Hadoop生态上几个技术的解释:hive、pig、hbase 关系与区别
hadoop生态圈
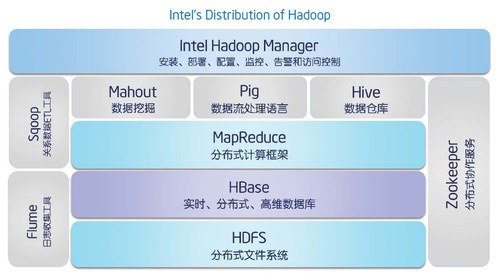
Pig
一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了。当初雅虎自己慢慢退出pig的维护之后将它开源贡献到开源社区由所有爱好者来维护。不过现在还是有些公司在用,不过我认为与其使用pig不如使用hive。:)
Pig是一种数据流语言,用来快速轻松的处理巨大的数据。
Pig包含两个部分:Pig Interface,Pig Latin。
Pig可以非常方便的处理HDFS和HBase的数据,和Hive一样,Pig可以非常高效的处理其需要做的,通过直接操作Pig查询可以节省大量的劳动和时间。当你想在你的数据上做一些转换,并且不想编写MapReduce jobs就可以用Pig.
Hive
不想用程序语言开发MapReduce的朋友比如DB们,熟悉SQL的朋友可以使用Hive开离线的进行数据处理与分析工作。
注意Hive现在适合在离线下进行数据的操作,就是说不适合在挂在真实的生产环境中进行实时的在线查询或操作,因为一个字“慢”。相反
起源于FaceBook,Hive在Hadoop中扮演数据仓库的角色。建立在Hadoop集群的最顶层,对存储在Hadoop群上的数据提供类SQL的接口进行操作。你可以用 HiveQL进行select,join,等等操作。
如果你有数据仓库的需求并且你擅长写SQL并且不想写MapReduce jobs就可以用Hive代替。
HBase
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现。HBase以Google BigTable为蓝本,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
HBase是一个数据库,一个NoSql的数据库,像其他数据库一样提供随即读写功能,Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase。
你可以用Hadoop作为静态数据仓库,HBase作为数据存储,放那些进行一些操作会改变的数据。
Pig VS Hive
Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使 其成为Hadoop与其他BI工具结合的理想交集。
Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的 应用程序。
Pig相比Hive相对轻量,它主要的优势是相比于直接使用Hadoop Java APIs可大幅削减代码量。正因为如此,Pig仍然是吸引大量的软件开发人员。
Hive和Pig都可以与HBase组合使用,Hive和Pig还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单
Hive VS HBase
Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
Hadoop生态上几个技术的解释:hive、pig、hbase 关系与区别的更多相关文章
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别 Pig
Hadoop生态上几个技术的关系与区别:hive.pig.hbase 关系与区别 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的 ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
初接触Hadoop技术的朋友肯定会对它体系下寄生的个个开源项目糊涂了,我敢保证Hive,Pig,HBase这些开源技术会把你搞的有些糊涂,不要紧糊涂的不止你一个,如某个菜鸟的帖子的疑问,when to ...
- 【转载】Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
转自:http://www.linuxidc.com/Linux/2014-03/98978.htm Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎 ...
- Hadoop Hive与Hbase关系 整合
用hbase做数据库,但因为hbase没有类sql查询方式,所以操作和计算数据很不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库 1. 基于Ha ...
- hadoop生态搭建(3节点)-07.hive配置
# http://archive.apache.org/dist/hive/hive-2.1.1/ # ================================================ ...
- EDW on Hadoop(Hadoop上的数据仓库)技术选型和实践思考
在这篇文章中, 将讨论EDW on Hadoop 有哪些备选方案, 以及我个人的倾向性, 最后是建构方法. 欢迎转载, 但必须注明原贴(刘忠武, http://www.cnblogs.com/ha ...
- SQL on Hadoop中用到的主要技术——MPP vs Runtime Framework
转载声明 本文转载自盘点SQL on Hadoop中用到的主要技术,个人觉得该文章对于诸如Impala这样的MPP架构的SQL引擎和Runtime Framework架构的Hive/Spark SQL ...
- 盘点SQL on Hadoop中用到的主要技术
转载自:http://sunyi514.github.io/2014/11/15/%E7%9B%98%E7%82%B9sql-on-hadoop%E4%B8%AD%E7%94%A8%E5%88%B0% ...
- 安装高可用Hadoop生态 (一 ) 准备环境
为了学习Hadoop生态的部署和调优技术,在笔记本上的3台虚拟机部署Hadoop集群环境,要求保证HA,即主要服务没有单点故障,能够执行最基本功能,完成小内存模式的参数调整. 1. 准备环境 1 ...
随机推荐
- Learning to act by predicting the future
Dosovitskiy, Alexey, and Vladlen Koltun. "Learning to act by predicting the future." arXiv ...
- (转)MFC:Windows如何区分鼠标双击和两次单击
在Windows平台上,鼠标左键的按下.松开.快速的两次点击会产生WM_LBUTTONDOWN.WM_LBUTTONUP和WM_LBUTTONDBLCLK消息,但是Windows根据什么来区分连续的两 ...
- Python的类和函数的魔法
class CustomClass: def customFun(self, id): print("fun_1",id ) if __name__ == '__main__': ...
- CentOS7忘记root密码的解决方法
开机启动centos 7.0,看到如下画面,选择下图选单,按"e"键 在下图linux16行中,将ro这两个字母修改为rw init=/sysroot/bin/sh 修改结果如下图 ...
- R基本介绍
一.基本介绍:1. 警告:在输入命令前请切换到英文模式.否则你的一大段代码可能因为一个中文状态的括号而报错,R语言的报错并不智能无法指出错误的具体位置.最可怕的是不报错但就是无法输出正确结果.2. 警 ...
- android 近百个源码项目
http://www.cnblogs.com/helloandroid/articles/2385358.html
- Javascript继承机制总结 [转]
转自:http://bbs.csdn.net/topics/260051906 Javascript继承 一直想对Javascript再次做一些总结,正好最近自己写了一个小型Js UI库,总结了一下J ...
- web.xml 中的listener、filter、servlet 加载顺序及其【配置详解】
在项目中总会遇到一些关于加载的优先级问题,近期也同样遇到过类似的,所以自己查找资料总结了下,下面有些是转载其他人的,毕竟人家写的不错,自己也就不重复造轮子了,只是略加点了自己的修饰. 首先可以肯定的是 ...
- (转载)用vs2010开发基于VC++的MFC 串口通信一*****两台电脑同一个串口号之间的通信
此文章以visual C++数据採集与串口通信測控应用实战为參考教程 此文章适合VC++串口通信入门 一.页面布局及加入控件 1, 安装好vs2010如图 2, 新建一个基于VC++的MFC项目com ...
- 工作流JBPM_day01:4-管理流程定义
工作流JBPM_day01:4-管理流程定义 管理流程(流程定义) 部署(添加) 查询 删除 查看流程图(xxx.png) -- 修改 --> 没有真正的修改,而是使用“再次部署+使用最新版本启 ...