自定义异步爬虫架构 - AsyncSpider
作者:张亚飞
山西医科大学在读研究生
1. 并发编程
Python中实现并发编程的三种方案:多线程、多进程和异步I/O。并发编程的好处在于可以提升程序的执行效率以及改善用户体验;坏处在于并发的程序不容易开发和调试,同时对其他程序来说它并不友好。
- 多线程:Python中提供了Thread类并辅以Lock、Condition、Event、Semaphore和Barrier。Python中有GIL来防止多个线程同时执行本地字节码,这个锁对于CPython是必须的,因为CPython的内存管理并不是线程安全的,因为GIL的存在多线程并不能发挥CPU的多核特性。
- 多进程:多进程可以有效的解决GIL的问题,实现多进程主要的类是Process,其他辅助的类跟threading模块中的类似,进程间共享数据可以使用管道、套接字等,在multiprocessing模块中有一个Queue类,它基于管道和锁机制提供了多个进程共享的队列。下面是官方文档上关于多进程和进程池的一个示例。
- 异步处理:从调度程序的任务队列中挑选任务,该调度程序以交叉的形式执行这些任务,我们并不能保证任务将以某种顺序去执行,因为执行顺序取决于队列中的一项任务是否愿意将CPU处理时间让位给另一项任务。异步任务通常通过多任务协作处理的方式来实现,由于执行时间和顺序的不确定,因此需要通过回调式编程或者
future对象来获取任务执行的结果。Python 3通过asyncio模块和await和async关键字(在Python 3.7中正式被列为关键字)来支持异步处理。
Python中有一个名为
aiohttp的三方库,它提供了异步的HTTP客户端和服务器,这个三方库可以跟asyncio模块一起工作,并提供了对Future对象的支持。Python 3.6中引入了async和await来定义异步执行的函数以及创建异步上下文,在Python 3.7中它们正式成为了关键字。下面的代码异步的从5个URL中获取页面并通过正则表达式的命名捕获组提取了网站的标题。
# -*- coding: utf-8 -*-
"""
Datetime: 2019/6/13
Author: Zhang Yafei
Description: async + await + aiiohttp 异步编程示例
"""
import asyncio
import re
import aiohttp
PATTERN = re.compile(r'\<title\>(?P<title>.*)\<\/title\>')
async def fetch_page(session, url):
async with session.get(url, ssl=False) as resp:
return await resp.text()
async def show_title(url):
async with aiohttp.ClientSession() as session:
html = await fetch_page(session, url)
print(PATTERN.search(html).group('title'))
def main():
urls = ('https://www.python.org/',
'https://git-scm.com/',
'https://www.jd.com/',
'https://www.taobao.com/',
'https://www.douban.com/')
loop = asyncio.get_event_loop()
tasks = [show_title(url) for url in urls]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
if __name__ == '__main__':
main()
当程序不需要真正的并发性或并行性,而是更多的依赖于异步处理和回调时,asyncio就是一种很好的选择。如果程序中有大量的等待与休眠时,也应该考虑asyncio,它很适合编写没有实时数据处理需求的Web应用服务器。
2. 自定义异步爬虫架构 - AsyncSpider
- 目录结构
目录结构
- manage.py: 项目启动文件
- engine.py: 项目引擎
- settings.py: 项目参数设置
- spiders文件夹: spider爬虫编写

- settings设置
import os
DIR_PATH = os.path.abspath(os.path.dirname(__file__))
# 爬虫项目模块类路径
Spider_Name = 'spiders.xiaohua.XiaohuaSpider'
# 全局headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
TO_FILE = 'xiaohua.csv'
# 若要保存图片,设置文件夹
IMAGE_DIR = 'images'
