mysql学习之完整的select语句
本文内容:
- 完整语法
- 去重选项
- 字段别名
- 数据源
- where
- group by
- having
- order by
- limit
首发日期:2018-04-11
完整语法:
先给一下完整的语法,后面将逐一来讲解。
基础语法:select 字段列表 from 数据源;
完整语法:select 去重选项 字段列表 [as 字段别名] from 数据源 [where子句] [group by 子句] [having子句] [order by 子句] [limit子句];
去重选项::
- 去重选项就是是否对结果中完全相同的记录(所有字段数据都相同)进行去重:
- all:不去重
- distinct:去重
- 语法:select 去重选项 字段列表 from 表名;
示例:
去重前: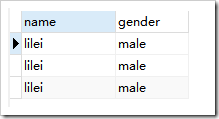 ,去重后
,去重后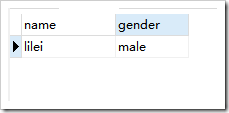
create table student(name varchar(15),gender varchar(15));
insert into student(name,gender) values("lilei","male");
insert into student(name,gender) values("lilei","male");
select * from student;
select distinct * from student;
补充:
- 注意:去重针对的是查询出来的记录,而不是存储在表中的记录。如果说仅仅查询的是某些字段,那么去重针对的是这些字段。
字段别名:
- 字段别名是给查询结果中的字段另起一个名字
- 字段别名只会在当次查询结果中生效。
- 字段别名一般都是辅助了解字段意义(比如我们定义的名字是name,我们希望返回给用户的结果显示成姓名)、简写字段名
- 语法:select 字段 as 字段别名 from 表名;
示例:
使用前: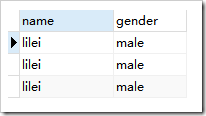 ,使用后
,使用后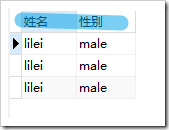
create table student(name varchar(15),gender varchar(15));
insert into student(name,gender) values("lilei","male");
insert into student(name,gender) values("lilei","male");
select * from student;
select name as "姓名",gender as "性别" from student;
数据源:
- 事实上,查询的来源可以不是“表名”,只需是一个二维表即可。那么数据来源可以是一个select结果。
- 数据源可以是单表数据源,多表数据源,以及查询语句
- 单表:select 字段列表 from 表名;
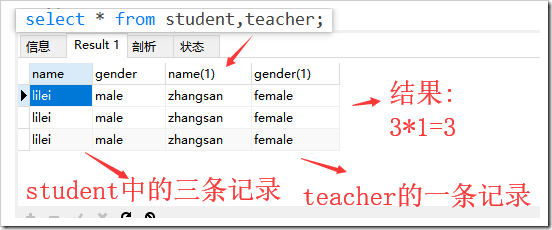
- 多表: select 字段列表 from 表名1,表名2,…; 【多表查询时是将每个表中的x条记录与另一个表y条记录组成结果,组成的结果的记录条数为x*y】【可以称为笛卡尔积】
- 查询语句:select 字段列表 fromr (select语句) as 表别名;【这是将一个查询结果作为一个查询的目标二维表,需要将查询结果定义成一个表别名才能作为数据源】
-- 示例
select name from (select * from student) as d;
where子句:
- where子句是用于筛选符合条件的结果的。
where几种语法:
- 基于值:
- = : where 字段 =值 ;查找出对应字段等于对应值的记录。(相似的,<是小于对应值,<=是小于等于对应值,>是大于对应值,>=是大于等于对应值,!=是不等于),例如:where name = 'lilei'
- like:where 字段 like 值 ;功能与 = 相似 ,但可以使用模糊匹配来查找结果。例如:where name like 'li%'
- = : where 字段 =值 ;查找出对应字段等于对应值的记录。(相似的,<是小于对应值,<=是小于等于对应值,>是大于对应值,>=是大于等于对应值,!=是不等于),例如:where name = 'lilei'
- 基于值的范围:
- in: where 字段 in 范围;查找出对应字段的值在所指定范围的记录。例如:where age in (18,19,20)
- not in : where 字段 not in 范围;查找出对应字段的值不在所指定范围的记录。例如:where age not in (18,19,20)
- between x and y :where 字段 between x and y;查找出对应字段的值在闭区间[x,y]范围的记录。例如:where age between 18 and 20。
- in: where 字段 in 范围;查找出对应字段的值在所指定范围的记录。例如:where age in (18,19,20)
- 条件复合:
- or : where 条件1 or 条件2… ; 查找出符合条件1或符合条件2的记录。
- and: where 条件1 and 条件2… ; 查找出符合条件1并且符合条件2的记录。
- not : where not 条件1 ;查找出不符合条件的所有记录。
- &&的功能与and相同;||与or功能类似,!与not 功能类似。
补充:
- where是从磁盘中获取数据的时候就进行筛选的。所以某些在内存是才有的东西where无法使用。(字段别名什么的是本来不是“磁盘中的数据”(是在内存这中运行时才定义的),所以where无法使用,一般都依靠having来筛选).
