机器学习:衡量线性回归法的指标(MSE、RMSE、MAE、R Squared)
一、MSE、RMSE、MAE
- 思路:测试数据集中的点,距离模型的平均距离越小,该模型越精确
- # 注:使用平均距离,而不是所有测试样本的距离和,因为距离和受样本数量的影响
1)公式:
- MSE:均方误差

- RMSE:均方根误差

- MAE:平均绝对误差

二、具体实现
1)自己的代码
import numpy as np
from sklearn.metrics import r2_score class SimpleLinearRegression: def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None def fit(self, x_train, y_train):
"""根据训练数据集x_train, y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train" x_mean = np.mean(x_train)
y_mean = np.mean(y_train) self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean)
self.b_ = y_mean - self.a_ * x_mean return self def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!" return np.array([self._predict(x) for x in x_predict]) def _predict(self, x_single):
"""给定单个待预测数据x,返回x的预测结果值"""
return self.a_ * x_single + self.b_ def score(self, x_test, y_test):
"""根据测试数据集 x_test 和 y_test 确定当前模型的准确度:R^2""" y_predict = self.predict(x_test)
return r2_score(y_test, y_predict) def __repr__(self):
return "SimpleLinearRegression()"
2)调用scikit-learn中的算法
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error # MSE
mse_predict = mean_squared_error(y_test, y_predict) # MAE
mae_predict = mean_absolute_error(y_test, y_predict) # y_test:测试数据集中的真实值
# y_predict:根据测试集中的x所预测到的数值
3)RMSE和MAE的比较
- 量纲一样:都是原始数据中y对应的量纲
- RMSE > MAE:
# 这是一个数学规律,一组正数的平均数的平方,小于每个数的平方和的平均数;
四、最好的衡量线性回归法的指标:R Squared
- 准确度:[0, 1],即使分类的问题不同,也可以比较模型应用在不同问题上所体现的优劣;
- RMSE和MAE有局限性:同一个算法模型,解决不同的问题,不能体现此模型针对不同问题所表现的优劣。因为不同实际应用中,数据的量纲不同,无法直接比较预测值,因此无法判断模型更适合预测哪个问题。
- 方案:将预测结果转换为准确度,结果都在[0, 1]之间,针对不同问题的预测准确度,可以比较并来判断此模型更适合预测哪个问题;
1)计算方法