if not os.path.exists(IMAGE_DIR):
os.mkdir(IMAGE_DIR)
- spider编写
- 结构

spider编写
- 编写爬取xiaohua网示例
# -*- coding: utf-8 -*-
"""
Datetime: 2019/6/11
Author: Zhang Yafei
Description: 爬虫Spider
"""
import os
import re
from urllib.parse import urljoin
from engine import Request
from settings import TO_FILE
import pandas as pd
class XiaohuaSpider(object):
""" 自定义Spider类 """
# 1. 自定义起始url列表
start_urls = [f'http://www.xiaohuar.com/list-1-{i}.html' for i in range(4)]
def filter_downloaded_urls(self):
""" 2. 添加过滤规则 """
# self.start_urls = self.start_urls
pass
def start_request(self):
""" 3. 将请求加入请求队列(集合),发送请求 """
for url in self.start_urls:
yield Request(url=url, callback=self.parse)
async def parse(self, response):
""" 4. 拿到请求响应,进行数据解析 """
html = await response.text(encoding='gbk')
reg = re.compile('<img width="210".*alt="(.*?)".*src="(.*?)" />')
results = re.findall(reg, html)
item_list = []
request_list = []
for name, src in results:
img_url = src if src.startswith('http') else urljoin('http://www.xiaohuar.com', src)
item_list.append({'name': name, 'img_url': img_url})
request_list.append(Request(url=img_url, callback=self.download_img, meta={'name': name}))
# 4.1 进行数据存储
await self.store_data(data=item_list, url=response.url)
# 4.2 返回请求和回调函数
return request_list
@staticmethod
async def store_data(data, url):
""" 5. 数据存储 """
df = pd.DataFrame(data=data)
if os.path.exists(TO_FILE):
df.to_csv(TO_FILE, index=False, mode='a', header=False, encoding='utf_8_sig')
else:
df.to_csv(TO_FILE, index=False, encoding='utf_8_sig')
print(f'{url}\t数据下载完成')
@staticmethod
async def download_img(response):
""" 二层深度下载 """
name = response.request.meta.get('name')
with open(f'images/{name}.jpg', mode='wb') as f:
f.write(await response.read())
print(f'{name}\t下载成功')
- 运行
cd AsyncSpider
python manage.py

运行结果


下载图片
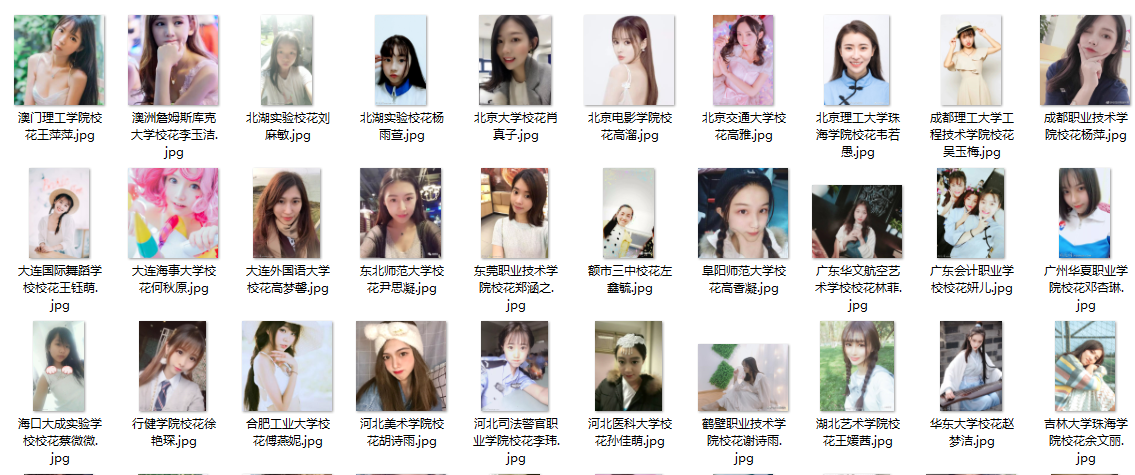
- 生成文件
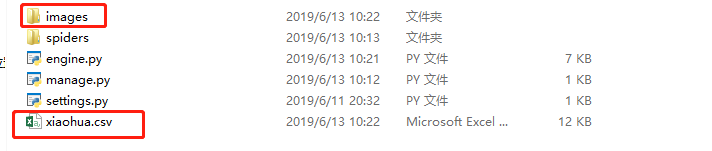
自定义异步爬虫架构 - AsyncSpider的更多相关文章
- 爬虫之多线程 多进程 自定义异步IO框架
什么是进程? 进程是程序运行的实例,是系统进行资源分配和调度的一个独立单位,它包括独立的地址空间,资源以及1个或多个线程. 什么是线程? 线程可以看成是轻量级的进程,是CPU调度和分派的基本单位. 进 ...
- python异步爬虫
本文主要包括以下内容 线程池实现并发爬虫 回调方法实现异步爬虫 协程技术的介绍 一个基于协程的异步编程模型 协程实现异步爬虫 线程池.回调.协程 我们希望通过并发执行来加快爬虫抓取页面的速度.一般的实 ...
