提取PPT文件中的Vba ProjectStg Compressed Atom。Extract PPT VBA Compress Stream
http://msdn.microsoft.com/en-us/library/cc313106(v=office.12).aspx 微软文档
PartI
******************************************************************************
简单讲一下如何找到VbaProjectStgCompressedAtom的偏移值
1、在.PPT文件中,搜索 5F C0 91 C3,
这个值后面的4字节long,就是
offsetToCurrentEdit-------------------------------------------------------------------
文档39页
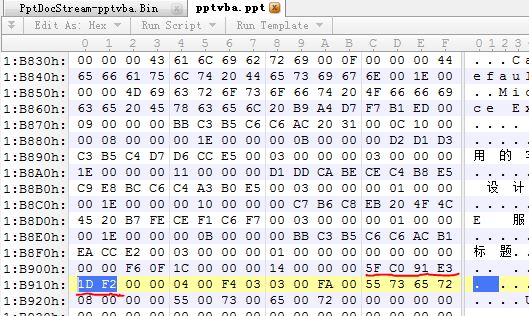
2、提取PPT文件中的 PowerPoint Document流,(具体方法略)
3、在PowerPoint Document流的offsetToCurrentEdit偏移处,找到offsetLastEdit为 00 00 00 00的位置,其后就是offsetPersistdirectory-------------文档41页
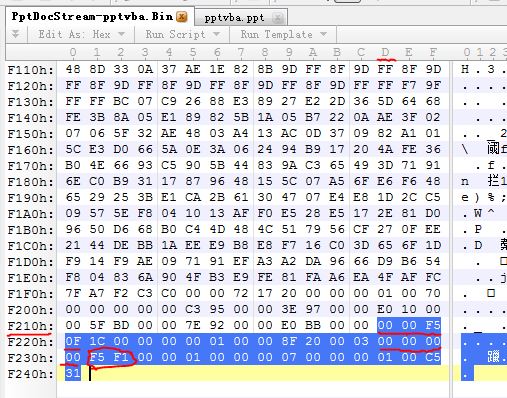
4、上图中,offsetPersistdirectory是F1F5,即PowerPoint Document流偏移为F1F5的位置开始,是Persistdirectory -------------------------------------文档42页
这里面包含了指示VBA Zlib流的偏移值,是个long数组(Persistdirectory Entry)
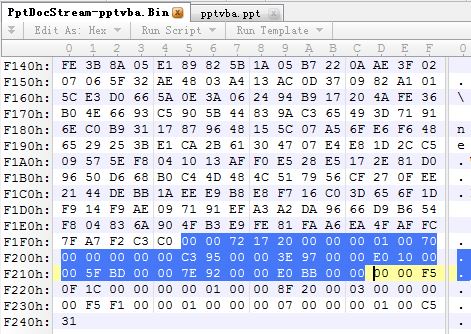
5、在PowerPoint Document流中,搜索0F 00 D0 07,找到DocInfoListContainer,这里面包含了VbaInfoContainer
在DocInfoListContainer起始位置,搜索1F 00 FF 03,这个就是VbaInfoContainer
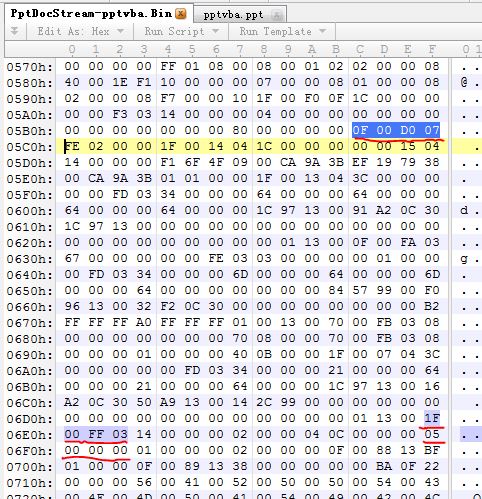
6、在VbaInfoContainer中,找到persisiIdRef的值
-----------------------------------------------------------------------------------------
文档57页
上图的05 00 00 00这个05就是第4步中,表示VBA Zlib流的的偏移值,在Persistdirectory Entry 数组中的下标。
7、在本例中,第4步图示数据的BD 5F就是VBA Zlib流的在PowerPoint Document流的偏移值。
也就是说,Persistdirectory Entry 数组下标为5的值是 5F BD 00 00 -------------------------------------------------------------文档43页

8、按照下面的方法,提取Deflate Raw之后,就可以解压缩,得到VBAProject.Bin。
PartII
*****************************************************************************************************
参考文档456页
1、参见PartI,查找10 00 11 10 得到压缩数据流起始位置。

2、数据流的格式如下:
10 00 11 10 XX XX XX XX (4字节rh.reclen, 压缩包的大小) XX XX XX XX (Uncompress Size 解压缩之后的大小) 78 9C (或78 01,表示Zlib的头)
... Raw数据流 ...
