基于Python实现的系统SLA可用性统计
基于Python实现的系统SLA可用性统计
1. 介绍
SLA是Service Level Agreement的英文缩写,也叫服务质量协议。根据SRE Google运维解密一书中的定义:
SLA是服务与用户之间的一个明确的,或者不明确的协议,描述了在达到或者没有达到SLO(
Service Level Objective)之后的后果。
SLO通常需要SLI(Service Level Indicator)去描述,系统常见的指标有吞吐量(每秒钟可处理的请求数量)、响应时间和可用性等,如系统的平均响应时间<500ms;系统可用性要达到99.99%。
在单体机器的架构中,系统的可用性可以近似等于正常运行时间/(正常运行时间+故障时间),但在分布式集群架构中,该计算方式不再适用,因为系统的可以被反向代理到其它的服务器上,服务呈现一直都可用。对于分布式系统,一般以请求的成功率计算系统的可用性(即服务器响应状态码<500的)。本文主要介绍一个分布式系统的SLA可用性统计的方法及其详细实现过程。
2. 所需环境及知识
| 软件 | 用途 | 知识参考 |
|---|---|---|
| Elasticsearch集群 | 系统日志存储中心,SLA中指标结果计算的数据来源 | range-on-date, terms-aggregation |
| MySQL数据库 | Elasticsearch集群聚合结果的持久化存储 | create-database, create-user, grant-overview, aggregate-function |
| Grafana | 使用MySQL作为数据源最终展示系统可用性 | MySQL Datasource |
| Python3 | 定时获取Elasticsearch集群数据并存储到MySQL | Python Elasticsearch Client, APScheduler-User-Guide, Connector-Python-Example |
知识详细说明:
- rang-on-date:Elasticsearch查询某个时间范围内的相关日志信息;
- terms-aggregation:Elasticsearch聚合查询的语法,这里需要聚合日志记录的状态码;
- create-database:创建数据库语法参考,创建的数据库存储Elasticsearch的日志聚合结果;
- create-user:创建数据库用户语法参考;
- grant-overview:授权用户权限语法参考,我这里授予用户拥有数据库的所有权限;
- aggregate-function:SQL聚合查询语法参考;
- MySQL Datasource:Grafana配置MySQL数据源及默认的查询宏函数的定义参考;
- Python Elasticsearch Client:Python连接到Elasticsearch的API,可以使用它查询Elasticsearch的信息;
- APScheduler-User-Guide:Python定时任务框架,这里需要定时任务查询Elasticsearch获取日志信息;
- Connector-Python-Example:Python连接MySQL数据库的Demo。
3. 总体思路
在Kibana上,我们可以通过Web页面查询查看Elasticsearch存储的记录,也可以使用Kibana的Visualize可视化Elasticsearch存储的数据。这里可以通过Python定时任务查询Elasticsearch的数据,然后过滤得到有用的数据存储到MySQL数据库中,最后借助Grafana的可视化图形Stat查询展示MySQL的结构化数据得到一个分布式系统的可用性(SA:Service Availability)近似值。SA计算公式:1- (响应码大于等于500的数量 / 请求总数)

4. 详细实现
4.1 Elasticsearch结构化查询语言
在此处,查询的时间范围为过去五分钟到现在的时间,而且还需要聚合服务器响应状态码字段,所以得到的DSL语句大致为:
"query": {
"bool": {
"filter": {
"range": {
"@timestamp": {
