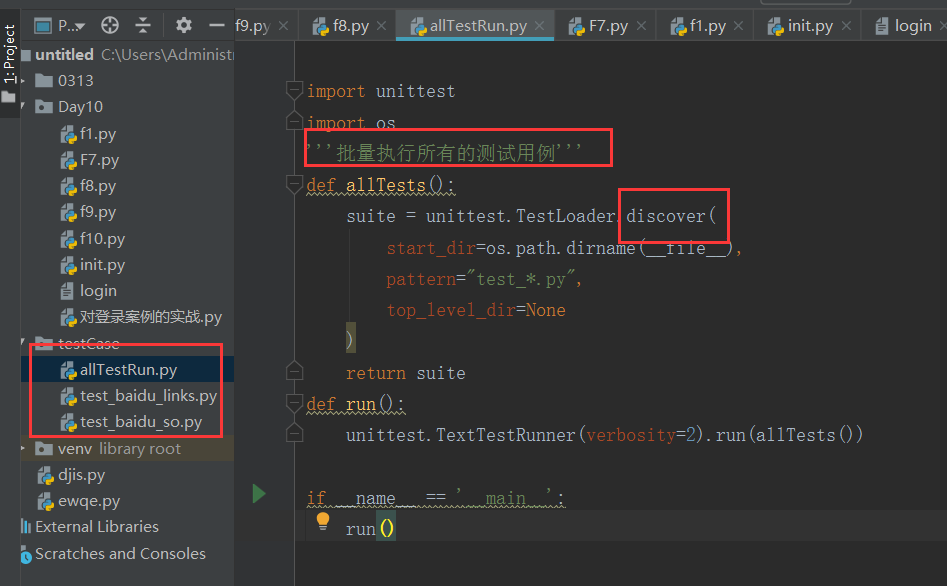
5.批量执行测试用例discover
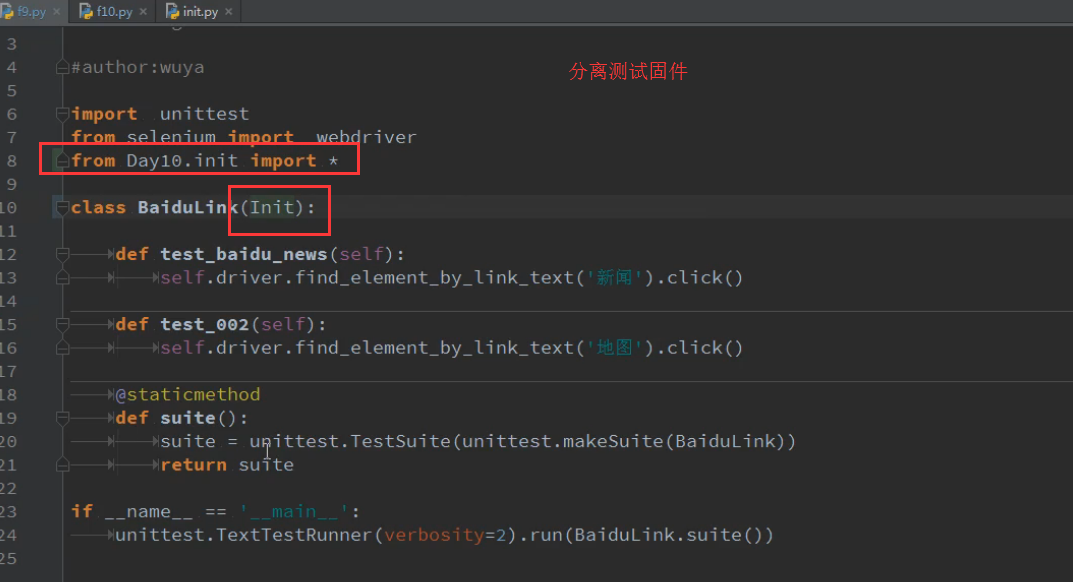
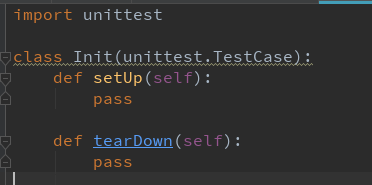
6.分离测试固件
7.生成测试报告
import unittest
import os
from testCase1 import HTMLTestRunner_cn
import time
'''批量执行所有的测试用例''' def allTests():
suite = unittest.TestLoader().discover(
start_dir=os.path.dirname(__file__),
pattern="test_*.py",
top_level_dir=None
)
return suite
def getNowTime():
return time.strftime("%Y-%m-%d %H_%M_%S",time.localtime(time.time())) def run():
# unittest.TextTestRunner(verbosity=).run(allTests())
fp = os.path.join(os.path.dirname(__file__),"report",getNowTime() + "testReport.html")
HTMLTestRunner_cn.HTMLTestRunner(
stream=open(fp,"wb"),
title="自动化测试报告",
description="自动化测试报告详细信息"
).run(allTests()) if __name__ == '__main__':
run()
8.

