深入浅出之mysql索引--上
当着小萌新之际,最近工作中遇到了mysql优化的相关问题,然后既然提到了优化,很多像我这样的小萌新不容置喙,肯定张口就是 建立索引 之类的。
那么说到底,索引到底是什么,它是怎么工作的?接下来就让我和大家一起学习学习吧
1.索引是什么?
不难理解,索引的出现其实就是为了提高数据查询的效率,简单点来说索引就好比一本书的目录,是为了准确定位具体数据而用的。
2.索引的常见模型
索引模型中,一般比较常见的包括 哈希表、有序数组、搜索树
哈希表是一种以key-value存储数据的结构,我们只要输入待查找的值即 key, 就可以找到其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。
但是当多个 key 值经过哈希函数的换算,会出现同一个值的情况,为了处理这种情况,引出了 链表
如果你要维护一个身份证信息和姓名的表,需要根据身份证号查找对应的名字,这时 对应的哈希索引的示意图如下所示
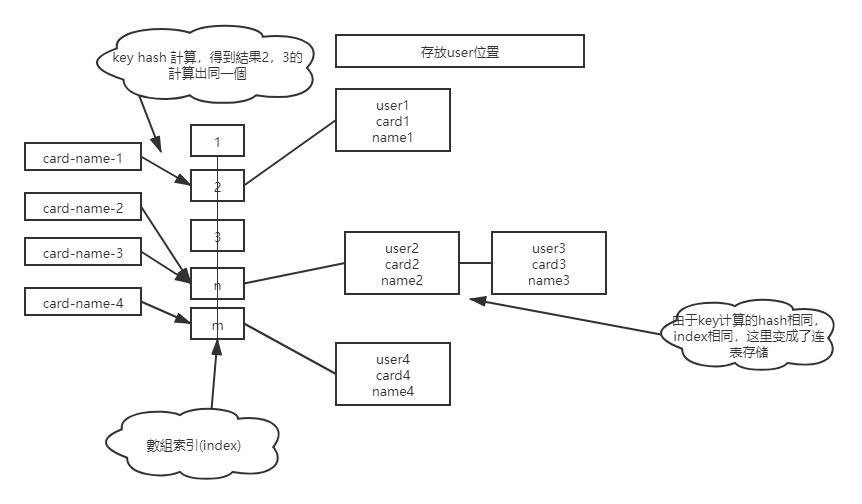
图中,User2 和 User3 根据身份证号算出来的值都是 n,后面还跟了一个链表。
如果这时候你要查 card-2 对应的名字是什么,处理步骤就是:首先,将 card-2 通过哈希函数算出n,然后,按顺序遍历,找到 User2。
需要注意的是,图中四个 card-n 的值并不是递增的,这样做的好处是增加新的 User 时 速度会很快,只需要往后追加。
但缺点是,因为不是有序的,所以哈希索引做 区间查询 的速度是很慢的。
如果你现在要找身份证号在 [card_X, card_Y] 这个区间的所有用户,就必须全部扫描一遍了。
所以,哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎
有序数组在等值查询和范围查询场景中的性能就都非常优秀,以下是其索示意图
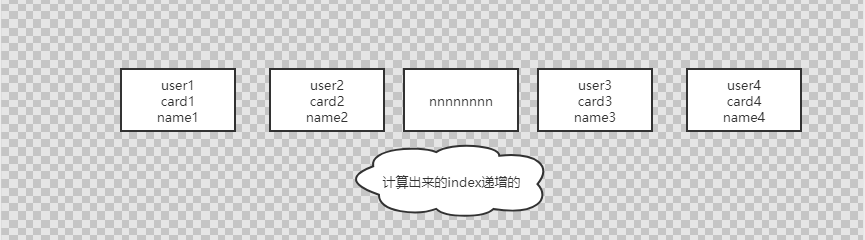
假设身份证号没有重复,这个数组就是按照身份证号递增的顺序保存的。
这时候如 果你要查 card_n2 对应的名字,用二分法就可以快速得到,这个时间复杂度是 O(log(N))。
同时很显然,这个索引结构支持范围查询。你要查身份证号在 [card_X, card_Y] 区间的user,可以先用二分法找到 card_X(如果不存在card_X,就找到大于card_X 的第一个user),然后向右遍历,直到查到第一个大于card_Y 的身份证 号,退出循环。
如果仅仅看查询效率,有序数组就是最好的数据结构了。
但是,在需要更新数据的时候却不好,你往中间插入一个记录就必须得挪动后面所有的记录,成本太高。
所以,有序数组索引只适用于静态存储引擎,比如你要保存的是2020年某个城市的所有人口信息,这类不会再修改的数据
二叉搜索树示意图
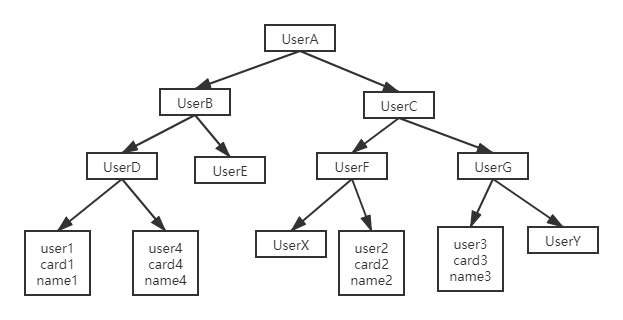
二叉搜索树的特点是:
每个节点的左儿子小于父节点,父节点又小于右儿子。这样如果你要查card_n2 的话,按照图中的搜索顺序就是按照 UserA -> UserC -> UserF -> User2 这个路径得到。这个时间复杂度是 O(log(N))。