XX XX XX XX (4字节,采用Adler32算法的CRC checksum)
3、78 9C 后面的数据就是deflate的Raw数据流,长度是rh.reclen-6-4。在上图中,rh.reclen是7C 1E 00 00,也就是0x1E7C=7804个字节(十进制)。
实际的deflate的Raw数据流从Zlib头之后开始,长度为7804-6-4=7794,即1E72。最后是4字节的校验和(48 AF 2A 3A)。
4、在上图中,0x107b8+1E76-1-4=0x12629,即0x107B8~0x12629就是deflate的Raw数据流。最后的4个字节是Zlib的Adler32的CRC checksum。
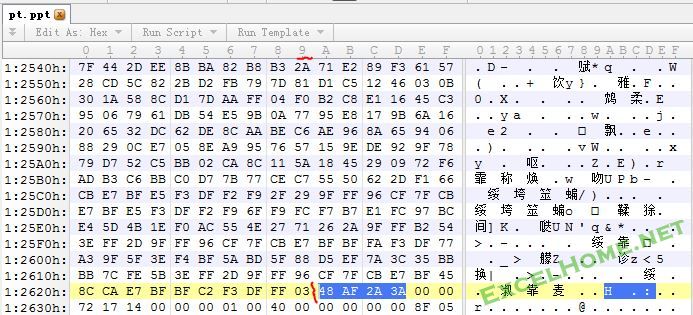
5、对0x107B8~0x12629的数据进行解压缩,就得到了PPT文件中的VBA Stream流。计算解压缩的文件CRC checksum,如果与 48 AF 2A 3A相同,说明解压缩正确。
注意:因为ppt里面的VBA Zlib流在文件中的存储可能不是连续的,需要提取 PowerPoint Document流之后,再参考上面的方法处理
***********************************************************************************************
Zlib 数据格式的说明
上楼说的Zlib头 78 9C:
78 =32K deflate压缩方法
9C= 10011100,具体参考下面的说明
Zlib 流有如下的结构:
0 1
+----+-----+
|CMF|FLG| (more-->)
+----+-----+
(if FLG.FDICT set)
0 1 2 3
+-----+-----+-----+-----+
| DICTID | (more-->)
+-----+-----+-----+-----+
+==============+-----+-----+-----+-----+
| ...compressed data... | ADLER32 |
+==============+-----+-----+-----+-----+
任何出现在 ADLER32 之后的数据都不是 zlib 流的一部分。
CMF(Compression Method and flags,压缩方法和标志)
这个字节分为一个 4 位的压缩方法和一个取决于压缩方法的 4 位信息域。
bits 0 to 3 CM Compression method
bits 4 to 7 CINFO Compression info
CM(Compression Method,压缩方法)
它在文件中用于标识压缩方法。CM = 8 表示窗口大小超过 32K 的“deflate”压缩方法。Gzip 和 png
(参见下面提供参考文档的第 3 章中参考资源 [1] 和 [2])使用这个方法。CM = 15
保留。它可能在本规范的将来版本中表示出现在压缩数据之前的附加域。
CINFO(Comression Info,压缩信息)
对于 CM = 8,CINFO 是 LZ77 窗口大小的以 2 为底的对数加上 8(CINFO = 7 表示窗口大小为 32
K)。是本规范中,并不允许 CINFO 的值在 7 以上。对于 CM 不等于 8 的 CINFO 在本规范中并没有定义。
