数据挖掘(二)——Knn算法的java实现
1、K-近邻算法(Knn)
其原理为在一个样本空间中,有一些已知分类的样本,当出现一个未知分类的样本,则根据距离这个未知样本最近的k个样本来决定。
举例:爱情电影和动作电影,它们中都存在吻戏和动作,出现一个未知分类的电影,将根据以吻戏数量和动作数量建立的坐标系中距离未知分类所在点的最近的k个点来决定。
2、算法实现步骤
(1)计算所有点距离未知点的欧式距离
(2)对所有点进行排序
(3)找到距离未知点最近的k个点
(4)计算这k个点所在分类出现的频率
(5)选择频率最大的分类即为未知点的分类
3、java实现
Point类
public class Point {
private long id;
private double x;
private double y;
private String type;
public Point(long id,double x, double y) {
this.x = x;
this.y = y;
this.id = id;
}
public Point(long id,double x, double y, String type) {
this.x = x;
this.y = y;
this.type = type;
this.id = id;
}
//get、set方法省略
}
Distance类
public class Distance {
// 已知点id
private long id;
// 未知点id
private long nid;
// 二者之间的距离
private double disatance;
public Distance(long id, long nid, double disatance) {
this.id = id;
this.nid = nid;
this.disatance = disatance;
}
//get、set方法省略
}
比较器CompareClass类
import java.util.Comparator;
//比较器类
public class CompareClass implements Comparator<Distance>{ public int compare(Distance d1, Distance d2) {
return d1.getDisatance()>d2.getDisatance()?20 : -1;
} }
KNN主类
/**
*
1、输入所有已知点
2、输入未知点
3、计算所有已知点到未知点的欧式距离
4、根据距离对所有已知点排序
5、选出距离未知点最近的k个点
6、计算k个点所在分类出现的频率
7、选择频率最大的类别即为未知点的类别
*
* @author fzj
*
*/
public class KNN { public static void main(String[] args) { // 一、输入所有已知点
List<Point> dataList = creatDataSet();
// 二、输入未知点
Point x = new Point(5, 1.2, 1.2);
// 三、计算所有已知点到未知点的欧式距离,并根据距离对所有已知点排序
CompareClass compare = new CompareClass();
Set<Distance> distanceSet = new TreeSet<Distance>(compare);
for (Point point : dataList) {
distanceSet.add(new Distance(point.getId(), x.getId(), oudistance(point,
x)));
}
// 四、选取最近的k个点
double k = 5; /**
* 五、计算k个点所在分类出现的频率
*/
// 1、计算每个分类所包含的点的个数
List<Distance> distanceList= new ArrayList<Distance>(distanceSet);
Map<String, Integer> map = getNumberOfType(distanceList, dataList, k); // 2、计算频率
Map<String, Double> p = computeP(map, k); x.setType(maxP(p));
System.out.println("未知点的类型为:"+x.getType());
} // 欧式距离计算
public static double oudistance(Point point1, Point point2) {
double temp = Math.pow(point1.getX() - point2.getX(), 2)
+ Math.pow(point1.getY() - point2.getY(), 2);
return Math.sqrt(temp);
} // 找出最大频率
public static String maxP(Map<String, Double> map) {
String key = null;
double value = 0.0;
for (Map.Entry<String, Double> entry : map.entrySet()) {
if (entry.getValue() > value) {
key = entry.getKey();
value = entry.getValue();
}
}
return key;
} // 计算频率
public static Map<String, Double> computeP(Map<String, Integer> map,
double k) {
Map<String, Double> p = new HashMap<String, Double>();
for (Map.Entry<String, Integer> entry : map.entrySet()) {
p.put(entry.getKey(), entry.getValue() / k);
}
return p;
} // 计算每个分类包含的点的个数
public static Map<String, Integer> getNumberOfType(
List<Distance> listDistance, List<Point> listPoint, double k) {
Map<String, Integer> map = new HashMap<String, Integer>();
int i = 0;
System.out.println("选取的k个点,由近及远依次为:");
for (Distance distance : listDistance) {
System.out.println("id为" + distance.getId() + ",距离为:"
+ distance.getDisatance());
long id = distance.getId();
// 通过id找到所属类型,并存储到HashMap中
for (Point point : listPoint) {
if (point.getId() == id) {
if (map.get(point.getType()) != null)
map.put(point.getType(), map.get(point.getType()) + 1);
else {
map.put(point.getType(), 1);
}
}
}
i++;
if (i >= k)
break;
}
return map;
} public static ArrayList<Point> creatDataSet(){ Point point1 = new Point(1, 1.0, 1.1, "A");
Point point2 = new Point(2, 1.0, 1.0, "A");
Point point3 = new Point(3, 1.0, 1.2, "A");
Point point4 = new Point(4, 0, 0, "B");
Point point5 = new Point(5, 0, 0.1, "B");
Point point6 = new Point(6, 0, 0.2, "B"); ArrayList<Point> dataList = new ArrayList<Point>();
dataList.add(point1);
dataList.add(point2);
dataList.add(point3);
dataList.add(point4);
dataList.add(point5);
dataList.add(point6); return dataList;
}
}
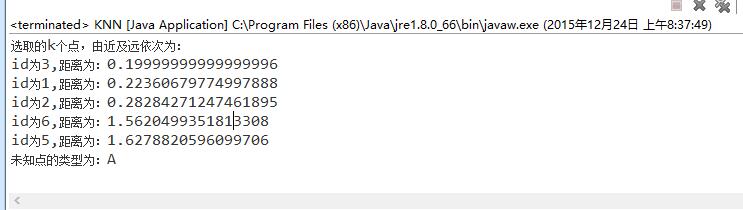
4、运行结果
参考
[1] 《机器学习实战》
数据挖掘(二)——Knn算法的java实现的更多相关文章
- 数据挖掘之KNN算法(C#实现)
在十大经典数据挖掘算法中,KNN算法算得上是最为简单的一种.该算法是一种惰性学习法(lazy learner),与决策树.朴素贝叶斯这些急切学习法(eager learner)有所区别.惰性学习法仅仅 ...