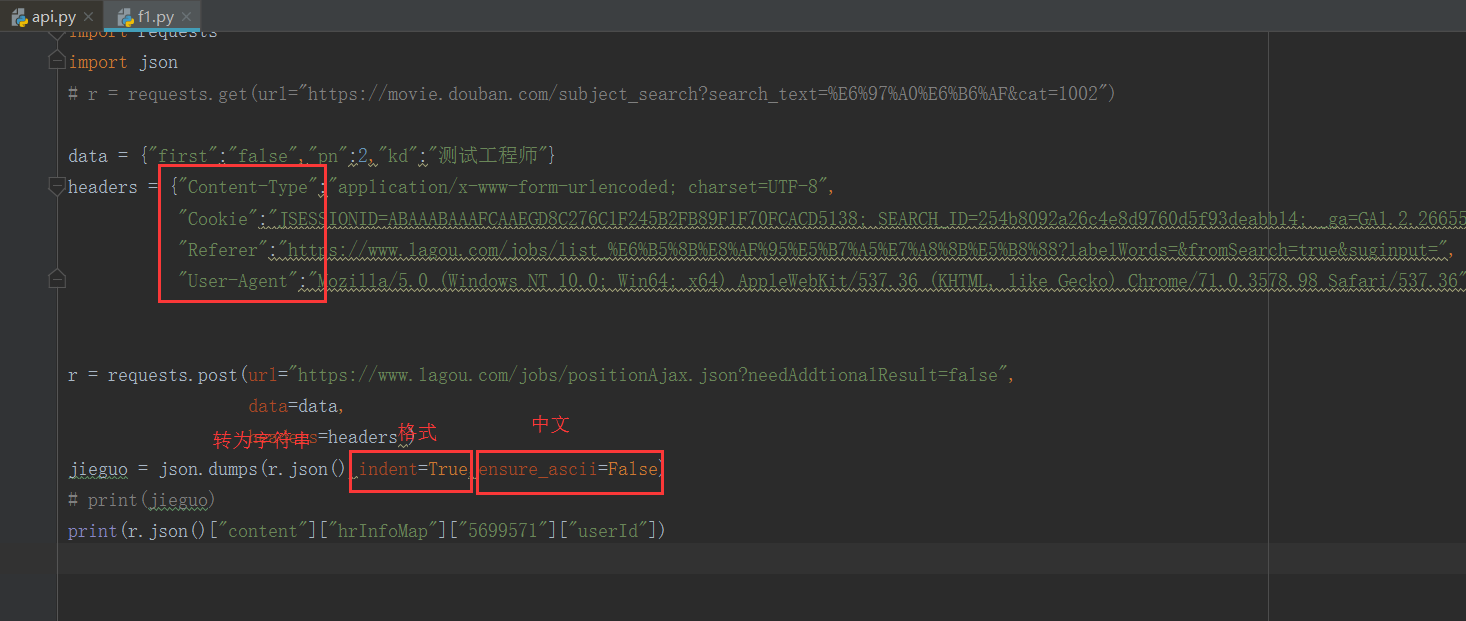
9.