当然为了维持 O(log(N)) 的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个 保证,更新的时间复杂度也是 O(log(N))。
树可以有二叉,也可以有多叉。多叉树就是每个节点有多个儿子,儿子之间的大小保证从左 到右递增。
二叉树是搜索效率最高的,但是实际上大多数的数据库存储却并不使用二叉树。 其原因是,索引不止存在内存中,还要写到磁盘上。
你可以想象一下一棵 100 万节点的平衡二叉树,树高20。一次查询可能需要访问 20 个数据块。
在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是说,对于一个100万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个10 ms 的时间
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么,我们就不应该使用二叉树,而是要使用“N 叉”树。这里,“N 叉”树中的“N”取决于数据块的大小。
以 InnoDB 的一个整数字段索引为例,这个N差不多是 1200。这棵树高是 4 的时候,就可以存 1200 的 3 次方个值,这已经 17 亿了。
考虑到树根的数据块总是在内存中的,一个 10 亿行的表上一个整数字段的索引,查找一个值最多只需要访问3次磁盘。
其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。N叉树由于在读写上的性能优点,以及适配磁盘的访问模式,已经被广泛应用在数据库引 擎中了。
在 MySQL 中,索引是在存储引擎层实现的,所以并没有统一的索引标准,即不同存储引 擎的索引的工作方式并不一样。而即使多个存储引擎支持同一种类型的索引,其底层的实现 也可能不同。由于 InnoDB 存储引擎在 MySQL 数据库中使用最为广泛,下面以 InnoDB为例子
InnoDB 的索引模型
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的,每一个索引在 InnoDB 里面对应一棵 B+ 树。
假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引
CREATE TABLE T ( id INT PRIMARY KEY, k INT NOT NULL, NAME VARCHAR ( 16 ), INDEX ( k ) ) ENGINE = INNODB;
表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树 的示例示意图如下
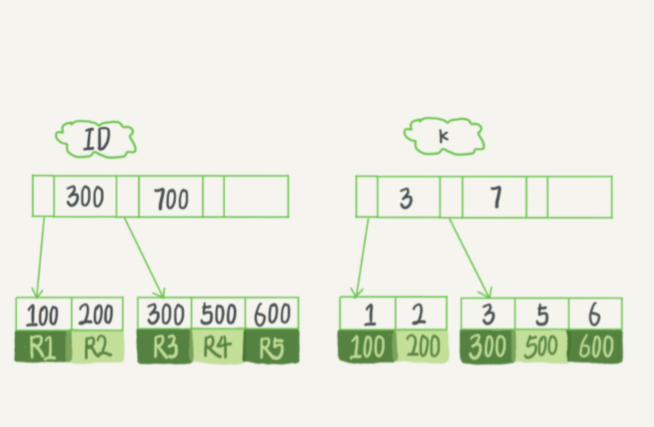
从图中不难看出,根据叶子节点的内容,索引类型分为 主键索引 和 非主键索引 。
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引 (clustered index)。
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引 (secondary index)。
根据上面的索引结构说明,来讨论一个问题:基于主键索引和普通索引的查询有什么区别?
