spark 四种模式
二:Spark On Local Cluster(Spark Standalone)伪分布式
Standalone模式是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf.setManager(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的。
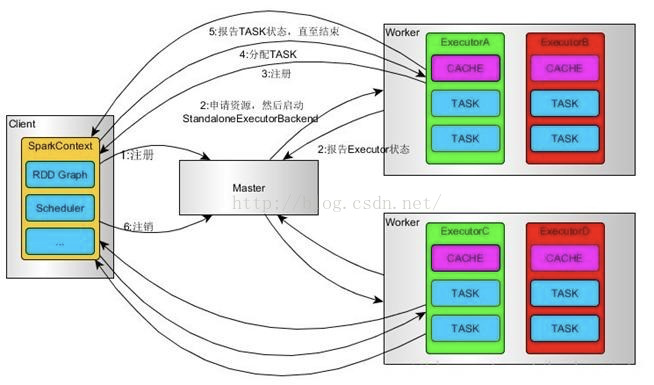
1、我们提交一个任务,任务就叫Application
2、初始化程序的入口SparkContext,
2.1 初始化DAG Scheduler
2.2 初始化Task Scheduler
3、Task Scheduler向master去进行注册并申请资源(CPU Core和Memory)
4、Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;顺便初
始化好了一个线程池
5、StandaloneExecutorBackend向Driver(SparkContext)注册,这样Driver就知道哪些Executor为他进行服务了。
6、SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生)。
7、将Stage(或者称为TaskSet)提交给Task Scheduler。Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
8、对task进行序列化,并根据task的分配算法,分配task
9、对接收过来的task进行反序列化,把task封装成一个线程
10、开始执行Task,并向SparkContext报告,直至Task完成。
11、资源注销
三:Spark On Yarn
Spark on YARN模式根据Driver在集群中的位置分为两种模式:一种是YARN-Client模式,另一种是YARN-Cluster(或称为YARN-Standalone模式)。
Yarn Client模式
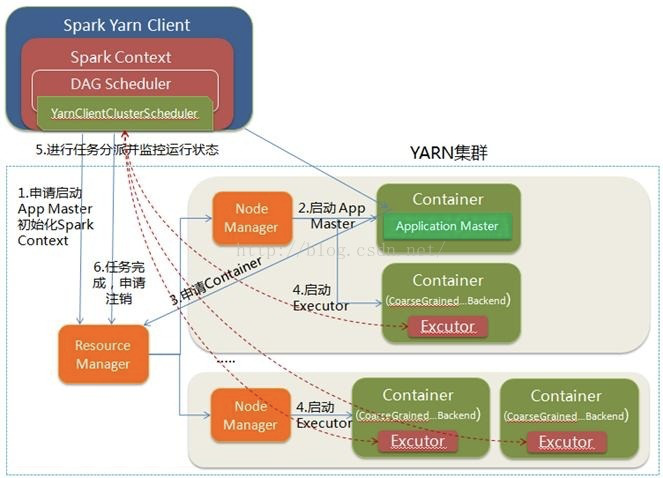
1.Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3.Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
Spark 在Yarn Cluster 模式
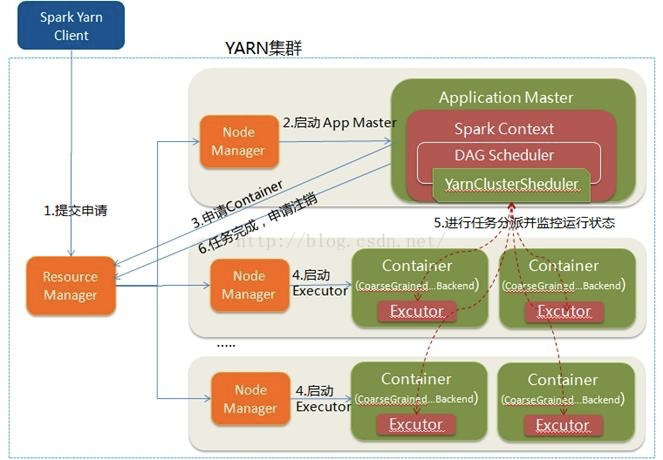
1. Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2. ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3. ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4. 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。
这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
5. ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6. 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
spark 四种模式的更多相关文章
- Hibernate 查询MatchMode的四种模式
Hibernate 查询MatchMode的四种模式 MatchMode.START:字符串在最前面的位置.相当于"like 'key%'" MatchMode.END:字符串在最 ...