- [python]新手写爬虫v2.5(使用代理的异步爬虫)
开始 开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地).同时使用的是tornado的HTTPClient的库爬取内容. 中篇:开篇主要是获取代理ip:中篇打 ...
- SQL Server 2005 中实现通用的异步触发器架构
在SQL Server 2005中,通过新增的Service Broker可以实现异步触发器的处理功能.本文提供一种使用Service Broker实现的通用异步触发器方法. 在本方法中,通过Serv ...
- ASP.NET之自定义异步HTTP处理程序(图文教程)
前面我们学习了关于关于自定义同步HTTP处理程序,相信大家可能感觉有所成就,但是这种同步的机制只能对付客户访问较少的情况或者数据处理量不大的情况,而今天这篇文章就是解决同步HTTP处理程序的这个致命缺 ...
- (转)新手写爬虫v2.5(使用代理的异步爬虫)
开始 开篇:爬代理ip v2.0(未完待续),实现了获取代理ips,并把这些代理持久化(存在本地).同时使用的是tornado的HTTPClient的库爬取内容. 中篇:开篇主要是获取代理ip:中篇打 ...
- Python实现基于协程的异步爬虫
一.课程介绍 1. 课程来源 本课程核心部分来自<500 lines or less>项目,作者是来自 MongoDB 的工程师 A. Jesse Jiryu Davis 与 Python ...
- 利用aiohttp制作异步爬虫
asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--a ...
- 03: 自定义异步非阻塞tornado框架
目录:Tornado其他篇 01: tornado基础篇 02: tornado进阶篇 03: 自定义异步非阻塞tornado框架 04: 打开tornado源码剖析处理过程 目录: 1.1 源码 1 ...
随机推荐
- 过滤敏感词工具类SensitiveFilter
网上过滤敏感词工具类有的存在挺多bug,这是我自己改用的过滤敏感词工具类,目前来说没啥bug,如果有bug欢迎在评论指出 使用前缀树 Trie 实现的过滤敏感词,树节点用静态内部类表示了,都写在一个 ...
- 快速上手ANTLR
回顾前文: ANTLR 简单介绍 ANTLR 相关术语 ANTLR 环境准备 下面通过两个实例来快速上手ANTLR. 使用Listener转换数组 完整源码见:https://github.com/b ...
- HyperSnips:VSCode上的自动补全神器
发现一个小众但是巨好用的VSCode自动补全插件:HyperSnips. 作者显然受到了 这位小哥 的启发,将 Vim Ultisnips 的大部分功能搬到了VSCode上.并用 JavaScript ...
- ciscn_2019_en_3
例行检查我就不放了,64位的程序放入ida中 可以看到s到buf的距离是0x10,因为puts是遇到\x00截止.而且题目没有限制我们s输入的数量,所以可以通过这个puts泄露出libc的基值 很明显 ...
- HSPICE 电平触发D触发器仿真
一. HSPICE的基本操作过程 打开HSPICE程序,通过OPEN打开编写好的网表文件. 按下SIMULATE进行网表文件的仿真. 按下AVANWAVES查看波形图(仿真结果). 二. 网表文件结构 ...
- Spring核心原理分析之MVC九大组件(1)
本文节选自<Spring 5核心原理> 1 什么是Spring MVC Spring MVC 是 Spring 提供的一个基于 MVC 设计模式的轻量级 Web 开发框架,本质上相当于 S ...
- java 输入输出IO流:标准输入/输出System.in;System.out;System.err;【重定向输入System.setIn(FileinputStream);输出System.setOut(printStream);】
Java的标准输入输出分别通过System.in和System.out来代表的,在默认情况下它分别代表键盘和显示器,当程序通过System.in来获取输入时,实际上是从键盘读取输入 当程序试图通过 S ...
- Java abstract 抽象类 和interface接口的异同点
abstract 抽象类 和interface接口的异同点 相同点: 抽象类和接口都不能实例化,他们都位于继承树顶端,被其他类实现和继承 都可以包含抽象方法,实现接口或者继承抽象类的非抽象类(普通类) ...
- Paramiko模块学习
#!/usr/bin/env python # Author:Zhangmingda import paramiko '''创建ssh对象''' ssh = paramiko.SSHClient() ...
- 网络编程之UDP(3)丢包总结
读书笔记 from here UDP socket缓冲区满造成的UDP丢包 如果socket缓冲区满了,应用程序没来得及处理在缓冲区中的UDP包,那么后续来的UDP包会被内核丢弃,造成丢包.在sock ...