如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引 树,得到 ID 的值为 500,再到 ID 索引树搜索一次。
这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。.
索引维护
B+树为了维护索引有序性,在插入新值的时候需要做必要的维护。
以上面这个图为例,
如果插入新的行ID值为 700,则只需要在 R5 的记录后面插入一个新记录。
如果新插入的ID值为400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。
这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约50%。
基于上面的索引维护过程说明,讨论一个案例:
在一些建表规范里面见到过类似的描述,要求建表语句里一定要有自 增主键。
分析一下哪些场景下应该使用自增主键,而 哪些场景下不应该。
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的: NOT NULL PRIMARY KEY AUTO_INCREMENT。
插入新记录的时候可以不指定 ID 的值,系统会获取当前 ID 最大值加 1 作为下一条记录的 ID 值。
也就是说,自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
而有业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
除了考虑性能外,还可以从存储空间的角度来看。
假设你的表中确实有一个唯一字段, 比如字符串类型的身份证号,那应该用身份证号做主键,还是用自增字段做主键呢?
由于每个非主键索引的叶子节点上都是主键的值(因为要根据非主键索引找到主键索引位置然后再找到数据,可看上图)。
如果用身份证号做主键,那么每个二级索引的叶子节点占用约 20 个字节,而如果用整型做主键,则只要 4 个字节,如果是长整型 (bigint)则是 8 个字节。
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
所以,从性能和存储空间方面考量,自增主键往往是更合理的选择。
什么场景适合用业务字段直接做主键的呢?有些业务的场景需求是如下:
- 只有一个索引;
- 该索引必须是唯一索引
这就是典型的 KV 场景。
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。
这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为 主键,可以避免每次查询需要搜索两棵树。
对于上面例子中的 InnoDB 表 T,如果要重建索引 k,可以写:
alter table T drop index k;
alter table T add index(k);
要重建主键索引,可以写
alter table T drop primary key;
alter table T add primary key(id);
这样写是否合理?
重建索引 k 的做法是合理的,可以达到省空间的目的。
但是,重建主键的过程不合理。
不论是删除主键还是创建主键,都会将整个表重建。
所以连着执行这两个语句的话,第一个语句就白做了。这两个语句,可以用这个语句代替 :alter table T engine=InnoDB
深入浅出之mysql索引--上的更多相关文章
- 深入浅出分析MySQL索引设计背后的数据结构
在我们公司的DB规范中,明确规定: 1.建表语句必须明确指定主键 2.无特殊情况,主键必须单调递增 对于这项规定,很多研发小伙伴不理解.本文就来深入简出地分析MySQL索引设计背后的数据结构和算法,从 ...
- 图解MySQL索引(上)—MySQL有中“8种”索引?
关于MySQL索引相关的内容,一直是一个让人头疼的问题,尤其是对于初学者来说.笔者曾在很长一段时间内深陷其中,无法分清"覆盖索引,辅助索引,唯一索引,Hash索引,B-Tree索引--&qu ...
- 深入理解MySQL索引(上)
简单来说,索引的出现就是为了提高数据查询的效率,就像字典的目录一样.如果你想快速找一个不认识的字,在不借助目录的情况下,那我估计你的找好长时间.索引其实就相当于目录. 几种常见的索引模型 索引的出现是 ...
