NIO(一):Buffer缓冲区
一.NIO与IO:
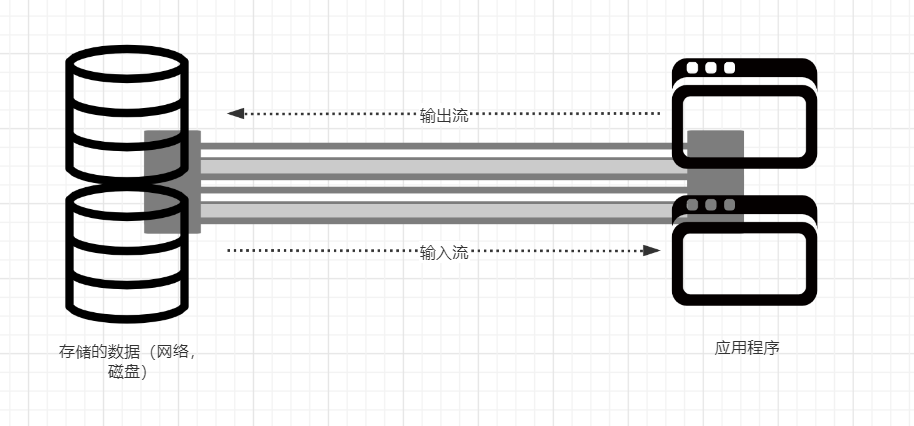
IO: 一般泛指进行input/output操作(读写操作),Java IO其核心是字符流(inputstream/outputstream)和字节流(reader/writer)做为基本进行操作,只能做单向操作,而IO的读写方式采用流的方式进行读写操作,如图所示
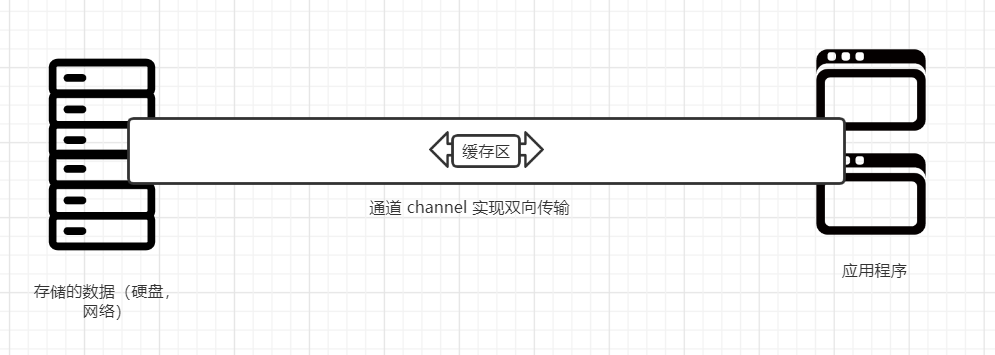
对于NIO既可以说是(NEW NIO) 也是(NON Blocking IO),为什么说他的性能和效率高于IO流,其的传输方式采用块传输方式,也就是使用缓冲区(buffer),使用channel(通道)进行双向传输。
其关键三个API为:
channel(通道): 实现数据的双向输出
Buffer(缓冲区):用于存储临时的读写数据
Selector(选择器) 若干客户端在Selector中注册自己,若干channel注册到Selector中,通过选择操作选出就绪的键,通道线程来实现少量线程的为多个客户端服务
二.Buffer缓冲区
什么是缓冲区?Buffer 是一个对象, 它包含一些要写入或者刚读出的数据。 在 NIO 中加入 Buffer 对象,体现了新库与原 I/O 的一个重要区别。在面向流的 I/O 中,您将数据直接写入或者将数据直接读到 Stream 对象中。
在内存中开辟一段连续的区域,进行临时存储,实际上缓冲区为一个数组,在Buffer中可以进行存储的数据类型为:
CharBuffer
FloatBuffer
IntBuffer
DoubleBuffer
ShortBuffer
LongBuffer
ByteBuffer
这些基本的实现都继承自Buffer类。
Buffer中定义了4个属性为:
private int mark = -1; //此属性将在随后说到
private int position = 0;
private int limit;
private int capacity;
其中:
不变性(以1,2,3,4为从低到高排序) |
||
position |
即将被读或写的位置 |
2 |
limit |
限制最大取出值/放入值,注意:position < limit |
3 |
capacity |
缓冲区中可以存储的最大容量 |
4 |
mark |
标记位置,用于标记某一次的读取/写入的位置 |
1 |
三.以ByteBuffer为例
在进行读写操作前需要开辟一个区域,对ByteBuffer进行初始化操作。
继承体系:
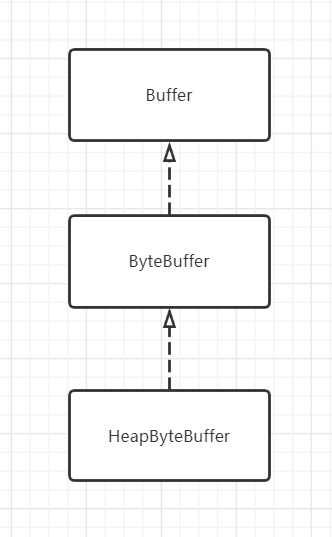
ByteBuffer bf = ByteBuffer.allocate(1024);
在使用allocate初始化中,进入方法中,当容量为负时,返回一个异常,反之初始化一个HeapByteBuffer
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
并进行对属性进行赋值并创建一个相应容量的Byte数组
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
/*
hb = new byte[cap];
offset = 0;
*/
}
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
由此完成便开辟一个区域用来存储数据
使用position 方法,limit方法,capacity方法查询相关信息,根据上面例子创建一个1024容量的缓冲区
//存储位置
