Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造
FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对。为了达到这样的效果,它采用了一种简洁的数据结构,叫做frequent-pattern tree(频繁模式树)。下面就详细谈谈如何构造这个树,举例是最好的方法。请看下面这个例子:
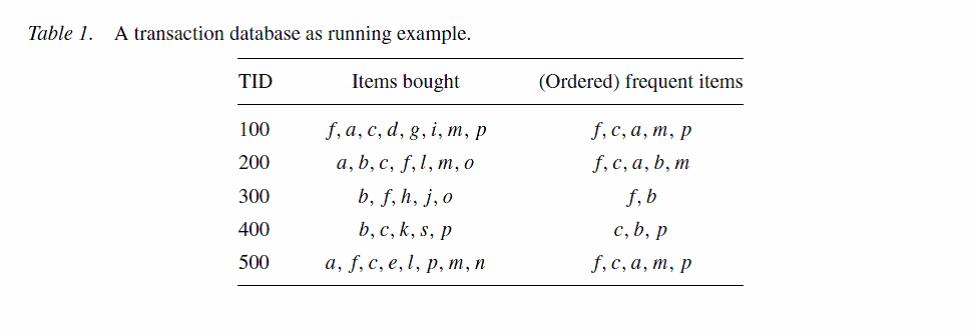
这张表描述了一张商品交易清单,abcdefg代表商品,(ordered)frequent items这一列是把商品按照降序重新进行了排列,这个排序很重要,我们操作的所有项目必须按照这个顺序来,这个顺序的确定非常简单,只要对数据库进行一次扫描就可以得到这个顺序。由于那些非频繁的项目在整个挖掘中不起任何作用,因此在这一列中排除了这些非频繁项目。我们在这个例子中设置最小支持阈值(minimum support threshold)为3。
我们的目标是为整个商品交易清单构造一颗树。我们首先定义这颗树的根节点为null,然后我们开始扫描整个数据库的每一条记录开始构造FP树。
第一步:扫描数据库的第一个交易,也就是TID为100的交易。那么就会得到这颗树的第一个分支<(f:1),(c:1),(a:1),(m:1),(p:1)>。注意这个分支一定是要按照降频排列的。

第二步:扫描第二条交易记录(TID=200),我们会有这么一个频繁项目集合<f,c,a,b,m>。仔细观察这个队列,你会发现这个集合的前3项<f,c,a>与第一步产生的路径<f,c,a,m,p>的前三项是相同的,也就是说他们可以共享一个前缀。于是我们在第一步产生的路径的基础上,把<f,c,a>三个节点的数目加1,然后将<(b:1),(m:1)>作为一个分支加在(a:2)节点的后面,成为它的子节点。看下图:
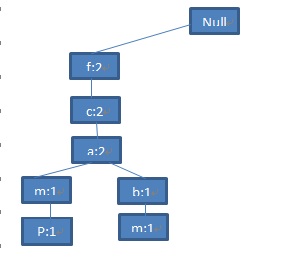
第三步:接着扫描第三条交易记录(TID=300),你会看到这条记录的集合是<f, b>,与已存在的路径相比,只有f是共有的前缀,那么f节点加1,同时再为f节点生成一个新的字节点(b:1).就会有下图:
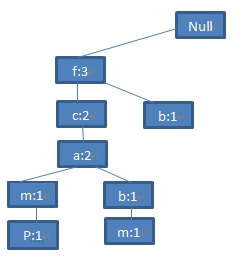
第四步:继续看第四条交易记录,它的集合是<c,b,p>,哦,这回不一样了。你会发现这个集合的第一个元素是c,与现存的已知路径的第一个节点f不一样,那就不用往下比了,没有任何公共前缀。直接将该集合作为根节点的子路径附加上去。就得到了下图(图1):
