KDtree浅谈
KDtree浅谈
1.对KDtree的理解
首先要知道$KDtree$的用处,$KDtree$是用来进行多维数点的,一般这些点都是在在而二维及二维以上,因为一维上的问题,我们基本都可以运用线段树来解决。我对$KDtree$的理解就是一个自带剪枝的暴力,并且这个剪枝因为我们对这些多维上的点的较优秀的排列而显得十分有用。
2.前置知识
在学习$KDtree$之前要先知道并会运用西面三个知识点:
1) 首先,要会建二叉搜索树,因为整个$KDtree$就是一颗二叉搜索树。
2) 还需要知道什么事估价函数,因为剪枝的时候要运用到估价函数。
3) 对空间的想象能力,因为$KDtree$是处理图形上的问题,所以还需要有一定的空间想象能力。
3.KDTree的讲解
因为$KDtree$是一种优美的暴力,并且我们要在上面剪枝,所以我们自然想让每一次剪枝,剪下去尽可能大的部分,所以我们能想到每一次将区间等大的分割,既然要的等大的分割,又要是二叉搜索树,我们就要让中间值作为当前节点,所有比它小的都放在它的左面,比它大的都放在它的右面。
知道大致思路了,就要来定义什么是大小了,因为一个点是在多维里,所以和它有关的值有多个。最好想的就是按读入的顺序,进行排序,第一维作为第一关键字,第二维作为第二关键字,以此类推。我们根据这些点的维度将它们从小到大排序(下面已二维上的点为例),每一次取当前区间的中间值来建树。这样我们就能将整个图分成下面的形式:
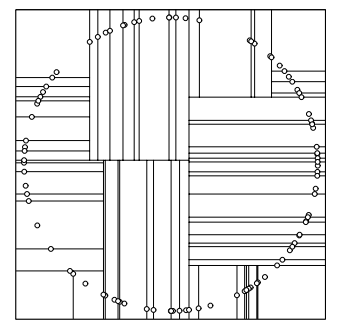
显然这种分法分出的图并不是最有利,因为每一点的管辖范围都太小了。我们考虑另一种分割方式,我们将这些点的排序方式进行改变,我们将排序的关键字每一次向顺时针进行转动,即我们第一次排序的第一关键字是第一维,第二次是第二维……第$n$次是第$n\%维数+1$维。这样上面的图形就可以改变成为:
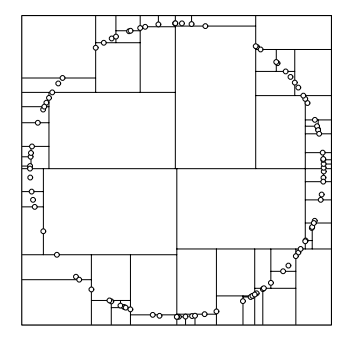
这样我们在剪枝的时候就能剪去更多的节点。
知道了如何去排序,我们现在就要知道怎么来找中间值。在函数库里面有一个函数$nth\_element$,这个就能实现我们要的功能。这个函数不知道实现的话,可以上网上找一下学习一下。我们在建树的时候要维护出来几个值,这几个值的运用在下面会进行讲解。这几个值是$mn[0],mx[0],mn[1],mx[1]$,分别表示以当前节点为根的子树第一维的最小值和最大值,第二维的最小值和最大值,这样我们在建树的时候应该更新。
struct Node {long long pla[2],mn[2],mx[2];int id,lson,rson;}node[N];
bool cmp(const Node &a,const Node &b) {return a.pla[sta]<b.pla[sta];}
void up(int p,int k)
{
node[p].mn[0]=min(node[p].mn[0],node[k].mn[0]);
node[p].mx[0]=max(node[p].mx[0],node[k].mx[0]);
node[p].mn[1]=min(node[p].mn[1],node[k].mn[1]);
node[p].mx[1]=max(node[p].mx[1],node[k].mx[1]);
}
int build(int l,int r,int now)
{
sta=now;int mid=(l+r)>>1;
nth_element(node+l,node+mid,node+r+1,cmp);
node[mid].mn[0]=node[mid].mx[0]=node[mid].pla[0];
node[mid].mn[1]=node[mid].mx[1]=node[mid].pla[1];
if(l!=mid) node[mid].lson=build(l,mid-1,(now+1)%2);
if(r!=mid) node[mid].rson=build(mid+1,r,(now+1)%2);
if(node[mid].lson) up(mid,node[mid].lson);
if(node[mid].rson) up(mid,node[mid].rson);
return mid;
}
建树之后,我们就可以在里面进行一些操作,比如找离定点的最远点,最近点,维护矩形内信息等等,下面就是一些估价函数的代码,以及矩形内区间赋值。
找离当前点的最近点的估价函数及查询(欧几里得距离):
long long dis(int p) {return squ(node[p].pla[0]-x)+squ(node[p].pla[1]-y);}
long long getdis(int p)
{
long long tmp=0;
tmp+=squ(max(abs(node[p].mx[0]-x),abs(node[p].mn[0]-x)));
tmp+=squ(max(abs(node[p].mx[1]-y),abs(node[p].mn[1]-y)));
return tmp;
}
void ask(int p)
{
long long tmp=dis(p);tmpx.dis=tmp,tmpx.id=node[p].id;
if(q.top().dis<=tmpx.dis) q.push(tmpx),q.pop();
long long tmpl=(node[p].lson)?getdis(node[p].lson):-inf;
long long tmpr=(node[p].rson)?getdis(node[p].rson):-inf;
if(tmpl>tmpr)
{
if(tmpl>=q.top().dis&&node[p].lson) ask(node[p].lson);