select name as n ,gender from student where name ="lilei";
-- select name as n ,gender from student where n ="lilei"; --报错
select name as n ,gender from student having n ="lilei";
group by 子句:
- group by 可以将查询结果依据字段来将结果分组。
- 语法:select 字段列表 from 表名 group by 字段;
- 【字段可以有多个,实际就是二次分组】

-- 示例
select name,gender,count(name) as "组员" from student as d group by name;
select name,gender,count(name) as "组员" from student as d group by name,gender;
补充:
- 实际上,group by 的作用主要是统计(使用情景很多,比如说统计某人的总分数,学生中女性的数量。。),所以一般会配合一些统计函数来使用:
- count(x):统计每组的记录数,x是*时代表记录数,为字段名时代表统计字段数据数(除去NULL)
- max(x):统计最大值,x是字段名
- min(x):统计最小值,x是字段名
- avg(x):统计平均值,x是字段名
- sum(x):统计总和,x是字段名
- group by 字段 后面还可以跟上asc或desc,代表分组后是否根据字段排序。
having子句:
- having功能与where类似,不过having的条件判断发生在数据在内存中时,所以可以使用在内存中才发生的数据,如“分组”,“字段别名”等。
- 语法:select 字段列表 from 表名 having 条件;【操作符之类的可以参考where的,增加的只是一些“内存”中的筛选条件】
-- 示例
select name as n ,gender from student having n ="lilei";
select name,gender,count(*) as "组员" from student as d group by name,gender having count(*) >2 ;-- 这里只显示记录数>2的分组
order by 子句:
- order by 可以使查询结果按照某个字段来排序
- 语法:select 字段列表 from 表名 order by 字段 [asc|desc];
- 字段可以有多个,从左到右,后面的排序基于前面的,(比如:先按name排序,再按gender排序,后面的gender排序是针对前面name排序时name相同的数据)
- asc代表排序是递增的
- desc代表是递减的
- 也可以指定某个字段的排序方法,比如第一个字段递增,第二个递减。只需要在每个字段后面加asc或desc即可(虽然默认不加是递增,但还是加上更清晰明确)。
-- 示例
select * from student order by name;
select * from student order by name,gender;
select * from student order by name asc,gender desc;
limit子句:
- limit是用来限制结果数量的。与where\having等配合使用时,可以限制匹配出的结果。但凡是涉及数量的时候都可以使用limit(这里只是强调limit的作用,不要过度理解)
- 语法:select 字段列表 from 表名 limit [offset,] count;
- count是数量
- offset是起始位置,offset从0开始,可以说是每条记录的索引号
-- 示例
select * from student limit 1;
select * from student limit 3,1;
select * from student where name ="lilei" limit 1;
select * from student where name ="lilei" limit 3,1;
mysql学习之完整的select语句的更多相关文章
- MySQL学习(二)SQL语句的总结
1.连接查询和关联查询连接查询:把两个表中相同的元素的连接就可以查询,使用:where里,select table1.*,table2.* from table1,table2 where table ...
- MySQL也有潜规则 – Select 语句不加 Order By 如何排序?
今天遇到一个问题,有一个 Select 语句没有加 "Order By",返回的数据是不确定的. 这种问题碰到不止几次了.追根寻底, Select 语句如果不加 "Ord ...