- Android 文件访问权限的四种模式
Linux文件的访问权限* 在Android中,每一个应用是一个独立的用户* drwxrwxrwx* 第1位:d表示文件夹,-表示文件* 第2-4位:rwx,表示这个文件的拥有者(创建这个文件的应用) ...
- 对称加密和分组加密中的四种模式(ECB、CBC、CFB、OFB)
一. AES对称加密: AES加密 分组 二. 分组密码的填充 分组密码的填充 e.g.: PKCS#5填充方式 三. 流密码: 四. 分组密码加密中的四种模式: 3.1 ECB模式 优点: 1. ...
- Asp.net的sessionState四种模式配置方案
sessionState节点的配置 web.config关于sessionState节点的配置方案,sessionState有四种模式:off,inProc,StateServer,SqlServer ...
- OAuth2简易实战(一)-四种模式
1. OAuth2简易实战(一)-四种模式 1.1. 授权码授权模式(Authorization code Grant) 1.1.1. 流程图 1.1.2. 授权服务器配置 配置授权服务器中 clie ...
- LVS 原理(调度算法、四种模式、四层负载均衡和七层 的区别)
参考文档:http://blog.csdn.net/ioy84737634/article/details/44916241 目录 lvs的调度算法 lvs的四种模式 四层均衡负载和七层的区别 1.l ...
- AES加密的四种模式详解
对称加密和分组加密中的四种模式(ECB.CBC.CFB.OFB) 一. AES对称加密: A ...
- 第164天:js方法调用的四种模式
js方法调用的四种模式 1.方法调用模式 function Persion() { var name1 = "itcast", age1 = 19, show1 = functio ...
- 小知识:SPI四种模式区别【转】
转自:http://home.eeworld.com.cn/my/space-uid-80086-blogid-119198.html spi四种模式SPI的相位(CPHA)和极性(CPOL)分别可以 ...
随机推荐
- VMDNAMD命令规则(转载)
输出体系的整个带电量:measure sumweights $all weight charge 给PDB文件设置周期边界条件:pbc set {54 54 24 } -all 将此晶胞内原子脱除周期 ...
- 尝试写一写4gl与4fd
4gl DATABASE ds GLOBALS "../../config/top.global" DEFINE g_curs_index LIKE t ...
- [CSP-S2019]括号树 题解
CSP-S2 2019 D1T2 刚开考的时候先大概浏览了一遍题目,闻到一股浓浓的stack气息 调了差不多1h才调完,加上T1用了1.5h+ 然而T3还是没写出来,滚粗 思路分析 很容易想到的常规操 ...
- 网站seo整站优化有什么优势
http://www.wocaoseo.com/thread-314-1-1.html 现在很多企业找网络公司做网站优化,已经不再像以前那样做目标关键词,而是通过整站优化来达到企业营销目的 ...
- 使用OpenCV和Python构建自己的车辆检测模型
概述 你对智慧城市的想法感到兴奋吗?如果是的话,你会喜欢这个关于建立你自己的车辆检测系统的教程的 在深入实现部分之前,我们将首先了解如何检测视频中的移动目标 我们将使用OpenCV和Python构建自 ...
- Android-PullToRefresh上拉下拉刷新加载更多,以及gridview刷新功能的Library下载地址
作者:程序员小冰,CSDN博客:http://blog.csdn.net/qq_21376985,转载请说明出处. 首先大家应该都听说过此开源框架的强大之处,支持单列以及双列的 上拉加载以及下拉刷新功 ...
- Unity动画优化
Unity动画优化 https://blog.csdn.net/TracyZly/article/details/79991593 Unity中Animator做UI动画的一些细节 https://b ...
- Android 设备指纹
Android唯一识别号(设备指纹)的生成及原理 https://blog.csdn.net/xiechengfa/article/details/70049409?utm_source=itdada ...
- Unity添加自定义拓展方法
Shepherdog|2014-04-08 10:50|16151次浏览|Unity(373)0 通常你会发现你不能修改正在使用的那些类,无论它是基础的数据类型还是已有框架的一部分,它提供的方法让你困 ...
- 熟练剖分(tree) 树形DP
熟练剖分(tree) 树形DP 题目描述 题目传送门 分析 我们设\(f[i][j]\)为以\(i\)为根节点的子树中最坏时间复杂度小于等于\(j\)的概率 设\(g[i][j]\)为当前扫到的以\( ...