if(tmpr>=q.top().dis&&node[p].rson) ask(node[p].rson);
}
else
{
if(tmpr>=q.top().dis&&node[p].rson) ask(node[p].rson);
if(tmpl>=q.top().dis&&node[p].lson) ask(node[p].lson);
}
}
找离当前点的最远点的估价函数及查询(曼哈顿距离):
int getdis_mx(int p)
{
int tmp=0;
tmp+=max(abs(node[p].mx[0]-x),abs(node[p].mn[0]-x));
tmp+=max(abs(node[p].mx[1]-y),abs(node[p].mn[1]-y));
return tmp;
}
void ask_mx(int p)
{
int tmp=abs(node[p].pla[0]-x)+abs(node[p].pla[1]-y);
if(tmp>lenth_mx) lenth_mx=tmp;
int tmpl=(node[p].lson)?(getdis_mx(node[p].lson)):-inf;
int tmpr=(node[p].rson)?(getdis_mx(node[p].rson)):-inf;
if(tmpl>tmpr)
{
if(tmpl>lenth_mx) ask_mx(node[p].lson);
if(tmpr>lenth_mx) ask_mx(node[p].rson);
}
else
{
if(tmpr>lenth_mx) ask_mx(node[p].rson);
if(tmpl>lenth_mx) ask_mx(node[p].lson);
}
}
找离当前点的最远点的估价函数及查询(曼哈顿距离):
int getdis_mn(int p)
{
int tmp=0;
if(x<node[p].mn[0]) tmp+=node[p].mn[0]-x;
if(x>node[p].mx[0]) tmp+=x-node[p].mx[0];
if(y<node[p].mn[1]) tmp+=node[p].mn[1]-y;
if(y>node[p].mx[1]) tmp+=y-node[p].mx[1];
return tmp;
}
void ask_mn(int p)
{
int tmp=abs(node[p].pla[0]-x)+abs(node[p].pla[1]-y);
if(tmp&&tmp<lenth_mn) lenth_mn=tmp;
int tmpl=(node[p].lson)?(getdis_mn(node[p].lson)):inf;
int tmpr=(node[p].rson)?(getdis_mn(node[p].rson)):inf;
if(tmpl<tmpr)
{
if(tmpl<lenth_mn) ask_mn(node[p].lson);
if(tmpr<lenth_mn) ask_mn(node[p].rson);
}
else
{
if(tmpr<lenth_mn) ask_mn(node[p].rson);
if(tmpl<lenth_mn) ask_mn(node[p].lson);
}
}
矩阵赋值,矩阵查找:
void pushdown(int p)
{
if(!node[p].tag) return;
if(node[p].lson) node[node[p].lson].tag=node[node[p].lson].col=node[p].tag;
if(node[p].rson) node[node[p].rson].tag=node[node[p].rson].col=node[p].tag;
node[p].tag=0;
}
void change(int p,int w,int x,int y,int z,int col)
{
if(!p) return;
if(node[p].mx[0]<w||node[p].mn[0]>x) return;
if(node[p].mx[1]<y||node[p].mn[1]>z) return;
pushdown(p);
if(node[p].pla[0]>=w&&node[p].pla[0]<=x&&
node[p].pla[1]>=y&&node[p].pla[1]<=z) node[p].col=col;
if(node[p].mn[0]>=w&&node[p].mx[0]<=x&&
node[p].mn[1]>=y&&node[p].mx[1]<=z) {node[p].tag=node[p].col=col;return;}
change(node[p].lson,w,x,y,z,col),change(node[p].rson,w,x,y,z,col);
}
int find(int p,int w,int x,int y,int z)
{
if(!p) return 0;
if(node[p].mx[0]<w||node[p].mn[0]>x) return 0;
if(node[p].mx[1]<y||node[p].mn[1]>z) return 0;
pushdown(p);
if(node[p].pla[0]==w&&node[p].pla[1]==y) return node[p].col;
return max(find(node[p].lson,w,x,y,z),find(node[p].rson,w,x,y,z));
}
KDtree浅谈的更多相关文章
- cdq分治浅谈
$cdq$分治浅谈 1.分治思想 分治实际上是一种思想,这种思想就是将一个大问题划分成为一些小问题,并且这些小问题与这个大问题在某中意义上是等价的. 2.普通分治与$cdq$分治的区别 普通分治与$c ...