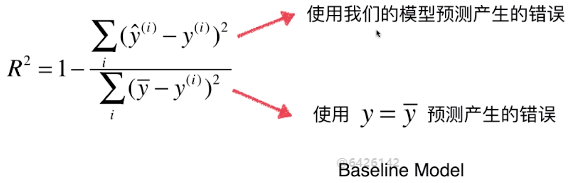
2)对公式的理解
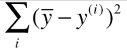 :公式样式与MSE类似,可以理解为一个预测模型,只是该模型与x无关,在机器学习领域称这种模型为基准模型(Baseline Model),适用于所有的线型回归算法;
:公式样式与MSE类似,可以理解为一个预测模型,只是该模型与x无关,在机器学习领域称这种模型为基准模型(Baseline Model),适用于所有的线型回归算法;- 基准模型问题:因为其没有考虑x的取值,只是很生硬的以为所有的预测样本,其预测结果都是样本均值
A)因此对公式可以这样理解:
- 分子是我们的模型预测产生的错误,分母是使用y等于y的均值这个模型所产生的错误
- 自己的模型预测产生的错误 / 基础模型预测生产的错误,表示自己的模型没有拟合住的数据,因此R2可以理解为,自己的模型拟合住的数据
B)公式推理结论:
- R2 <= 1
- R2越大越好,当自己的预测模型不犯任何错误时:R2 = 1
- 当我们的模型等于基准模型时:R2 = 0
- 如果R2 < 0,说明学习到的模型还不如基准模型。 # 注:很可能数据不存在任何线性关系
3)公式变形
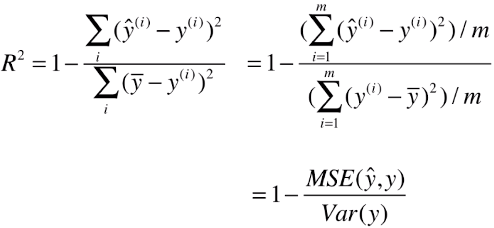
- R2背后具有其它统计意思
4)R2的代码实现及使用
具体代码:
1 - mean_squared_error(y_true, y_predict) / np.var(y_true) # mean_squared_error()函数就是MSE
# np.var(array):求向量的方差- 调用scikit-learn中的r2_score()函数:
from sklearn.metrics import r2_score r2_score(y_test, y_predict) # y_test :测试数据集中的真实值
# y_predict:预测到的数据
机器学习:衡量线性回归法的指标(MSE、RMSE、MAE、R Squared)的更多相关文章
- 衡量线性回归法的指标MSE, RMSE,MAE和R Square
衡量线性回归法的指标:MSE, RMSE和MAE 举个栗子: 对于简单线性回归,目标是找到a,b 使得尽可能小 其实相当于是对训练数据集而言的,即 当我们找到a,b后,对于测试数据集而言 ,理所当然, ...
- 【笔记】衡量线性回归法的指标 MSE,RMS,MAE以及评价回归算法 R Square
衡量线性回归法的指标 MSE,RMS,MAE以及评价回归算法 R Square 衡量线性回归法的指标 对于分类问题来说,我们将原始数据分成了训练数据集和测试数据集两部分,我们使用训练数据集得到模型以后 ...
- 机器学习:线性回归法(Linear Regression)
# 注:使用线性回归算法的前提是,假设数据存在线性关系,如果最后求得的准确度R < 0,则说明很可能数据间不存在任何线性关系(也可能是算法中间出现错误),此时就要检查算法或者考虑使用其它算法: ...
- 线性回归中常见的一些统计学术语(RSE RSS TSS ESS MSE RMSE R2 Pearson's r)
TSS: Total Sum of Squares(总离差平方和) --- 因变量的方差 RSS: Residual Sum of Squares (残差平方和) --- 由误差导致的真实值和估计值 ...
- 机器学习之线性回归(纯python实现)][转]
本文转载自:https://juejin.im/post/5a924df16fb9a0634514d6e1 机器学习之线性回归(纯python实现) 线性回归是机器学习中最基本的一个算法,大部分算法都 ...
- 可决系数R^2和MSE,MAE,SMSE
波士顿房价预测 首先这个问题非常好其实要完整的回答这个问题很有难度,我也没有找到一个完整叙述这个东西的资料,所以下面主要是结合我自己的理解和一些资料谈一下r^2,mean square error 和 ...
- 机器学习算法的基本知识(使用Python和R代码)
本篇文章是原文的译文,然后自己对其中做了一些修改和添加内容(随机森林和降维算法).文章简洁地介绍了机器学习的主要算法和一些伪代码,对于初学者有很大帮助,是一篇不错的总结文章,后期可以通过文中提到的算法 ...
- 第3章 衡量线性回归的指标:MSE,RMSE,MAE
, , ,, , , ,
- C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)
写在前面的话: 在第一学期做项目的时候用到过相应的知识,觉得挺有趣的,就记录整理了下来,基于C/C++语言 原贴地址:https://helloacm.com/cc-linear-regression ...
随机推荐
- MATLAB常用指令记录
help + 'command name' % 查询指令用法 Ctrl + Break % 强制终止程序运行 Shift + Enter % command window下换行不运行指令 M'; % ...
- Cisco学习笔记
目录 1. 路由 1.1 静态路由 1.2 动态路由 2. 访问控制列表 2.1 标准访问控制列表 2.2 扩展访问控制列表 2.3 命名访问控制列表 3. VLAN 3.1 基础知识 3.2 配置实 ...
- oracle 字典表查询
1.oracle 字典表查询 /*显示当前用户*/ show user 在sql plus中可用,在pl sql中不可用 /*查看所有用户名*/ select username,user_id,cre ...
- Centos6.5安装Mysql5.6.10
1. 先卸载掉老版本的mysql(linux严格区分大小写,查找的时候加上-i参数,和mysql相关的全部要卸) [root@liuchao ~]# rpm -qa | grep -i mysqlMy ...
- Java 关于final那些事
先说结论:对于引用类型的变量,Java本身会创建两个东西,一个是对象本身,另一个是记录对象地址的一个int值,将引用类型的对象声明为final实际上是固定记录地址的那个int的值不能改变,如果通过某种 ...
- LeetCode——same-tree
Question Given two binary trees, write a function to check if they are equal or not. Two binary tree ...
- ansible实现发布、回滚功能
ansible的两篇博客,本来是打算合二为一的,发现只用一篇写,嗯,好鬼长.... 一向秉承简单为美的我于是忍痛割爱,一分为二了 ansible实现升级发布.回滚功能 1.应用场景 在实际生产环境中, ...
- 我的博客搬家到https://www.w2le.com/了
大家以后想看我的博文的请到这里哦,欢迎大家访问https://www.w2le.com/
- PHP版微信第三方实现一键登录及获取用户信息的方法
本文实例讲述了PHP版微信第三方实现一键登录及获取用户信息的方法.分享给大家供大家参考,具体如下: 注意,要使用微信在第三方网页登录是需要“服务号”才可以哦,所以必须到官方申请. 一开始你需要进入微信 ...
- 使用Fluentd + MongoDB构建实时日志收集系统
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方. 目前开源社区已经贡献了下面一些存储插件:MongoDB, Redis, Couch ...