Solr相似度算法二:Okapi BM25
In information retrieval, Okapi BM25 (BM stands for Best Matching) is a ranking function used by search engines to rank matching documents according to their relevance to a given search query. It is based on the probabilistic retrieval framework developed in the 1970s and 1980s byStephen E. Robertson, Karen Spärck Jones, and others.
The name of the actual ranking function is BM25. To set the right context, however, it usually referred to as "Okapi BM25", since the Okapi information retrieval system, implemented at London's City University in the 1980s and 1990s, was the first system to implement this function.
BM25, and its newer variants, e.g. BM25F (a version of BM25 that can take document structure and anchor text into account), represent state-of-the-art TF-IDF-like retrieval functions used in document retrieval, such as web search.
The ranking function[edit]
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of the inter-relationship between the query terms within a document (e.g., their relative proximity). It is not a single function, but actually a whole family of scoring functions, with slightly different components and parameters. One of the most prominent instantiations of the function is as follows.
Given a query 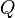 , containing keywords
, containing keywords 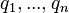 , the BM25 score of a document
, the BM25 score of a document  is:
is:
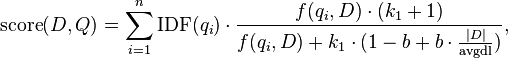
where  is
is 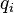 's term frequency in the document ,
's term frequency in the document ,  is the length of the document in words, and
is the length of the document in words, and 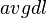 is the average document length in the text collection from which documents are drawn.
is the average document length in the text collection from which documents are drawn. 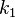 and
and  are free parameters, usually chosen, in absence of an advanced optimization, as
are free parameters, usually chosen, in absence of an advanced optimization, as 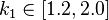 and
and 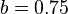 .[1]
.[1] 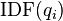 is the IDF (inverse document frequency) weight of the query term . It is usually computed as:
is the IDF (inverse document frequency) weight of the query term . It is usually computed as:
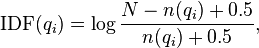
where  is the total number of documents in the collection, and
is the total number of documents in the collection, and 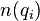 is the number of documents containing .
is the number of documents containing .
There are several interpretations for IDF and slight variations on its formula. In the original BM25 derivation, the IDF component is derived from the Binary Independence Model.
Please note that the above formula for IDF shows potentially major drawbacks when using it for terms appearing in more than half of the corpus documents. These terms' IDF is negative, so for any two almost-identical documents, one which contains the term and one which does not contain it, the latter will possibly get a larger score. This means that terms appearing in more than half of the corpus will provide negative contributions to the final document score. This is often an undesirable behavior, so many real-world applications would deal with this IDF formula in a different way:
- Each summand can be given a floor of 0, to trim out common terms;
- The IDF function can be given a floor of a constant
 , to avoid common terms being ignored at all;
, to avoid common terms being ignored at all; - The IDF function can be replaced with a similarly shaped one which is non-negative, or strictly positive to avoid terms being ignored at all.
IDF information theoretic interpretation[edit]
Here is an interpretation from information theory. Suppose a query term  appears in
appears in 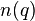 documents. Then a randomly picked document will contain the term with probability
documents. Then a randomly picked document will contain the term with probability 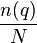 (where is again the cardinality of the set of documents in the collection). Therefore, the informationcontent of the message " contains " is:
(where is again the cardinality of the set of documents in the collection). Therefore, the informationcontent of the message " contains " is:

Now suppose we have two query terms  and
and 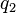 . If the two terms occur in documents entirely independently of each other, then the probability of seeing both and in a randomly picked document is:
. If the two terms occur in documents entirely independently of each other, then the probability of seeing both and in a randomly picked document is:

and the information content of such an event is:
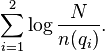
With a small variation, this is exactly what is expressed by the IDF component of BM25.
Modifications[edit]
- At the extreme values of the coefficient BM25 turns into ranking functions known as BM11 (for
 ) and BM15 (for
) and BM15 (for 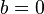 ).[2]
).[2] - BM25F[3] is a modification of BM25 in which the document is considered to be composed from several fields (such as headlines, main text, anchor text) with possibly different degrees of importance.
- BM25+[4] is an extension of BM25. BM25+ was developed to address one deficiency of the standard BM25 in which the component of term frequency normalization by document length is not properly lower-bounded; as a result of this deficiency, long documents which do match the query term can often be scored unfairly by BM25 as having a similar relevancy to shorter documents that do not contain the query term at all. The scoring formula of BM25+ only has one additional free parameter
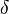 (a default value is
(a default value is 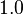 in absence of a training data) as compared with BM25:
in absence of a training data) as compared with BM25:
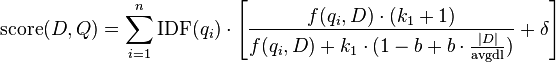
Solr相似度算法二:Okapi BM25的更多相关文章
- Solr相似度算法二:BM25Similarity
BM25算法的全称是 Okapi BM25,是一种二元独立模型的扩展,也可以用来做搜索的相关度排序. Sphinx的默认相关性算法就是用的BM25.Lucene4.0之后也可以选择使用BM25算法(默 ...