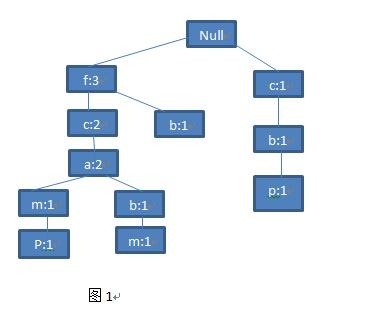
第五步:最后一条交易记录来了,你看到了一条集合<f,c,a,m,p>。你惊喜得发现这条路径和树现有最左边的路径竟然完全一样。那么,这整条路径都是公共前缀,那么这条路径上的所有点都加1好了。就得到了最终的图(图2)。
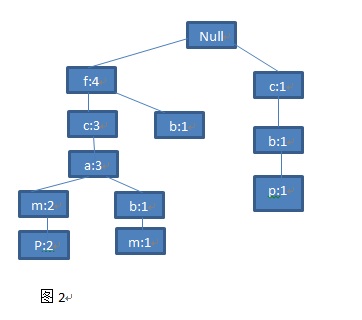
好了,一颗FP树就已经基本构建完成了。等等,还差一点。上述的树还差一点点就可以称之为一个完整的FP树啦。为了便于后边的树的遍历,我们为这棵树又增加了一个结构-头表,头表保存了所有的频繁项目,并且按照频率的降序排列,表中的每个项目包含一个节点链表,指向树中和它同名的节点。罗嗦了半天,可能还是不清楚,好吧直接上图,一看你就明白:
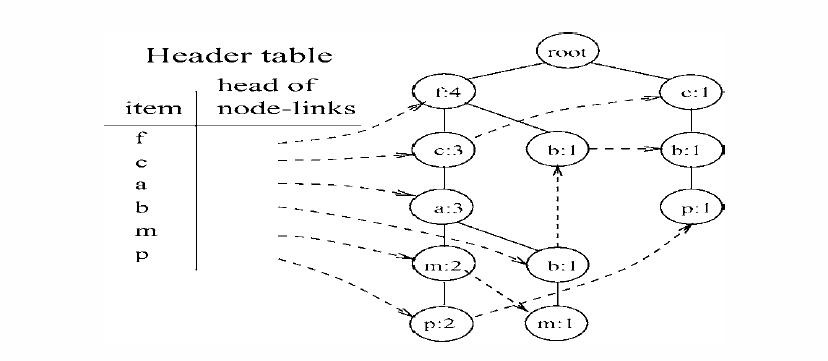
以上就是整个FP树构造的完整过程。聪明的读者一定不难根据上述例子归纳总结出FP树的构造算法。这里就不再赘述。
FP树的挖掘
下面就是最关键的了。我们已经有了一个非常简洁的数据结构,下一步的任务就是从这棵树里挖掘出我们所需要的频繁项目集合而不需要再访问数据库了。还是看上面的例子。
第一步:我们的挖掘从头表的最后一项p开始,那么一个明显的直接频繁集是(p:3)了。根据p的节点链表,它的2个节点存在于2条路径当中:路径<f:4,c:3,a:3,m:2,p:2>和路径<c:1,b:1,p:1>.从路径<f:4,c:3,a:3,m:2,p:2>我们可以看出包含p的路径<f,c,a,m,p>出现了2次,同时也会有<f,c,a>出现了3次,<f>出现了4次。但是我们只关注<f,c,a,m,p>,因为我们的目的是找出包含p的所有频繁集合。同样的道理我们可以得出<c,b,p>在数据库中出现了1次。于是,p就有2个前缀路径{(fcam:2),(cb:1)}。这两条前缀路径称之为p的子模式基(subpattern-base),也叫做p的条件模式基(之所以称之为条件模式基是因为这个子模式基是在p存在的前提条件下)。接下来我们再为这个条件子模式基构造一个p的条件FP树。再回忆一下上面FP树的构造算法,很容易得到下面这棵树:
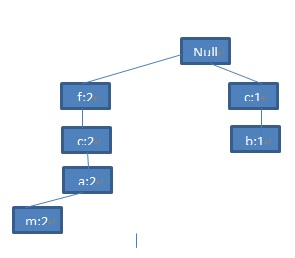
但是由于频繁集的阈值是3。那么实际上这棵树经过剪枝之后只剩下一个分支(c:3),所以从这棵条件FP树上只能派生出一个频繁项目集{cp:3}.加上直接频繁集(p:3)就是最后的结果.