System.out.println("position:---"+bf.position());
//存储限制大小
System.out.println("limit:---"+bf.limit());
//存储容量
System.out.println("capacity:---"+bf.capacity());

此时position所指向0的位置。limiit所指向1024的位置。

随后在进行写操作时使用put进行写入操作,
//为缓存区中存入数据
System.out.println("-------------put写入-------------");
//定义一个数据
String str= "123456";
bf.put(str.getBytes()); //将结果存储到新的字节数组中。
System.out.println("position:---"+bf.position());
System.out.println("limit:---"+bf.limit());
System.out.println("capacity:---"+bf.capacity());
此时:
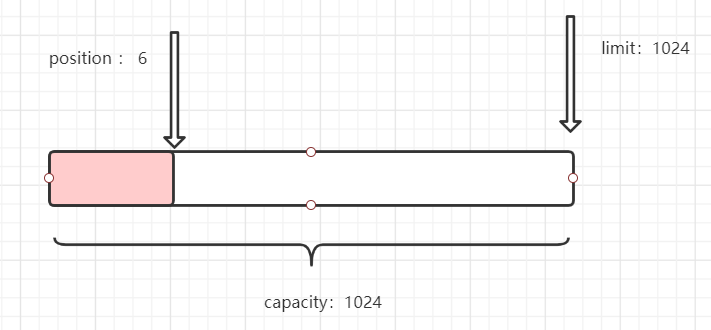
那么position是如何得知的那?
通过在HeapByteBuffer中position初始化为0+数据转化为byte数组后的长度加起来得到position的值。并记录
写入时,position < limit 此时limit没有变化,
public ByteBuffer put(byte[] src, int offset, int length) {
checkBounds(offset, length, src.length);
if (length > remaining())
throw new BufferOverflowException();
System.arraycopy(src, offset, hb, ix(position()), length);
position(position() + length);
return this;
这就完成了数据的写入,当想在缓冲区中读取数据时,在需要先切换至读取状态,使用flip方法,在Buffer中的flip方法中 ,定义了将position赋给limit 限制读取的最大长度。并使position置为0
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
进行切换状态
//写入 后切换为读取状态
System.out.println("-------------flip切换-------------");
/*
* 将limit = position
* 令 position = 0
* */
bf.flip(); //切换读取状态
System.out.println("position:---"+bf.position());
System.out.println("limit:---"+bf.limit());
System.out.println("capacity:---"+bf.capacity());

此时:
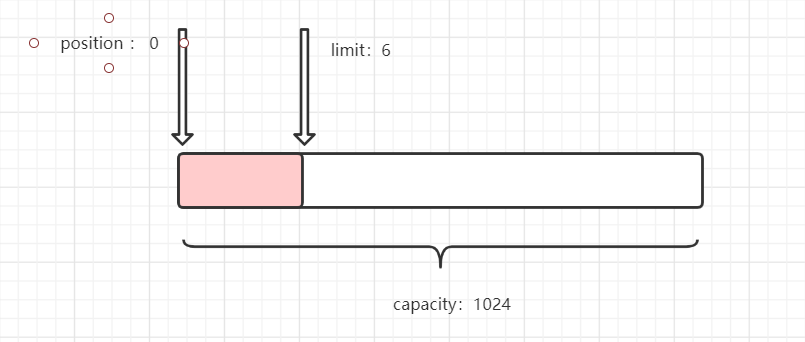
切换完成后,便进行读的操作。
//切换成功后进行读取
System.out.println("-------------get读取-------------");
/*
* 从零开始读 ,读6个长度停止
* */
bf.get(str.getBytes(), 0, 6);
System.out.println("position:---"+bf.position());