FLG(FLaGs)
这个标志字节分为如下几个部分:
bits 0 to 4 FCHECK (检查 CMF 和 FLG 位)
bit 5 FDICT (预置字典)
bits 6 to 7 FLEVEL (压缩级别)
FCHECK 在当 CMF 和 FLG 被视为按 MSB 顺序存储的一个 16 位无符号整数(CMF*256 + FLG)时,必须是 31 的倍数。
FDICT(Preset dictionary,预置字典)
如果设置了 FDICT,DICT 字典标识符立即出现在 FLG
字节之后。字典是最初送到压缩程序而不产生任何压缩输出的一系列字节。DICT 是这一系列字节的 Adler-32 校验和(参见下面对
ADLER32 的定义)。解压缩程序可以使用这个标识符判断压缩程序使用了哪个字典。
FLEVEL(Compression level,压缩级别)
这些标志可用于特定的压缩方法。“Deflate”方法(CM = 8)将这些标志设置如下:
0 - 压缩程序使用最快的算法
1 - 压缩程序使用较快的算法
2 - 压缩程序使用缺少的算法
3 - 压缩程序使用最大的压缩,最慢的算法
对于解压缩程序来说,它并不需要 FLEVEL 中的信息;在解压缩程序中,让它表示是否要重新压缩可能更用价值。
压缩的数据(compressed data)
对于压缩方法 8,压缩的数据按照在由 L. Peter Deutsch 所写的文档“DEFLATE 压缩数据格式规范”(参见下面第 3 章参考资源[3])中说明的 deflate 压缩数据格式存储。
其它压缩的数据格式在 zlib 规范的这个版本中并不做说明。
ADLER32 (Adler-32 校验和,Adler-32 checksum)
这包含了一个按照 Adler-32 算法计算出的未压缩数据(除了任何字典数据)的校验值。这个算法是用在 ITU-T X.224 /
ISO 8073 标准中的 Fletcher 算法的 32 位扩展和改进。(请参见下面第 3 章的 [4] 和 [5])。
Alder-32 是由每个字节累积的两个和组成:s1 是所有字节的和,s2 是所有 s1 值的和。这两个和是 65521
取模得来。S1 初始值是 1,s2 是零。Adler-32 校验和按高位字节在先(网络字节序)的顺序存储为 s2*65536 + s1。
提取PPT文件中的Vba ProjectStg Compressed Atom。Extract PPT VBA Compress Stream的更多相关文章
- C#如何提取.txt文件中的每个字符串
C#如何提取.txt文件中的每个字符串,并将其存放到一个类中. 将其中的编号 菜名 价格 分别存入不同的数组中. 注:在用ReadLine读取一行信息时为什么读取的中文字符变成了乱码. 20 满意答案 ...
- Java 使用PDFBox提取PDF文件中的图片
今天做PDF文件解析,遇到一个需求:提取文件中的图片并保存.使用的是流行的apache开源jar包pdfbox, 但还是遇到坑了,比如pdfbox版本太高或太低都不能用!!这个包竟然没有很好地做好兼容 ...
- c# 提取word文件中的图片问题
最近遇到一个项目就是要从一份word中提取出所有的图片信息,功能看起来不是很难,只要使用office自带的Microsoft.Office.Interop.Word就可以解决问题.网上也有不少的文章来 ...
