Hadoop生态上几个技术的解释:hive、pig、hbase 关系与区别
hadoop生态圈
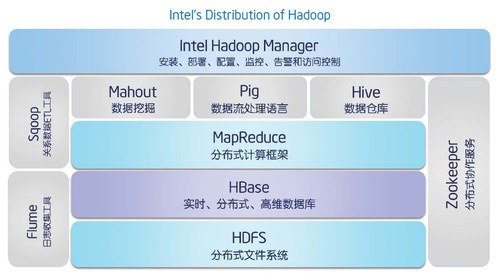
Pig
一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了。当初雅虎自己慢慢退出pig的维护之后将它开源贡献到开源社区由所有爱好者来维护。不过现在还是有些公司在用,不过我认为与其使用pig不如使用hive。:)
Pig是一种数据流语言,用来快速轻松的处理巨大的数据。
Pig包含两个部分:Pig Interface,Pig Latin。
Pig可以非常方便的处理HDFS和HBase的数据,和Hive一样,Pig可以非常高效的处理其需要做的,通过直接操作Pig查询可以节省大量的劳动和时间。当你想在你的数据上做一些转换,并且不想编写MapReduce jobs就可以用Pig.
Hive
不想用程序语言开发MapReduce的朋友比如DB们,熟悉SQL的朋友可以使用Hive开离线的进行数据处理与分析工作。
注意Hive现在适合在离线下进行数据的操作,就是说不适合在挂在真实的生产环境中进行实时的在线查询或操作,因为一个字“慢”。相反
起源于FaceBook,Hive在Hadoop中扮演数据仓库的角色。建立在Hadoop集群的最顶层,对存储在Hadoop群上的数据提供类SQL的接口进行操作。你可以用 HiveQL进行select,join,等等操作。
如果你有数据仓库的需求并且你擅长写SQL并且不想写MapReduce jobs就可以用Hive代替。
HBase
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现。HBase以Google BigTable为蓝本,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
HBase是一个数据库,一个NoSql的数据库,像其他数据库一样提供随即读写功能,Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase。
你可以用Hadoop作为静态数据仓库,HBase作为数据存储,放那些进行一些操作会改变的数据。
Pig VS Hive
Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似促使 其成为Hadoop与其他BI工具结合的理想交集。
Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的 应用程序。
Pig相比Hive相对轻量,它主要的优势是相比于直接使用Hadoop Java APIs可大幅削减代码量。正因为如此,Pig仍然是吸引大量的软件开发人员。
Hive和Pig都可以与HBase组合使用,Hive和Pig还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单
Hive VS HBase
Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
Hadoop生态上几个技术的解释:hive、pig、hbase 关系与区别的更多相关文章
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别 Pig
Hadoop生态上几个技术的关系与区别:hive.pig.hbase 关系与区别 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的 ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
初接触Hadoop技术的朋友肯定会对它体系下寄生的个个开源项目糊涂了,我敢保证Hive,Pig,HBase这些开源技术会把你搞的有些糊涂,不要紧糊涂的不止你一个,如某个菜鸟的帖子的疑问,when to ...
- 【转载】Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
转自:http://www.linuxidc.com/Linux/2014-03/98978.htm Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎 ...
- Hadoop Hive与Hbase关系 整合
用hbase做数据库,但因为hbase没有类sql查询方式,所以操作和计算数据很不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库 1. 基于Ha ...
- hadoop生态搭建(3节点)-07.hive配置
# http://archive.apache.org/dist/hive/hive-2.1.1/ # ================================================ ...
- EDW on Hadoop(Hadoop上的数据仓库)技术选型和实践思考
在这篇文章中, 将讨论EDW on Hadoop 有哪些备选方案, 以及我个人的倾向性, 最后是建构方法. 欢迎转载, 但必须注明原贴(刘忠武, http://www.cnblogs.com/ha ...
- SQL on Hadoop中用到的主要技术——MPP vs Runtime Framework
转载声明 本文转载自盘点SQL on Hadoop中用到的主要技术,个人觉得该文章对于诸如Impala这样的MPP架构的SQL引擎和Runtime Framework架构的Hive/Spark SQL ...
- 盘点SQL on Hadoop中用到的主要技术
转载自:http://sunyi514.github.io/2014/11/15/%E7%9B%98%E7%82%B9sql-on-hadoop%E4%B8%AD%E7%94%A8%E5%88%B0% ...
- 安装高可用Hadoop生态 (一 ) 准备环境
为了学习Hadoop生态的部署和调优技术,在笔记本上的3台虚拟机部署Hadoop集群环境,要求保证HA,即主要服务没有单点故障,能够执行最基本功能,完成小内存模式的参数调整. 1. 准备环境 1 ...
随机推荐
- e665. 在图像中过滤三元色
This example demonstrates how to create a filter that can modify any of the RGB pixel values in an i ...
- LINUX下CPU Load Average的一点研究
背景: 公司的某个系统工作在基于Linux的Cent OS下,一个host下同时连接了许多client, 最近某台Host总是显示CPU Load Average过高,我们单纯的以为是CPU的占用过高 ...
- 资深投资人全力反击: VC增值平台从来就不是一坨狗屎
编者注: 本文来自海外著名科技博客VentureBeat, 英文原文出自Kyle Lacy之手 ,中文版由天地会珠海分舵进行编译. 文章主要是针对前几天德国VC Christian Claussen的 ...
- Css中position、float和clear整理
Position: absolute 生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定位. 元素的位置通过 "left", "top", ...
- Spring MVC异常统一处理
package com.shzq.common.exception; import java.io.PrintWriter;import java.io.StringWriter;import jav ...
- oracle数据备份
from:http://www.docin.com/p-728428621.html
- List自定义排序
List自定义排序我习惯根据Collections.sort重载方法来实现,下面我只实现自己习惯方式.还有一种就是实现Comparable接口. 挺简单的,直接上代码吧. package com.so ...
- OnGlobalLayoutListener用法
1.implements ViewTreeObserver.OnGlobalLayoutListener{} 2.mContentView.getViewTreeObserver().addOnGlo ...
- 新唐M0 M4系统初始化
系统初始化包含了时钟(clock)初始化和多功能引脚(Multi Function Pin 简称MFP寄存器)配置.void SYS_Init(void) { /* 解锁保护寄存器 */ SYS_Un ...
- iPad UIPopoverController弹出窗口的位置和坐标
本文转载至:http://blog.csdn.net/chang6520/article/details/7921181 TodoViewController *contentViewControll ...