- NULL在oracle和mysql索引上的区别
一.问题 oracle的btree索引不存储NULL值,所以用is null或is not null都不会用到索引范围扫描,但是在mysql中也是这样吗? 二.实验 先看看NULL在oracle(11 ...
- 图解MySQL索引(二)—为什么使用B+Tree
失踪人口回归,近期换工作一波三折,耽误了不少时间,从今开始每周更新~ 索引是一种支持快速查询的数据结构,同时索引优化也是后端工程师的必会知识点.各个公司都有所谓的MySQL"军规" ...
- 深入浅出Mysql索引优化专题分享|面试怪圈
文章纲要 该文章结合18张手绘图例,21个SQL经典案例.近10000字,将Mysql索引优化经验予以总结,你可以根据纲要来决定是否继续阅读,完成这篇文章大概需要25-30分钟,相信你的坚持是不负时光 ...
- mysql索引的使用[上]
数据库的explain关键字和联合索引优化: 本篇文章简单的说一下mysql查询的优化以及explain语句的使用.(新手向) 因为这篇文章是面向查询的,直观一点,首先我们创建一个表:student ...
- Mysql 索引的基础(上)
要理解Mysql 中索引是如何工作的,最简单的方法是去看一看书的"索引部分":如果想在一本书中找到某个特定的主题,一般先看书的"索引",找到对应的页码. 在My ...
- 深入浅出分析MySQL MyISAM与INNODB索引原理、优缺点、主程面试常问问题详解
本文浅显的分析了MySQL索引的原理及针对主程面试的一些问题,对各种资料进行了分析总结,分享给大家,希望祝大家早上走上属于自己的"成金之路". 学习知识最好的方式是带着问题去研究所 ...
随机推荐
- ArcGIS API for Javascript的Point clustering使用及默认符号无法显示问题
1.将包含ClusterFeatureLayer.js文件的extras文件夹放在部署的arcgis api目录下,如下图. extras路径 2.使用ClusterFeatureLayer关键代码如 ...
- django 框架模型之models常用的Field
1. django 模型models 常用字段 1.models.AutoField 自增列 = int(11) 如果没有的话,默认会生成一个名称为 id 的列 如果要显式的自定义一 ...
- PageHelper使用步骤
一.导入jar包(maven构建导入坐标) <dependency> <groupId>com.github.pagehelper</groupId> <ar ...
- 重磅解读:K8s Cluster Autoscaler模块及对应华为云插件Deep Dive
摘要:本文将解密K8s Cluster Autoscaler模块的架构和代码的Deep Dive,及K8s Cluster Autoscaler 华为云插件. 背景信息 基于业务团队(Cloud BU ...
- git引入_版本控制介绍
八个字形容git技术: 公司必备,一定要会 一.git概念: git是一个免费的,开源的分布式版本控制系统,可以快速高效的处理从小型到大型的项目 二.什么是版本控制: 版本控制是一种一个记录一个或若个 ...
- Electron入门指北
最近几年最火的桌面化技术,无疑是Qt+和Electron. 两者都有跨平台桌面化技术,并不局限于Windows系统.前者因嵌入式而诞生,在演变过程中,逐步完善了生态以及工具链.后者则是依托于Node. ...
- 3 jinja2模板
video17 jinja2过滤器 过滤器通过管道符号进行使用.如{{ name | length }}将返回name的长度,过滤器相当于是一个函数. 1 def hello_world(): 2 i ...
- http代理阅读2
向上游服务器发送请求处理 static void ngx_http_upstream_send_request(ngx_http_request_t *r, ngx_http_upstream_t * ...
- UNIX目录访问操作
1.目录访问相关函数: DIR* opendir (const char * path ); struct dirent* readdir(DIR *dirptr) ;参数是一个指向dirent 结构 ...
- mysql权限管理命令
#创建用户 create user 'songwp' IDENTIFIED BY '1234' #用户授权 GRANT ALL ON DB01.* TO 'songwp' #撤销权限 REVOKE A ...