利用aiohttp制作异步爬虫
asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块。关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架——aiohttp,它可以帮助我们异步地实现HTTP请求,从而使得我们的程序效率大大提高。
本文将会介绍aiohttp在爬虫中的一个简单应用。
我们的项目来源于:Scrapy爬虫(5)爬取当当网图书畅销榜,在原来的项目中,我们是利用Python的爬虫框架scrapy来爬取当当网图书畅销榜的图书信息的。在本文中,笔者将会以两种方式来制作爬虫,比较同步爬虫与异步爬虫(利用aiohttp实现)的效率,展示aiohttp在爬虫方面的优势。
首先,我们先来看看用一般的方法实现的爬虫,即同步方法,完整的Python代码如下:
'''
同步方式爬取当当畅销书的图书信息
'''
import time
import requests
import pandas as pd
from bs4 import BeautifulSoup
# table表格用于储存书本信息
table = []
# 处理网页
def download(url):
html = requests.get(url).text
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(html, "lxml")
# 获取网页中的畅销书信息
book_list = soup.find('ul', class_="bang_list clearfix bang_list_mode")('li')
for book in book_list:
info = book.find_all('div')
# 获取每本畅销书的排名,名称,评论数,作者,出版社
rank = info[0].text[0:-1]
name = info[2].text
comments = info[3].text.split('条')[0]
author = info[4].text
date_and_publisher = info[5].text.split()
publisher = date_and_publisher[1] if len(date_and_publisher) >= 2 else ''
# 将每本畅销书的上述信息加入到table中
table.append([rank, name, comments, author, publisher])
# 全部网页
urls = ['http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-%d' % i for i in range(1, 26)]
# 统计该爬虫的消耗时间
print('#' * 50)
t1 = time.time() # 开始时间
for url in urls:
download(url)
# 将table转化为pandas中的DataFrame并保存为CSV格式的文件
df = pd.DataFrame(table, columns=['rank', 'name', 'comments', 'author', 'publisher'])
df.to_csv('E://douban/dangdang.csv', index=False)
t2 = time.time() # 结束时间
print('使用一般方法,总共耗时:%s' % (t2 - t1))
print('#' * 50)
输出结果如下:
##################################################
使用一般方法,总共耗时:23.522345542907715
##################################################
程序运行了23.5秒,爬取了500本书的信息,效率还是可以的。
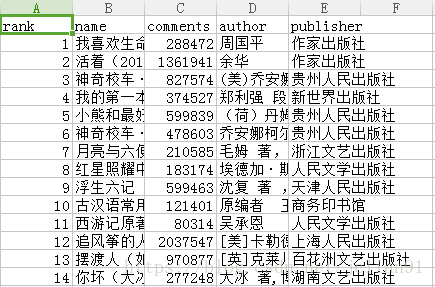
我们前往目录中查看文件,如下:
接下来我们看看用aiohttp制作的异步爬虫的效率,完整的源代码如下:
'''
异步方式爬取当当畅销书的图书信息
'''
import time
import aiohttp
import asyncio
import pandas as pd
from bs4 import BeautifulSoup
# table表格用于储存书本信息
table = []
# 获取网页(文本信息)
async def fetch(session, url):
async with session.get(url) as response:
return await response.text(encoding='gb18030')
# 解析网页
async def parser(html):
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(html, "lxml")
# 获取网页中的畅销书信息
book_list = soup.find('ul', class_="bang_list clearfix bang_list_mode")('li')
for book in book_list:
info = book.find_all('div')
# 获取每本畅销书的排名,名称,评论数,作者,出版社
rank = info[0].text[0:-1]
name = info[2].text
comments = info[3].text.split('条')[0]
author = info[4].text
date_and_publisher = info[5].text.split()
publisher = date_and_publisher[1] if len(date_and_publisher) >=2 else ''
# 将每本畅销书的上述信息加入到table中
table.append([rank,name,comments,author,publisher])
# 处理网页
async def download(url):
async with aiohttp.ClientSession() as session:
html = await fetch(session, url)
await parser(html)
# 全部网页
urls = ['http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-%d'%i for i in range(1,26)]
# 统计该爬虫的消耗时间
print('#' * 50)
t1 = time.time() # 开始时间
# 利用asyncio模块进行异步IO处理
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(download(url)) for url in urls]
tasks = asyncio.gather(*tasks)
loop.run_until_complete(tasks)
# 将table转化为pandas中的DataFrame并保存为CSV格式的文件
df = pd.DataFrame(table, columns=['rank','name','comments','author','publisher'])
df.to_csv('E://douban/dangdang.csv',index=False)
t2 = time.time() # 结束时间
print('使用aiohttp,总共耗时:%s' % (t2 - t1))
print('#' * 50)
我们可以看到,这个爬虫与原先的一般方法的爬虫的思路和处理方法基本一致,只是在处理HTTP请求时使用了aiohttp模块以及在解析网页时函数变成了协程(coroutine),再利用aysncio进行并发处理,这样无疑能够提升爬虫的效率。它的运行结果如下:
##################################################
使用aiohttp,总共耗时:2.405137538909912
##################################################
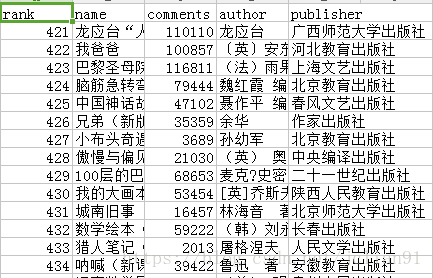
2.4秒,如此神奇!!!再来看看文件的内容:
综上可以看出,利用同步方法和异步方法制作的爬虫的效率相差很大,因此,我们在实际制作爬虫的过程中,也不妨可以考虑异步爬虫,多多利用异步模块,如aysncio, aiohttp。另外,aiohttp只支持3.5.3以后的Python版本。
当然,本文只是作为一个异步爬虫的例子,并没有具体讲述异步背后的故事,而异步的思想在我们现实生活和网站制作等方面有着广泛的应用,笔者将会以自己的理解来介绍异步编程,欢迎大家关注。
本文到此结束,欢迎大家关注微信公众号: 轻松学会Python爬虫(微信号为:easy_web_scrape)。欢迎交流~
利用aiohttp制作异步爬虫的更多相关文章
- python 基于aiohttp的异步爬虫实战
钢铁知识库,一个学习python爬虫.数据分析的知识库.人生苦短,快用python. 之前我们使用requests库爬取某个站点的时候,每发出一个请求,程序必须等待网站返回响应才能接着运行,而在整个爬 ...