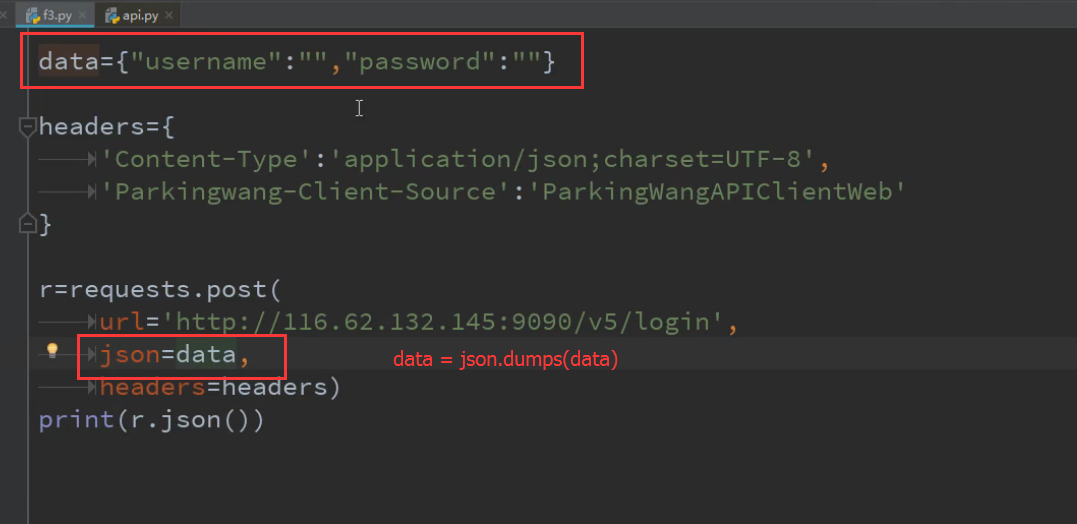
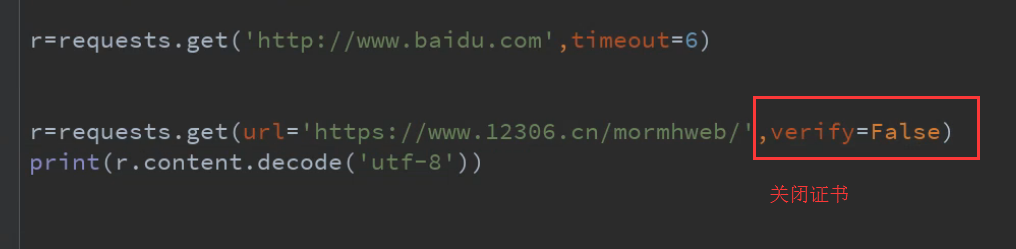
10.关闭证书
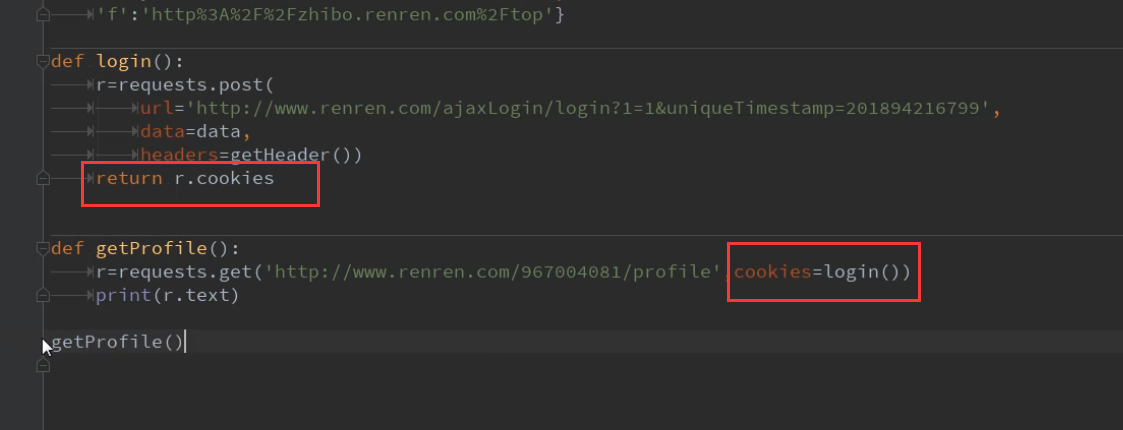
11.cookie关联
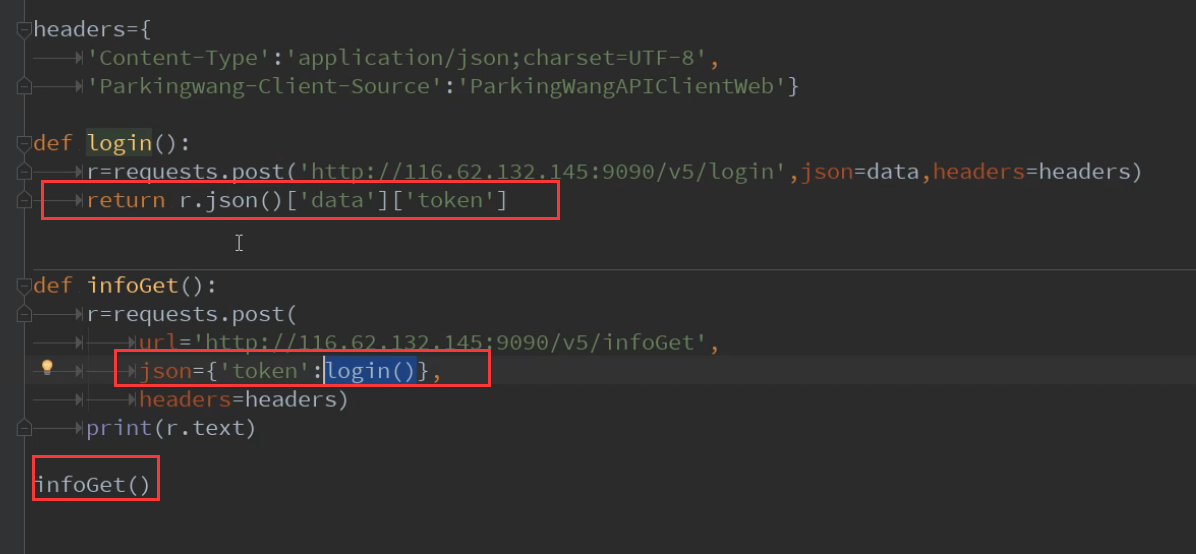
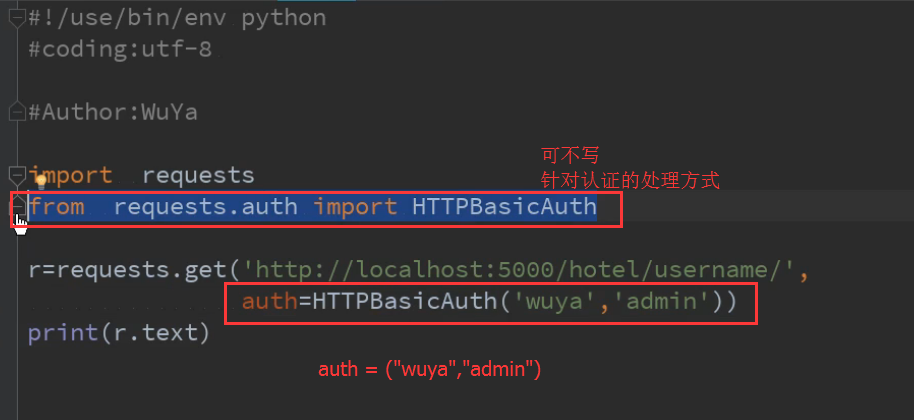
12.对用户名密码的认证方式
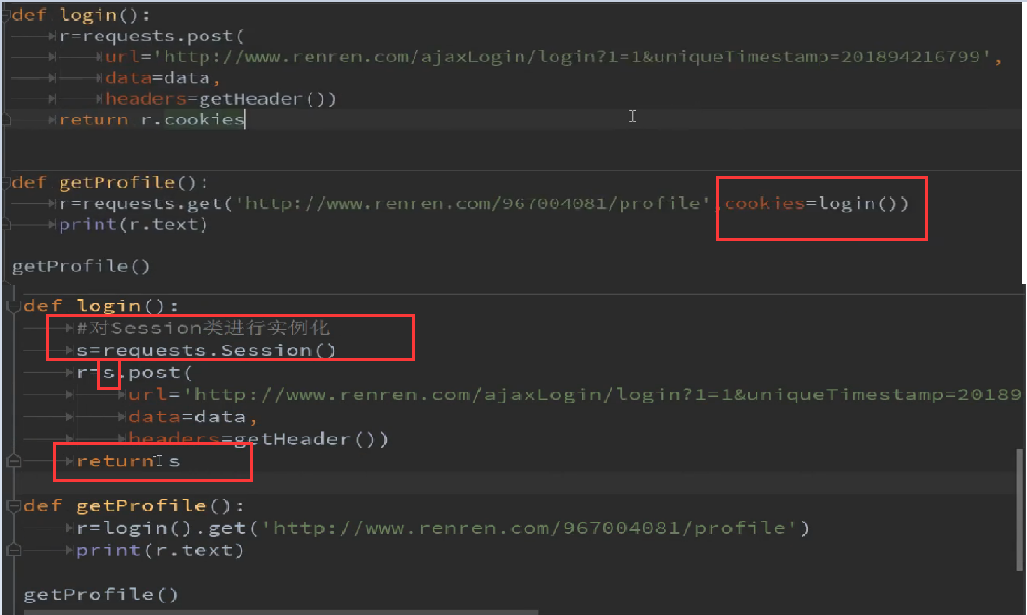
13.session
14.上传文件

15.数据驱动操作elcel文件的操作方法
import xlrd
import os
from xlutils.copy import copy def base_dir(filename):
return os.path.join(os.path.dirname(__file__),filename)
# '''elcel文件的操作'''
# work = xlrd.open_workbook(base_dir("data.xls"))
# sheet = work.sheet_by_index()
# #查看文件有多少行
# print(sheet.nrows)
# #获取单元格的内容
# print(sheet.cell_value(,)) '''excel文件内容的修改'''
work = xlrd.open_workbook(base_dir("data.xls"))
old_content=copy(work)
ws = old_content.get_sheet()
ws.write(,,"")
old_content.save(base_dir("data1.xls"))
Python之Unittest和Requests库详解的更多相关文章
- python接口自动化测试之requests库详解
前言 说到python发送HTTP请求进行接口自动化测试,脑子里第一个闪过的可能就是requests库了,当然python有很多模块可以发送HTTP请求,包括原生的模块http.client,urll ...