- Silverlight visifire Chart图表下载到PPT文件中
一.Silverlight xaml.cs文件 1. //下载图表 private void btnDown_Click(object sender, RoutedEventArgs e ...
- 使用CAJViewer 提取PDF文件中的文字
使用 CAJViewer 7.2 软件,把pdf格式的文件提取出文字. 操作步骤参考:http://jingyan.baidu.com/article/d45ad148cd06e469552b800f ...
- “PPT中如何插入和提取swf文件”的解决方案
解决方案: 如何在PPT中插入swf文件: 1.依次单击Office按钮,Powerpoint选项,勾选“在功能区显示‘开发工具’选项卡”后,确定: 2.单击“开发工具”选项卡中的“其他控件”按钮,然 ...
- Office系列(2)---提取Office文件(Word、PPT)中的所有图片
回顾一下上文结尾的问题:如何给文档设置一个合适的封面图?其中一个解决方案就是,获取Office文件内部的图片作为封面.这里就详细介绍下获取图片的几种方式,以及他们各自的优缺点. PS:因为之前用VST ...
- Office系列---将Office文件(Word、PPT、Excel)转换为PDF文件,提取Office文件(Word、PPT)中的所有图片
将Office文件转换为PDF文件,提取Office文件中的所有图片 1.Office系列---将Office文件(Word.PPT.Excel)转换为PDF文件 1.1 基于Office实现的解决方 ...
- [数据科学] 从csv, xls文件中提取数据
在python语言中,用丰富的函数库来从文件中提取数据,这篇博客讲解怎么从csv, xls文件中得到想要的数据. 点击下载数据文件http://seanlahman.com/files/databas ...
随机推荐
- 12.scrapy框架之递归解析和post请求
今日概要 递归爬取解析多页页面数据 scrapy核心组件工作流程 scrapy的post请求发送 今日详情 1.递归爬取解析多页页面数据 - 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久 ...
- React项目中那些奇怪的写法
1.在一个React组件里看到一个奇怪的写法: const {matchs} = this.props.matchs; 原来,是解构赋值,虽然听说过,但是看起来有点奇怪 下面做个实验: <scr ...
- linux下的文件目录结构
linux的文件系统是采用层级式的树状目录结构,在此结构中的最上层是根目录“/”,然后在此目录下再创建其他的目录 - root,存放root用户的相关文件 - home,存放普通用户的相关文件 - b ...
- 如何弄清Linux系统运行何种系统管理程序
如何弄清Linux系统运行何种系统管理程序 虽然我们经常听到系统管理器System Manager这词,但很少有人深究其确切意义.现在我们将向你展示其区别. 我会尽自己所能来解释清楚一切.我们大多都知 ...
- SQLite的sqlite3_prepare_v2
original SQL text---<sqlite3_prepare_v2>--->sqlite3_stmt--<sqlite3_reset>-->clear ...
- MYSQL学习笔记——sql语句优化工具
优化sql:思路: 使用explan->先查询type类型看看是all还是ref,然后判断 possible_keys (显示可能应用在这张表中的索引, 一个或多个.查询涉及到的字段是若存在索引 ...
- ubantu搭建oj——第一天(6.11)
oj第一份作业: 按照DMOJ的文档将代码搬运到ubantu上 sudo apt install git gcc g++ make python-dev libxml2-dev libxslt1-de ...
- 004_centos安装pip的几种方式及pip源
一. (1) yum -y install epel-release yum install python-pip pip install --upgrade pip (2) python脚本的一键安 ...
- Linux Driver 开发 eclipse工程找不到头文件
如下添加头文件路径, 右键单击工程,选择 Properties > C/C++ Build > Settings > > GCC C/C++ Compiler ...
- mybatis 参数为list时,校验list是否为空, mybatis ${}与#{}的区别
一.参数list时,先判断是否为空,否则会报错. 二.mybatis ${}与#{}的区别 简单来说#{} 解析的是占位符?可以防止SQL注入, 比如打印出来的语句 select * from tab ...