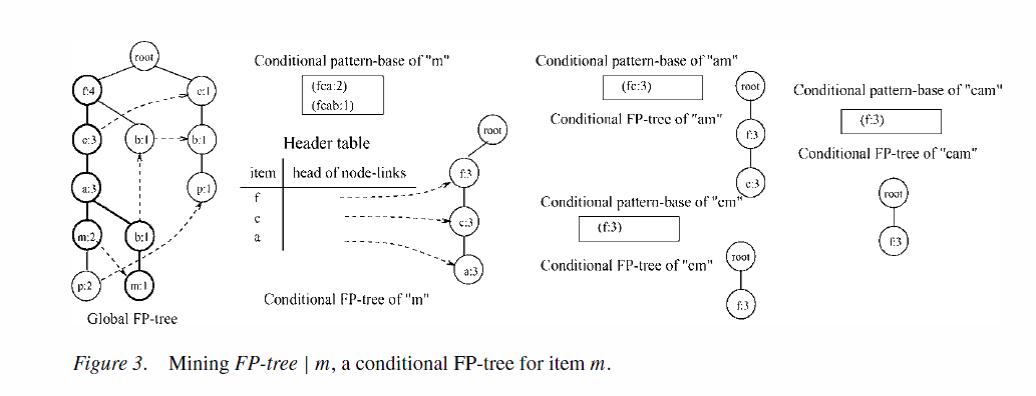
第二步:我们接下来开始挖掘头表中的倒数第二项m,同第一步一样,显然有一个直接的频繁集(m:3).再查看它在FP树中存在的两条路径<f:4,c:3,a:3,m:2>和<f:4,c:3,a:3,b1,m:1>.那么它的频繁条件子模式基就是{ (fca:2),(fcab:1)}.为这个子模式基构造FP树,同时舍弃不满足最小频繁阈值的分支b,那么其实在这棵FP树中只存在唯一的一个频繁路径<f:3,c:3,a:3>.既然这颗子FP树是存在的,并且不是一颗只有一个节点的特殊的树,我们就继续递归得挖掘这棵树.这棵子树是单路径的子树,我们可以简化写成mine(FP tree|m)=mine(<f:3,c:3,a:3>|m:3).
下面来阐述如何挖掘这颗FP子树,我们需要递归.递归子树也需要这么几个步骤:
1这颗FP子树的头表最后一个节点是a,结合递归前的节点m,那么我们就得到am的条件子模式基{(fc:3)},那么此子模式基构造的FP树(我们称之为m的子子树)实际上也是一颗单路径的树<f:3,c:3>,接下也继续继续递归挖掘子子树mine(<f:3,c:3>|am:3). (子子树的递归分析暂时打住.因为再分析子子树的递归的话文字就会显得太混乱)
2同样,FP子树头表的倒数第二个节点是c,结合递归前节点m,就有我们需要递归挖掘mine(<f:3>|cm:3).
3 FP子树的倒数第三个节点也是最后一个节点是f,结合递归前的m节点,实际上需要递归挖掘mine(null|fm:3),实际上呢这种情况下的递归就可以终止了,因为子树已经为空了.因此此情况下就可以返回频繁集合<fm:3>
注意:这三步其实还包含了它们直接的频繁子模式<am:3>,<cm:3>,<fm:3>,这在每一步递归调用mine<FPtree>都是一样的,就不再罗嗦得一一重新指明了.
实际上这就是一个很简单的递归过程,就不继续往下分析了,聪明的读者一定会根据上面的分析继续往下推导递归,就会得到下面的结果.
mine(<f:3,c:3>|am:3)=><cam:3>,<fam:3>,<fcam:3>
mine(<f:3>|cm:3)=><fcm:3>
mine(null|fm:3)=><fm:3>
这三步还都包含了各自直接的频繁子模式<am:3>,<cm:3>,<fm:3>.
最后再加上m的直接频繁子模式<m:3>,就是整个第二步挖掘m的最后的结果。请看下图:
第三步:来看看头表倒数第三位<b:3>的挖掘,它有三条路径<f:4,c:3,a:3,b:1>,<f:4,b:1>,<c:1,b:1>,形成的频繁条件子模式基为{(fca:1),(f:1),(c:1)},构建成的FP树中的所有节点的频率均小于3,那么FP树为空,结束递归.这一步得到的频繁集就只有直接频繁集合<b:3>
第四步:头表倒数第四位<a:3>,它有一条路径<f:4,c:3>,频繁条件子模式基为{(fc:3)},构成一个单路径的FP树.实际上可能有人早已经发现了,这种单路径的FP树挖掘其实根本不用递归这么麻烦,只要进行排列组合就可以直接组成最后的结果.实际上也确实如此.那么这一步最后的结果根据排列组合就有:{(fa:3),(ca:3),(fca:3),(a:3)}
第五步:头表的倒数第五位<c:4>,它只有一条路径<f:4>,频繁条件子模式基为{(f:3)},那么这一步的频繁集也就很明显了:{(fc:3),(c:4)}
第六步:头表的最后一位<f:4>,没有条件子模式基,那么只有一个直接频繁集{(f:4)}
这6步的结果加在一起,就得到我们所需要的所有频繁集.下图给出了每一步频繁条件模式基.

其实,通过上面的例子,估计早有人看出来了,这种单路径的FP树挖掘其实是有规律的,根本不用递归这么复杂的方法,通过排列组合可以直接生成.的确如此,Han Jiawei针对这种单路径的情况作了优化.如果一颗FP树有一个很长的单路径,我们将这棵FP树分成两个子树:一个子树是由原FP树的单路径部分组成,另外一颗子树由原FP树的除单路径之外的其余部分组成.对这两个子树分别进行FP Growth算法,然后对最后的结果进行组合就可可以了.