- python WEB接口自动化测试之requests库详解
由于web接口自动化测试需要用到python的第三方库--requests库,运用requests库可以模拟发送http请求,再结合unittest测试框架,就能完成web接口自动化测试. 所以笔者今 ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫学习==>第八章:Requests库详解
学习目的: request库比urllib库使用更加简洁,且更方便. 正式步骤 Step1:什么是requests requests是用Python语言编写,基于urllib,采用Apache2 Li ...
- 爬虫学习--Requests库详解 Day2
什么是Requests Requests是用python语言编写,基于urllib,采用Apache2 licensed开源协议的HTTP库,它比urllib更加方便,可以节约我们大量的工作,完全满足 ...
- requests库详解 --Python3
本文介绍了requests库的基本使用,希望对大家有所帮助. requests库官方文档:https://2.python-requests.org/en/master/ 一.请求: 1.GET请求 ...
- python的requests库详解
快速上手 迫不及待了吗?本页内容为如何入门 Requests 提供了很好的指引.其假设你已经安装了 Requests.如果还没有,去安装一节看看吧. 首先,确认一下: Requests 已安装 Req ...
- Python爬虫系列-Requests库详解
Requests基于urllib,比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 实例引入 import requests response = requests.get( ...
- 三十一、python中urllib和requests包详解
A.urllibimport urllibimport urllib.requestimport json '''1.loads,dumpsjson.loads():将字符串转化成python的基础数 ...
随机推荐
- Cause: dx.jar is missing
Cause: dx.jar is missing 解决方案 方案一 copy dx.jar到目标编译版本 查找相应的buildToolsVersion版本下是否有dx.jar存在 如果不存在则可以co ...
- 使用 JavaScript 拦截和跟踪浏览器中的 HTTP 请求
HTTP 请求的拦截技术可以广泛地应用在反向代理.拦截 Ajax 通信.网页的在线翻译.网站改版重构等方面.而拦截根据位置可以分为服务器端和客户端两大类,客户端拦截借助 JavaScript 脚本技术 ...
- java大数据量调优
从总体上来看,对于大型网站,比如门户网站,在面对大量用户访问.高并发请求方面,基本的解决方案集中在这样几个环节:1.首先需要解决网络带宽和Web请求的高并发,需要合理的加大服务器和带宽的投入,并且需要 ...
- Ubuntu16.04下安装Hyperledger Fabric 1.0.0
系统环境 * Ubuntu: 16.04 * Go: 1.9.2 * NodeJS: v6.12.0 * Docker: 17.09.0-ce * HyperLedger Fabric: 1.0.0 ...
- windows github 下载慢 修改hosts
参考:Github访问速度慢和下载慢的解决方法 [Github]windows上访问github慢的解决方法 方法:绕过dns解析,在本地直接绑定host,该方法也可加速其他因为CDN被屏蔽导致访问慢 ...
- Ubuntu14.04 使用本地摄像头跑ORB SLAM2(暂未完成)
嗯 这个方法我暂时弄不出来,用了另外一个方法:SLAM14讲 第一次课 使用摄像头或视频运行 ORB-SLAM2 前面的准备: Ubuntu14.04安装 ROS 安装步骤和问题总结 Ubuntu14 ...
- spring 事物不回滚
使用spring控制事物,为什么有些情况事物,事物不回滚呢?? 默认spring事务只在发生未被捕获的 RuntimeException时才回滚. spring aop 异常捕获原理: 被拦截的 ...
- 按固定元素数目分割数组- perl,python
要求:把40个元素的数组,按每行8个,分5行打印出来.如下图 1 2 3 4 5 6 7 89 10 11 12 13 14 15 1617 18 19 20 21 22 23 2425 26 27 ...
- 3阶马尔可夫链 自然语言处理python
一.简介: 把每三个三个单词作为一个整体进行训练. 举一个例子: input: my dream is that I can be an engineer, so I desi ...
- 用SVG做background image
1 用utf8格式, 需要 双引号“”替换为单引号,而且采用url encode编码,例如# 替换为 %23, body { background-image: url("data:imag ...