System.out.println("limit:---"+bf.limit());
System.out.println("capacity:---"+bf.capacity());
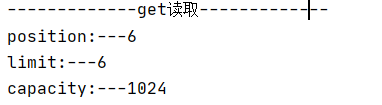
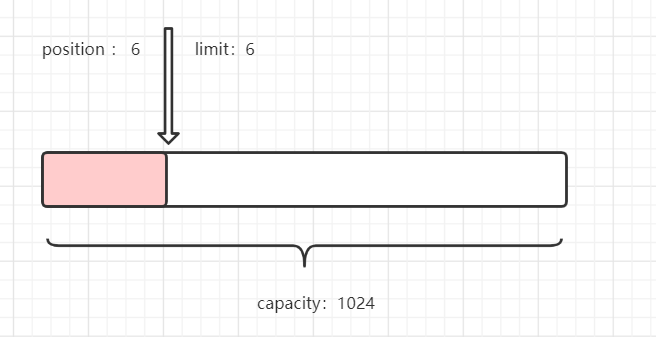
你也可以并不止于读写,还可以清空缓冲区。使用clear方法
/**
* Clears this buffer. The position is set to zero, the limit is set to
* the capacity, and the mark is discarded.
*
* <p> Invoke this method before using a sequence of channel-read or
* <i>put</i> operations to fill this buffer. For example:
*
* <blockquote><pre>
* buf.clear(); // Prepare buffer for reading
* in.read(buf); // Read data</pre></blockquote>
*
* <p> This method does not actually erase the data in the buffer, but it
* is named as if it did because it will most often be used in situations
* in which that might as well be the case. </p>
*
* @return This buffer
*/
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
根据官方注释解释,这里清除并非真正的清除数据,而是抹去了存在的痕迹。使它被遗忘掉。数据也是可读的。
//清空缓存区
System.out.println("-------------clear清空-------------"); bf.clear();
System.out.println("position:---"+bf.position());
System.out.println("limit:---"+bf.limit());
System.out.println("capacity:---"+bf.capacity());
//查看实际是否存在数据,并未被清除,只是被遗忘了。
System.out.println((char)bf.get(0));
System.out.println((char)bf.get(1));

此时:
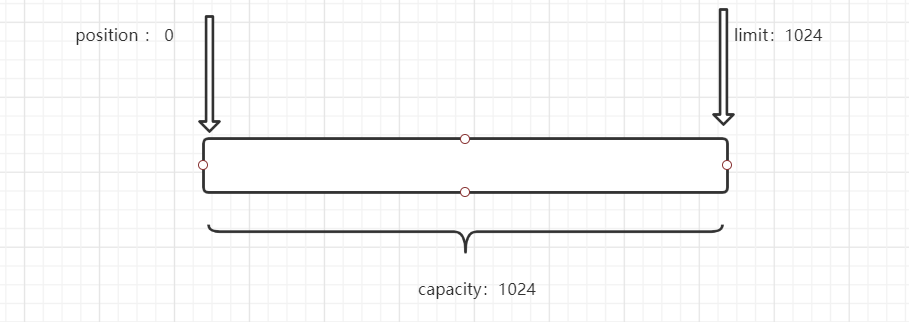
在Buffer中还提供了一些方法如下:
rewind() |
对缓冲区存入的数据重复读 |
remaining() |
统计属性间的元素数limit - position |
hasRemaining() |
统计当前位置中是否还有数据 |
部分引用内容载自:https://www.cnblogs.com/imstudy/p/11108085.html
NIO(一):Buffer缓冲区的更多相关文章
- Nio再学习之NIO的buffer缓冲区
1. 缓冲区(Buffer): 介绍 我们知道在BIO(Block IO)中其是使用的流的形式进行读取,可以将数据直接写入或者将数据直接读取到Stream对象中,但是在NIO中所有的数据都是使用的换冲 ...
