ACL2020 Contextual Embeddings When Are They Worth It 精读
上下文嵌入(Bert词向量): 什么时候值得用?
ACL 2018
预训练词向量 (上下文嵌入Bert,上下文无关嵌入Glove, 随机)详细分析文章
1 背景
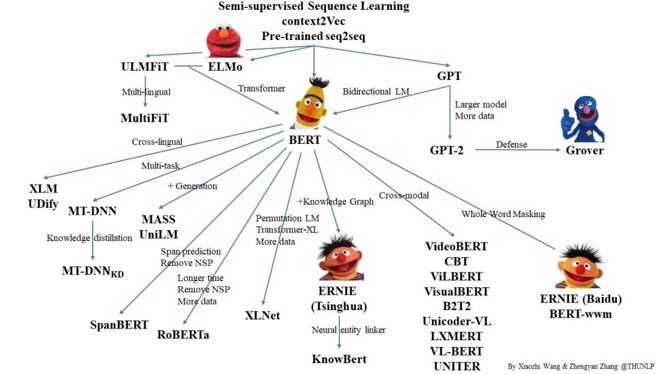
图1 Bert
| 优点 | 效果显著 |
| 缺点 | 成本昂贵 (Memory,Time, Money) (GPT-3,1700亿的参数量) |
| 困惑 | 线上环境,资源受限(内存 CPU GPU) bert不一定是最佳 选择 用word2vec, glove等词向量有时候也能取得近似效果 但什么时候可以近似,需要实验说明,于是作者设计了实验 |
2 三种词向量

图2 三种词向量
| 类型 | 说明 | 实验 |
|---|---|---|
| 上下文词嵌入 | BERT XLNet | 作者实验中选BERT 768维 |
| 上下文词无关嵌入 | Glove Word2Vec FastText | 作者实验中选Glove 300维 |
| 随机嵌入 | n*d矩阵 (n是词汇量, d是嵌入维度) | 作者实验中选循环随机嵌入 800维, 空间复杂度O(nd) => O(n) |
3 实验和结论
| 任务 | 模型 |
|---|---|
| 命名实体识别 (NER) | BiLSTM |
| 情感分析 (sentiment analysis) | TextCNN |
3.1 影响因素一:训练数据规模
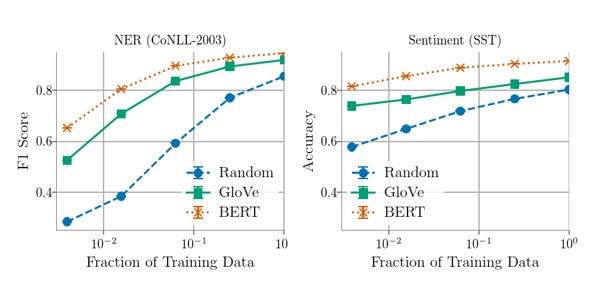
图3 影响因素一:训练数据规模 01
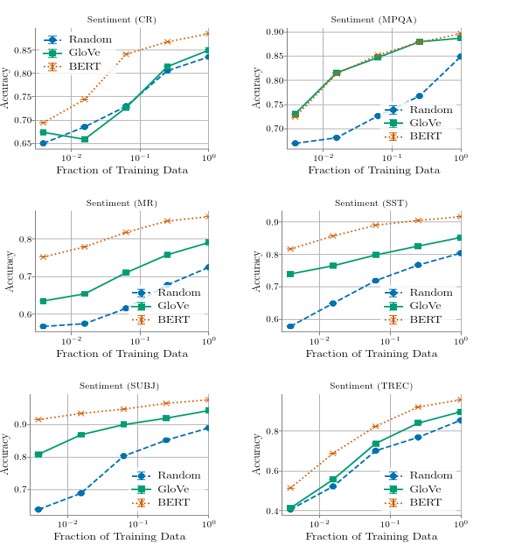
图4 影响因素一:训练数据规模 02
在许多任务中,供充足的数据,GloVe这些词向量可匹配BERT
3.2 影响因素二:语言的特性
3.2.1 Complexity of setence structure
NER: 实体占据几个token (George Washington)