- Solr相似度算法三:DRFSimilarity框架介绍
地址:http://terrier.org/docs/v3.5/dfr_description.html The Divergence from Randomness (DFR) paradigm i ...
- elasticsearch算法之词项相似度算法(二)
六.莱文斯坦编辑距离 前边的几种距离计算方法都是针对相同长度的词项,莱文斯坦编辑距离可以计算两个长度不同的单词之间的距离:莱文斯坦编辑距离是通过添加.删除.或者将一个字符替换为另外一个字符所需的最小编 ...
- Solr相似度算法四:IBSimilarity
Information based:它与Diveragence from randomness模型非常相似.与DFR相似度模型类似,据说该模型也适用于自然语言类的文本.
- Solr相似度算法三:DRFSimilarity
该Similarity 实现了 divergence from randomness (偏离随机性)框架,这是一种基于同名概率模型的相似度模型. 该 similarity有以下配置选项: basic ...
- Okapi BM25算法
引言 Okapi BM25,一般简称 BM25 算法,在 20 世纪 70 年代到 80 年代,由英国一批信息检索领域的计算机科学家发明.这里的 BM 是"最佳匹配"(Best M ...
- ES BM25 TF-IDF相似度算法设置——
Pluggable Similarity Algorithms Before we move on from relevance and scoring, we will finish this ch ...
- TensorFlow 入门之手写识别(MNIST) softmax算法 二
TensorFlow 入门之手写识别(MNIST) softmax算法 二 MNIST Fly softmax回归 softmax回归算法 TensorFlow实现softmax softmax回归算 ...
- elasticsearch算法之词项相似度算法(一)
一.词项相似度 elasticsearch支持拼写纠错,其建议词的获取就需要进行词项相似度的计算:今天我们来通过不同的距离算法来学习一下词项相似度算法: 二.数据准备 计算词项相似度,就需要首先将词项 ...
随机推荐
- Thymeleaf系列五 迭代,if,switch语法
1. 概述 这里介绍thymeleaf的编程语法,本节主要包括如下内容 迭代语法:th:each; iteration status 条件语法:th:if; th:unless switch语法: ...
- MVC框架介绍
第一,建立一个解决方案然后在该解决方案下面新建mvc空项目. 第二,下面先对该项目的一些文件进行介绍: MVC项目文件夹说明: 1.(App_Data):用来保存数据文件,比如XML文件等 2.(Ap ...
- 【常见CPU架构对比】维基百科
Comparison of instruction set architectures https://en.wikipedia.org/wiki/Comparison_of_instruction_ ...
- java中getAttribute和getParameter的区别
getAttribute表示从request范围取得设置的属性,必须要先setAttribute设置属性,才能通过getAttribute来取得,设置与取得的为Object对象类型 getParame ...
- 迷你MVVM框架 avalonjs 学习教程6、插入移除处理
ms-if是属于流程绑定的一种,如果表达式为真值那么就将当前元素输出页面,不是就将它移出DOM树.它的效果与上一章节的ms-visible效果看起来相似的,但它会影响到:empty伪类,并能更节约性能 ...
- Linux 入侵检测
一.检查系统日志 检查系统错误登陆日志,统计IP重试次数 # 这里使用了lastb命令,该命令需要root权限,可以显示所有登陆信息.这里仅仅显示的root用户的,读者可以更具实际情况自行确定,或者直 ...
- Hadoop之MapReduce学习笔记(一)
主要内容:mapreduce整体工作机制介绍:wordcont的编写(map逻辑 和 reduce逻辑)与提交集群运行:调度平台yarn的快速理解以及yarn集群的安装与启动. 1.mapreduce ...
- Python next() 函数
Python next() 函数 Python 内置函数 描述 next() 返回迭代器的下一个项目. 语法 next 语法: next(iterator[, default]) 参数说明: ite ...
- 搭建简单的Spring框架
1.Spring框架相关jar包下载地址http://repo.springsource.org/libs-release-local/org/springframework/spring,复制,进入 ...
- 29. Divide Two Integers (INT; Overflow, Bit)
Divide two integers without using multiplication, division and mod operator. If it is overflow, retu ...