- 利用js制作异步验证ajax方法()
如何利用js写ajax异步验证.代码如下: window.onload = function(){ var name = document.getElementById('register-name- ...
- 深入理解协程(四):async/await异步爬虫实战
本文目录: 同步方式爬取博客标题 async/await异步爬取博客标题 本片为深入理解协程系列文章的补充. 你将会在从本文中了解到:async/await如何运用的实际的爬虫中. 案例 从CSDN上 ...
- python异步爬虫
本文主要包括以下内容 线程池实现并发爬虫 回调方法实现异步爬虫 协程技术的介绍 一个基于协程的异步编程模型 协程实现异步爬虫 线程池.回调.协程 我们希望通过并发执行来加快爬虫抓取页面的速度.一般的实 ...
- [python]新手写爬虫v2.5(使用代理的异步爬虫)
开始 开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地).同时使用的是tornado的HTTPClient的库爬取内容. 中篇:开篇主要是获取代理ip:中篇打 ...
- (转)新手写爬虫v2.5(使用代理的异步爬虫)
开始 开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地).同时使用的是tornado的HTTPClient的库爬取内容. 中篇:开篇主要是获取代理ip:中篇打 ...
- Python实现基于协程的异步爬虫
一.课程介绍 1. 课程来源 本课程核心部分来自<500 lines or less>项目,作者是来自 MongoDB 的工程师 A. Jesse Jiryu Davis 与 Python ...
- 自定义异步爬虫架构 - AsyncSpider
作者:张亚飞 山西医科大学在读研究生 1. 并发编程 Python中实现并发编程的三种方案:多线程.多进程和异步I/O.并发编程的好处在于可以提升程序的执行效率以及改善用户体验:坏处在于并发的程序不容 ...
- 利用TabHost制作QQ客户端标签栏效果(低版本QQ)
学习一定要从基础学起,只有有一个好的基础,我们才会变得更加的perfect 下面小编将利用TabHost制作QQ客户端标签栏效果(这个版本的QQ是在前几年发布的)…. 首先我们看一下效果: 看到这个界 ...
随机推荐
- 配置wildfly10为linux的服务,并开机启动
1.在opt路径下 下载 wildfly ,并解压下载下的压缩包 cd /opt sudo wget -c http://download.jboss.org/wildfly/10.0.0.Final ...
- mvc项目 ajax post 返回404错误
后台代码没有问题,但是一直出现404错误 原因:iis设置,请求中文件大小超过限制会被过滤掉,直接返回404. 解决:设置iis,应用程序->请求筛选->规则->编辑功能设置-> ...
- 基于MFC的socket编程
网络编程 1.windows 套接字编程(开放的网络编程接口)添加头文件#include<windows.h> 2.套接字及其分类 socket分为两种:(1)数据报socket:无连接套 ...
- js读取txt文件
$('#selectAreaFile').on('change',function(e){//用户区域的文件选择 var files=e.target.files; if ...
- 28.TreeSet
与HashSet是基于HashMap实现一样,TreeSet同样是基于TreeMap实现的.在前一篇中详细讲解了TreeMap实现机制,如果客官详细看了这篇博文或者对TreeMap有比较详细的了解,那 ...
- 《HTTP权威指南》2-URL
前言 在一个城市中,所有的东西都有一个标准化的名字,以帮助人们寻找城市中的各种资源,如宁波火车站地铁站,在因特网这座大城市中,URL就是其标准化名称,它指向每一条电子信息,告诉你它们位于何处,以及如何 ...
- API网关-Ocelot概述
这个框架的整体思路其实就是Redirect请求并且附带一个简易的负载均衡机制,完全搭建MVC Core项目下在Ocelot项目启动的时候需要配置所有的ReRoute集合,这里的每一个ReRoute可以 ...
- Redis-01.初探
官网 http://redis.io 中文网 http://redis.cn 命令参考 http://redisdoc.cn Redis(Remote Dictionary Server)是一个开源的 ...
- 包建强的培训课程(4):App测试深入学习和研究
@import url(http://i.cnblogs.com/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/c ...
- 【转】odoo nginx 配置
## OpenERP backend ## upstream odoo { server 127.0.0.1:8069 weight=1 fail_timeout=0; } upstream odoo ...