图5 NER中的句子复杂度
Sentiment analysis:句子依存分析中依赖标记对之间的平均距离

图6 Sentiment analysis中的句子复杂度
3.2.2 Ambiguity in word usage
NER: 实体有几个标签(George Washington可以作为人名、地名、组织名)

图7 NER中的句子复杂度
Sentiment analysis:
\begin{array}{l}
H\left( {\frac{1}{{\left| S \right|}}\sum\limits_{w \in S} {p\left( { + 1\left| w \right.} \right)} } \right) \
{\rm{where }}H\left( p \right) = - p{\log _2}\left( p \right) - \left( {1 - p} \right){\log _2}\left( {1 - p} \right) \
\end{array}

图8 Sentiment analysis中的句子复杂度
3.2.3 Prevalence of unseen words
NER: token出现次数得倒数

图9 NER中的句子复杂度
Sentiment analysis:
给定一个句子,句子中未在训练集中出现token占比

图10 Sentiment analysis中的句子复杂度
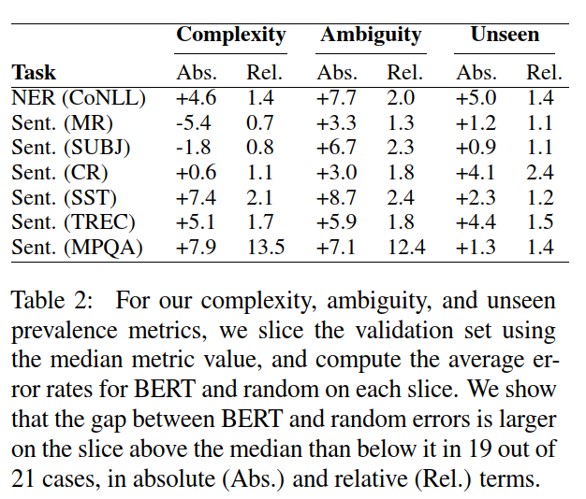
图11 Bert和随机向量对比
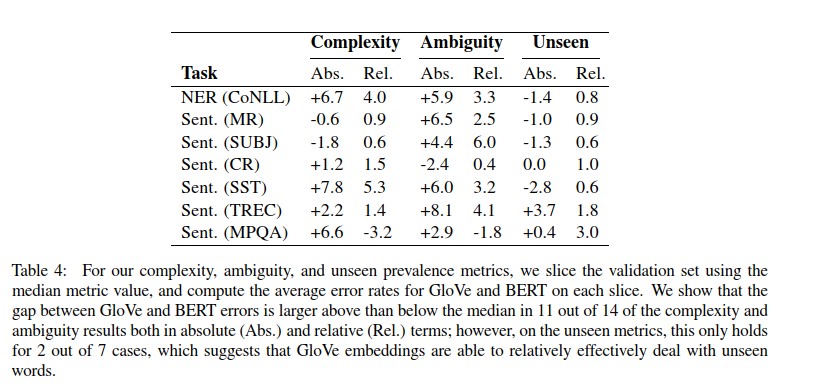
图12 Bert和Glove对比
文本结构复杂度高和单词歧义性方面: BERT更好
未登录词方面: GloVe 更好
总结
大量训练数据和简单语言的任务中,考虑算力和设备等,GloVe 代表的 Non-Contextual embeddings 是个不错的选择
对于文本复杂度高和单词语义歧义比较大的任务,BERT代表的 Contextual embeddings 有明显的优势。
未登录词方面: GloVe 更好
ACL2020 Contextual Embeddings When Are They Worth It 精读的更多相关文章
- Attention-over-Attention Neural Networks for Reading Comprehension论文总结
Attention-over-Attention Neural Networks for Reading Comprehension 论文地址:https://arxiv.org/pdf/1607.0 ...
- bert 硬件要求
https://github.com/google-research/bert BERT ***** New May 31st, 2019: Whole Word Masking Models *** ...
- 论文翻译——Deep contextualized word representations
Abstract We introduce a new type of deep contextualized word representation that models both (1) com ...
- 关于情感分类(Sentiment Classification)的文献整理
最近对NLP中情感分类子方向的研究有些兴趣,在此整理下个人阅读的笔记(持续更新中): 1. Thumbs up? Sentiment classification using machine lear ...
- 论文阅读笔记:《Contextual String Embeddings for Sequence Labeling》
文章引起我关注的主要原因是在CoNLL03 NER的F1值超过BERT达到了93.09左右,名副其实的state-of-art.考虑到BERT训练的数据量和参数量都极大,而该文方法只用一个GPU训了一 ...
- Word Embeddings: Encoding Lexical Semantics
Word Embeddings: Encoding Lexical Semantics Getting Dense Word Embeddings Word Embeddings in Pytorch ...