- 浅谈 Fragment 生命周期
版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Fragment 文中如有纰漏,欢迎大家留言指出. Fragment 是在 Android 3.0 中 ...
- 浅谈 LayoutInflater
浅谈 LayoutInflater 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/View 文中如有纰漏,欢迎大家留言指出. 在 Android 的 ...
- 浅谈Java的throw与throws
转载:http://blog.csdn.net/luoweifu/article/details/10721543 我进行了一些加工,不是本人原创但比原博主要更完善~ 浅谈Java异常 以前虽然知道一 ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
- 浅谈WebService的版本兼容性设计
在现在大型的项目或者软件开发中,一般都会有很多种终端, PC端比如Winform.WebForm,移动端,比如各种Native客户端(iOS, Android, WP),Html5等,我们要满足以上所 ...
- 浅谈angular2+ionic2
浅谈angular2+ionic2 前言: 不要用angular的语法去写angular2,有人说二者就像Java和JavaScript的区别. 1. 项目所用:angular2+ionic2 ...
- iOS开发之浅谈MVVM的架构设计与团队协作
今天写这篇博客是想达到抛砖引玉的作用,想与大家交流一下思想,相互学习,博文中有不足之处还望大家批评指正.本篇博客的内容沿袭以往博客的风格,也是以干货为主,偶尔扯扯咸蛋(哈哈~不好好工作又开始发表博客啦 ...
- Linux特殊符号浅谈
Linux特殊字符浅谈 我们经常跟键盘上面那些特殊符号比如(?.!.~...)打交道,其实在Linux有其独特的含义,大致可以分为三类:Linux特殊符号.通配符.正则表达式. Linux特殊符号又可 ...
随机推荐
- 《Cracking the Coding Interview》——第13章:C和C++——题目6
2014-04-25 20:07 题目:为什么基类的析构函数必须声明为虚函数? 解法:不是必须,而是应该,这是种规范.对于基类中执行的一些动态资源分配,如果基类的析构函数不是虚函数,那么 派生类的析构 ...
- Python第三方模块tesserocr安装
介绍 在爬虫过程中,难免会遇到各种各样的验证码,而大多数验证码还是图形验证码,这时候我们可以直接用 OCR 来识别. tesserocr 是 Python 的一个 OCR 识别库 ,但其实是对 tes ...
- Python 3基础教程1-环境安装和运行环境
本系列开始介绍Python3的基础教程,为什么要选中Python 3呢?之前呢,学Python 2,看过笨方法学Python,学了不到一个礼拜,就开始用Python写Selenium脚本.最近看到一些 ...
- centos7系列问题
一.CentOS7.1查看ip route有两条路由规则 1.metric值是指到达目的地需要的跳数,是表达该条路由连接质量的指标.当有多条到达相同目的地的路由记录时,路由器会采用metric值小的那 ...
- heat应用
作为OpenStack中的编排引擎,Heat能够出色的完成编排任务,井井有条地管理编排出来的资源.但同时,Heat也是一个出色的应用部署引擎,它提供了一套内置的框架去完成一系列复杂的应用部署任务. 使 ...
- ImportError: dynamic module does not define module export function (PyInit__caffe)
使用python3运行caffe,报了该错误. 参考网址:https://stackoverflow.com/questions/34295136/importerror-dynamic-module ...
- 系统编程--标准IO
1.流和FILE对象 对于国际字符集,一个字符可以由一个以上的字节来表示.标准I/O文件流可以用来操作单字节和多字节(宽,wide)字符集.一个流的方向(orientation)决定了字符是以单字节还 ...
- 第六章 系统配置:DHCP和自动配置
系统配置:DHCP和自动配置 写在开头:今天和导师见了个面,抛给我一堆材料以及论文,感觉自己学业更加繁重.有些知识现阶段我可能没办法掌握,但是至少在我需要进一步理解它的时候,要知道在哪个地方能够找到. ...
- thinkphp中dump()方法
dump ThinkPHP 框架 自定义的 用作框架变量 调试用的输出 功能可以说和 var_dump一样的
- input file request.files[] 为空
需要在 form 里设置 一句话 : $('form').attr("enctype", "multipart/form-data"); <form e ...