- MySql学习 (一) —— 基本数据库操作语句、三大列类型
注:该MySql系列博客仅为个人学习笔记. 在使用MySql的时候,基本都是用图形化工具,如navicat.最近发现连最基本的创建表的语法都快忘了... 所以,想要重新系统性的学习下MySql,为后面 ...
- oracle 10g 学习之基本 SQL SELECT 语句(4)
本篇文章中,对于有的和MSSQL Server相同的语法我就没有再写了,这里我只写Oracle和MSSQL Server有点不同的 定义空值 l 空值是无效的,未指定的,未知的或不可预知的值 l ...
- mysql学习(九)sql语句
SQL种类: DDL:数据定义语言 DML:数据操作语言 DQL:数据查询语言 DCL:数据控制语言 DDL: show databases; //查询数据库 create database if n ...
- SQL学习(三)Select语句:返回前多少行数据
在实际工作中,我们可能根据某种排序后,只需要显示前多少条数据,此时就需要根据不同的数据库,使用不同的关键字 一.SQL Server/Access select top 数量/百分比 from tab ...
- [ mysql优化一 ] explain解释select语句
NOSQL 没有什么数据表, 只是一些变量,key_value ,redis 支持的变量比较多.可以持久化文件到硬盘上. mysql 关系型数据库 ,表和表中间有各种id的关系. 缺点 高并发读 ...
- mysql使用pdo简单封装select语句
最终代码: function pdo_array_query($pdo, $table_name, $data, $fields=array('*')){ //Will contain SQL sni ...
- Mysql学习路线
本文内容: mysql学习路线 首发日期:2018-04-19 由于现在很多都是有api了,很多问题都转接到编程语言上来处理了,所以这篇mysql之路仅仅是作为“了解”之用.不深究mysql. 很多东 ...
随机推荐
- JwtBearer认证
ASP.NET Core 认证与授权[4]:JwtBearer认证 在现代Web应用程序中,通常会使用Web, WebApp, NativeApp等多种呈现方式,而后端也由以前的Razor渲染HT ...
- centos 7 linux 安装与卸载 tomcat 7
一.声明 本文采用操作系统版本: Centos 7 Linux系统 版本源:CentOS-7-x86_64-DVD-1708.iso 官网下载地址:http://isoredirect.centos. ...
- 我们来说一说TCP神奇的40ms
本文由云+社区发表 TCP是一个复杂的协议,每个机制在带来优势的同时也会引入其他的问题. Nagel算法和delay ack机制是减少发送端和接收端包量的两个机制, 可以有效减少网络包量,避免拥塞.但 ...
- datatables 配套bootstrap3样式使用小结(1)
今天介绍汇总一下datatables. 网址: www.datatables.net 公司CMS内容资讯站的后台管理界面用了大量的table来管理数据,试用了之后,感觉挺不错,推荐一下. 先上一个基本 ...
- JVM(二)—— 类加载机制
问题 1.为什么要有类加载机制(类加载机制的意义是什么) 2.类加载机制的过程,这些步骤可以颠倒顺序么?,每个步骤的作用是什么? 3.什么情况下必须对类进行初始化 类加载的过程 加载--验证--准备- ...
- SqlServer中循环和条件语句
if语句使用示例 declare @a int set @a=12 if @a>100 begin ...
- jdk的配置(适用于win7、win8、win10)
一.前言 win7和win8的jdk配置基本一样,所以本文以win7和win10来说明配置. 二.win7jdk环境配置(win8和这个一样) 首先安装好jdk,这里已安装好jdk7,本文采取的是jd ...
- a dive in react lifecycle
背景:我在react文档里找生命周期的图,居然没有,不敢相信我是在推特上找到的... 正文 react v16.3 新生命周期: static getDerivedStateFromProps get ...
- idea代码提示,不区分大小写
idea代码提示,不区分大小写:File-->Settings-->Editor-->General-->Code Completion-->Case sensitive ...
- angular post 带参数 导出excel
原文地址:http://www.cnblogs.com/xujanus/p/5985644.html html <button class="btn btn-info" ng ...