通过上面博主不厌其烦,孜孜不倦,略显罗嗦的分析,相信大家已经知道FP Growth算法的最终奥义.实际上该算法的背后的思想很简单,用一个简洁的数据结构把整个数据库进行FP挖掘所需要的信息都包含了进去,通过对数据结构的递归就可以完成整个频繁模式的挖掘.由于这个数据结构的size远远小于数据库,因此可以保存在内存中,那么挖掘速度就可以大大提高.
也许有人会问?如果这个数据库足够大,以至于构造的FP树大到无法完全保存在内存中,这该如何是好.这的确是个问题. Han Jiawei在论文中也给出了一种思路,就是通过将原来的大的数据库分区成几个小的数据库(这种小的数据库称之为投射数据库),对这几个小的数据库分别进行FP Growth算法.
还是拿上面的例子来说事,我们把包含p的所有数据库记录都单独存成一个数据库,我们称之为p-投射数据库,类似的m,b,a,c,f我们都可以生成相应的投射数据库,这些投射数据库构成的FP树相对而言大小就小得多,完全可以放在内存里.
Frequent Pattern 挖掘之二(FP Growth算法)(转)的更多相关文章
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Frequent Pattern 挖掘之一(Aprior算法)(转)
数据挖掘中有一个很重要的应用,就是Frequent Pattern挖掘,翻译成中文就是频繁模式挖掘.这篇博客就想谈谈频繁模式挖掘相关的一些算法. 定义 何谓频繁模式挖掘呢?所谓频繁模式指的是在样本数据 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- 数据挖掘算法之关联规则挖掘(二)FPGrowth算法
之前介绍的apriori算法中因为存在许多的缺陷,例如进行大量的全表扫描和计算量巨大的自然连接,所以现在几乎已经不再使用 在mahout的算法库中使用的是PFP算法,该算法是FPGrowth算法的分布 ...
- 【机器学习】关联规则挖掘(二):频繁模式树FP-growth
Apriori算法的一个主要瓶颈在于,为了获得较长的频繁模式,需要生成大量的候选短频繁模式.FP-Growth算法是针对这个瓶颈提出来的全新的一种算法模式.目前,在数据挖掘领域,Apriori和FP- ...
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
随机推荐
- USB数据线上的“疙瘩”:原来有这么大用处!
在不少键盘.鼠标或是游戏外设的数据线末端我们都能见到一小段金属圆环.虽然这算得上是习以为常的一个设计,但如果说到其具体作用的话很多人一下子还真回答不上来.反正笔者在这里先可以告诉大家,这货肯定不是简简 ...
- POJ -- 2436
Disease Management Description Alas! A set of D (1 <= D <= 15) diseases (numbered 1..D) is run ...
- AutoItLibrary
问题: [ ERROR ] Error in file 'E:\test\test_AutoItLibrary.txt': Initializing test library 'AutoItLibra ...
- Unity3d 模拟视锥的实现
一个独立游戏 Teleglitch 使用了一种欺骗手法来模拟视锥,效果如下: 博主看了看了看提示 Actually, the line of sight shadows aren’t done wit ...
- 《C语言程序设计现代方法》第1章 C语言概述
C语言的特点:C语言是一种底层语言.C语言是一种小型语言.C语言是一种包容性语言. C语言的优点:高效.可移植.功能强大.灵活.标准库.与UNIX系统集成. C语言的缺点:C程序更容易隐藏错误.C程序 ...
- Genotype&&陨石的秘密
Genotype: Genotype 是一个有限的基因序列.它是由大写的英文字母A-Z组成,不同的字母表示不同种类的基因.一个基因可以分化成为一对新的基因.这种分化被一个定义的规则集合所控制.每个分化 ...
- Django自定义用户认证
自定义一个用户认证 详细参考官方文档: https://docs.djangoproject.com/en/1.9/topics/auth/customizing/#django.contrib.au ...
- 初级程序员应该了解的Linux命令
基于Linux的系统最美妙的一点,就是你可以在终端中使用命令行来管理整个系统.使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版. 对于各个发行版以及桌面环境(DE)而言, ...
- 2 weekend110的hadoop的自定义排序实现 + mr程序中自定义分组的实现
我想得到按流量来排序,而且还是倒序,怎么达到实现呢? 达到下面这种效果, 默认是根据key来排, 我想根据value里的某个排, 解决思路:将value里的某个,放到key里去,然后来排 下面,开始w ...
- java集合类之TreeMap
转自:http://blog.csdn.net/chenssy/article/details/26668941 TreeMap的实现是红黑树算法的实现,所以要了解TreeMap就必须对红黑树有一定的 ...