- Java NIO 之 Buffer(缓冲区)
一 Buffer(缓冲区)介绍 Java NIO Buffers用于和NIO Channel交互. 我们从Channel中读取数据到buffers里,从Buffer把数据写入到Channels. Bu ...
- JAVA NIO简介-- Buffer、Channel、Charset 、直接缓冲区、分散和聚集、文件锁
IO 是主存和外部设备 ( 硬盘.终端和网络等 ) 拷贝数据的过程. IO 是操作系统的底层功能实现,底层通过 I/O 指令进行完成. Java标准io回顾 在Java1.4之前的I/O系统中,提供 ...
- Java NIO Buffer缓冲区
原文链接:http://tutorials.jenkov.com/java-nio/buffers.html Java NIO Buffers用于和NIO Channel交互.正如你已经知道的,我们从 ...
- Java NIO中的缓冲区Buffer(一)缓冲区基础
什么是缓冲区(Buffer) 定义 简单地说就是一块存储区域,哈哈哈,可能太简单了,或者可以换种说法,从代码的角度来讲(可以查看JDK中Buffer.ByteBuffer.DoubleBuffer等的 ...
- Java NIO之Buffer(缓冲区)
Java NIO中的缓存区(Buffer)用于和通道(Channel)进行交互.数据是从通道读入缓冲区,从缓冲区写入到通道中的. 缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这 ...
- NIO入门之缓冲区Buffer
缓存区 Buffer 是数据容器 ByteBuffer 可以存储除了 boolean 以外的其他 7 种Java基本数据类型,如 getInt.putInt Buffer 是抽象类,它有除了 Bool ...
- Java NIO(2):缓冲区基础
缓冲区(Buffer)对象是面向块的I/O的基础,也是NIO的核心对象之一.在NIO中每一次I/O操作都离不开Buffer,每一次的读和写都是针对Buffer操作的.Buffer在实现上本质是一个数组 ...
- NIO基础学习——缓冲区
NIO是对I/O处理的进一步抽象,包含了I/O的基础概念.我是基于网上博友的博客和Ron Hitchens写的<JAVA NIO>来学习的. NIO的三大核心内容:缓冲区,通道,选择器. ...
随机推荐
- 数据可视化之PowerQuery篇(十)如何将Excel的PowerQuery查询导入到Power BI中?
https://zhuanlan.zhihu.com/p/78537828 最近碰到星友的一个问题,他是在Excel的PowerQuery中已经把数据处理好了,但是处理后的数据又想用PowerBI来分 ...
- 金三银四,资深HR给面试者的十大建议
一.提前复习好你的专业知识 专业知识是最为重要的一点,拥有了坚实的专业基础,你才能迈向成功的彼岸. 因此,面试之前,一定一定要复习好专业知识.对自己学过的知识,要做一个概括,放在脑海中.茶余饭后,复习 ...
- Ethical Hacking - Web Penetration Testing(8)
SQL INJECTION WHAT IS SQL? Most websites use a database to store data. Most data stored in it(userna ...
- Python Ethical Hacking - Intercepting and Modifying Packets
INTERCEPTING & MODIFYING PACKETS Scapy can be used to: Create packets. Analyze packets. Send/rec ...
- 爆力破解Windows操作系统登录密码核心技术
一.不借助U盘等工具二.已将win7登录账户为test,密码为666666,全套C/C++黑客资料请加:726920220QQ 1.将电脑开机关机几次,进入以下界面
- 关于IDEA的一些快捷键操作
shift+F6修改实体类中的属性会重构代码
- jmeter接口测试 -- 数据库操作(mysql)
一.操作类型 语句类型 1.查询语句 2.非查询语句 1)update 2)insert into 3)删除 二.把返回值的化为变量 1.执行语句,并引用变量 2.查看结果
- Java基础知识_内存
前述:利用一段较为充足暑假时间,对以前的Java学习进行一个系统性的回顾,对于部分知识点进行记录和积累. Java中的内存 一 Java中的内存划分: Java中内存主要划分为五部分 栈(Stack) ...
- 看完这一篇,再也不怕面试官问到IntentService的原理
IntentService是什么 在内部封装了 Handler.消息队列的一个Service子类,适合在后台执行一系列串行依次执行的耗时异步任务,方便了我们的日常coding(普通的Service则是 ...
- Numpy访问数组元素
import numpy as np n = np.array(([1,2,3],[4,5,6],[7,8,9])) ''' array([[1, 2, 3], [4, 5, 6], [7, 8, 9 ...