- Word Embeddings: Encoding Lexical Semantics(译文)
词向量:编码词汇级别的信息 url:http://pytorch.org/tutorials/beginner/nlp/word_embeddings_tutorial.html?highlight= ...
- Android Contextual Menus之二:contextual action mode
Android Contextual Menus之二:contextual action mode 接上文:Android Contextual Menus之一:floating context me ...
- Android Contextual Menus之一:floating context menu
Android Contextual Menus之一:floating context menu 上下文菜单 上下文相关的菜单(contextual menu)用来提供影响UI中特定item或者con ...
随机推荐
- Spring Boot 2.x基础教程:事务管理入门
什么是事务? 我们在开发企业应用时,通常业务人员的一个操作实际上是对数据库读写的多步操作的结合.由于数据操作在顺序执行的过程中,任何一步操作都有可能发生异常,异常会导致后续操作无法完成,此时由于业务逻 ...
- Quartz.Net系列(十一):System.Timers.Timer+WindowsService实现定时任务
1.创建WindowsService项目 2.配置项目 3.AddInstaller(添加安装程序) 4.修改ServiceName(服务名称).StartType(启动类型).Description ...
- tinymce 设置和获取编辑器的内容
$('目标元素').html(插入的内容) //设置tinymce编辑器的内容tinymce.get('目标元素').getContent() //获取tinymce编辑器的内容
- python 生成器(一):生成器基础(一)生成器函数
前言 实现相同功能,但却符合 Python 习惯的方式是,用生成器函数代替SentenceIterator 类.示例 14-5 sentence_gen.py:使用生成器函数实现 Sentence 类 ...
- 前端01 /HTML简单简绍
前端01 /HTML简单简绍 目录 前端01 /HTML简单简绍 1.web服务本质 2.浏览器的工作流程 3.HTML是什么 4.web服务本质 5.HTML文档结构 6.HTML注释 6.标签语法 ...
- bzoj2561最小生成树
bzoj2561最小生成树 题意: 给定一个连通无向图,假设现在加入一条边权为L的边(u,v),求需要删掉最少多少条边,才能够使得这条边既可能出现在最小生成树上,也可能出现在最大生成树上. 题解: 最 ...
- JavaScript动画实例:曲线的绘制
在“JavaScript图形实例:曲线方程”一文中,我们给出了15个曲线方程绘制图形的实例.这些曲线都是根据其曲线方程,在[0,2π]区间取一系列角度值,根据给定角度值计算对应的各点坐标,然后在计算出 ...
- Python Ethical Hacking - VULNERABILITY SCANNER(9)
Automatically Discovering Vulnerabilities Using the Vulnerability Scanner 1. Modify the run_scanner ...
- Ubuntu安装Redis过程完整笔记
在阿里云与百度云均已经安装成功~~ 下载文件 切换路径设置下载存放地址 cd /home 下载安装包(http://download.redis.io/releases建议下载最新稳定版本) sudo ...
- echarts爬坑 : 怎么Line折线图设置symbol:none后Label不见了?
用 echarts 时遇到了一个奇奇怪怪的问题. 这是一张折线图. 本来这个图是有数字显示的. series : [ { name:'搜索引擎', type:'line', stack: '总量', ...