- KNN算法java实现代码注释
K近邻算法思想非常简单,总结起来就是根据某种距离度量检测未知数据与已知数据的距离,统计其中距离最近的k个已知数据的类别,以多数投票的形式确定未知数据的类别. 一直想自己实现knn的java实现,但限于 ...
- KNN算法介绍及源码实现
一.KNN算法介绍 邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它 ...
- 深入浅出KNN算法(一) KNN算法原理
一.KNN算法概述 KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- KNN算法 - 数据挖掘算法(3)
(2017-04-10 银河统计) KNN算法即K Nearest Neighbor算法.这个算法是机器学习里面一个比较经典的.相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法 ...
- 机器学习之二:K-近邻(KNN)算法
一.概述 K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中 ...
- 深入浅出KNN算法(二) sklearn KNN实践
姊妹篇: 深入浅出KNN算法(一) 原理介绍 上次介绍了KNN的基本原理,以及KNN的几个窍门,这次就来用sklearn实践一下KNN算法. 一.Skelarn KNN参数概述 要使用sklearnK ...
- CRC16算法之二:CRC16-CCITT-XMODEM算法的java实现
CRC16算法系列文章: CRC16算法之一:CRC16-CCITT-FALSE算法的java实现 CRC16算法之二:CRC16-CCITT-XMODEM算法的java实现 CRC16算法之三:CR ...
随机推荐
- python装饰器同时支持有参数和无参数的练习题
''' 预备知识: …… @decorator def f(*args,**kwargs): pass # 此处@decorator 等价于 f = decorator(f) @decorator2 ...
- 【洛谷P3960】列队题解
[洛谷P3960]列队题解 题目链接 题意: Sylvia 是一个热爱学习的女孩子. 前段时间,Sylvia 参加了学校的军训.众所周知,军训的时候需要站方阵. Sylvia 所在的方阵中有 n×m ...
- Forward团队-爬虫豆瓣top250项目-开发文档
项目地址:https://github.com/xyhcq/top250 我在本次项目中负责写爬虫中对数据分析的一部分,根据马壮分析过的html,我来进一步写代码获取数据,具体的功能及实现方法我已经写 ...
- jQuery获取父级、兄弟节点的方法
一.jQuery的父节点查找方法 $(selector).parent(selector):获取父节点 $(selector).parentNode:以node[]的形式存放父节点,如果没有父节点,则 ...
- 关于opengl的ActiveTexture以及bindXxx函数的分析
1.GLBindxxx,意思就是,将xxx指定为当前对象,之后的操作都是针对这个xxx进行. 比如,GLBindBuffer(bufferTarget, bufferId),就是指定bufferid和 ...
- C#通过COM组件操作IE浏览器(二):使用IHTMLDocument3完成登录
第一章介绍了如何打开网站,这一章介绍一下使用IHTMLDocument3完成登录博客园,以下为代码: SHDocVw.InternetExplorer oBrowser = new SHDocVw.I ...
- vue组件推荐
Vue 是一个轻巧.高性能.可组件化的MVVM库,API简洁明了,上手快.从Vue推出以来,得到众多Web开发者的认可.在公司的Web前端项目开发中,多个项目采用基于Vue的UI组件框架开发,并投入正 ...
- 吴恩达机器学习笔记35-诊断偏差和方差(Diagnosing Bias vs. Variance)
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大.换句话说,出现的情况要么是欠拟合,要么是过拟合问题.那么这两种情况,哪个和偏差有关,哪个和 ...
- Ubuntu 16.04安装下HTK--亲测ok
1.首先需要安装一些32位库sudo apt-get install libx11-dev:i386 libx11-dev sudo apt-get install g++-multilib sudo ...
- Ubuntu18.04下配置Nginx+RTMP服务器,实现点播/直播/录制功能
2019.3.22更新 最新的nginx-1.15.9可与openssl1.1.1兼容了 以下原文: 这个东西我眼馋挺久了,最近终于试玩了一下,感觉很好玩,在搭建的过程在也遇到一些坑,这里总结一下 安 ...