"gte": "2020-10-16T14:06:10",
"lt": "2020-10-16T14:11:10"
}
}
}
}
},
"size": 0,
"aggs": {
"group_by_status": {
"terms": {
"field": "http_response_code.keyword"
}
}
}
其中,gte表示时间大于等于timestring1,lt表示时间小于timestring2,查询的时间区间为[timestring1,timestring2);aggs是聚合查询,聚合的字段为http_response_code.keyword。我这里查询logstash-nginx-*索引,在Kibana上的Dev Tools上查询大致上可以得到以下结果:
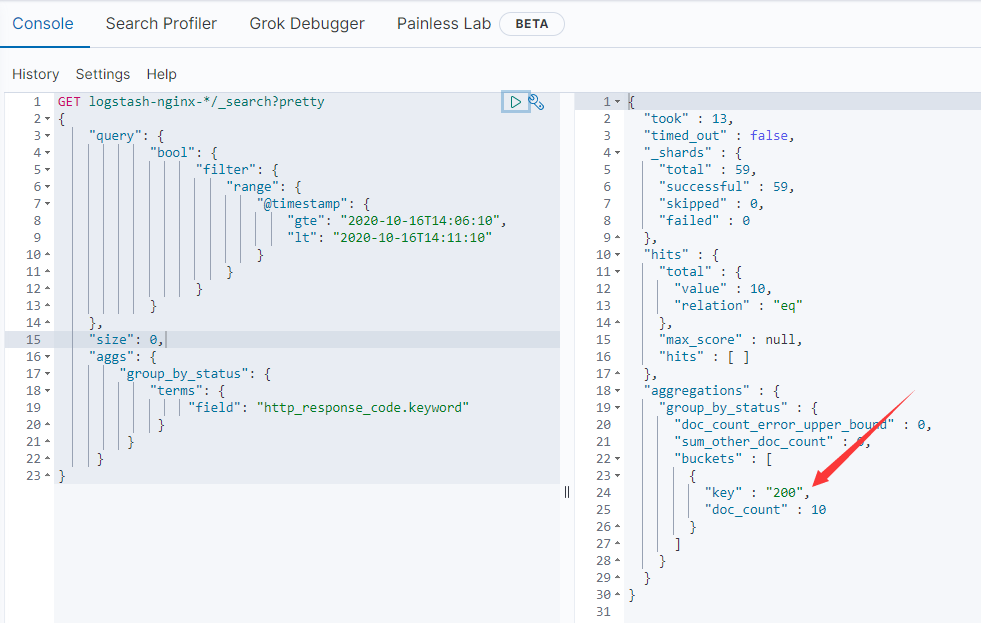
上图显示了聚合得到的状态码200的数量为10,如果有其它的状态码也会一一统计出来的。
4.2 Python使用Elasticsearch API
有了Elasticsearch的查询语句,还需要借助Elasticsearch的Python Client API才可以在Python程序中查询到Elasticsearch的数据。
- 安装Python Elasticsearch Client模块
pip install elasticsearch
- 查询Elasticsearch
from elasticsearch import Elasticsearch
# query ElasticSearch
es = Elasticsearch([{'host': self.elasticsearch_config["host"], 'port': self.elasticsearch_config["port"]}],
http_auth=(self.elasticsearch_config['username'], self.elasticsearch_config['password']))
response = es.search(index=self.elasticsearch_config['index'], body=self.elasticsearch_config["query_object"])
# get our needed buckets
buckets = response['aggregations']['group_by_status']['buckets']
其中的body参数为elasticsearch的查询语句,在此是封装成了JSON对象格式。
4.3 数据库准备
Python查询到的Elasticsearch数据结果需要持久化到MySQL数据库,在此需要创建存储数据库、数据库用户及数据表。数据库表设计如下:
- es_sla表
| 字段 | 数据类型 | 说明 | 注释 |
|---|---|---|---|
| id | bigint(20) unsinged | 记录ID | 主键,自动递增 |
| from_time | datetime | 开始时间 | |
| from_timestamp | int unsigned | 开始时间的Unix时间戳 | 与from_time表示的时间一致,只是类型不一样 |
| to_time | datetime | 结束时间 | |
| to_timestamp | int unsigned | 结束时间的Unix时间戳 | 与to_time表示的时间一致,只是类型不一样 |
| status_code | smallint unsigned | 状态码 | |
| count | smallint unsigned | 对应状态码的数量 | |
| es_index | varchar(100) | 对应的查询Elasticsearch索引 |
- SQL语句
create database if not exists elasticsearch CHARACTER SET utf8 COLLATE utf8_general_ci;
create user elastic identified by '123456';
grant all privileges on elasticsearch.* to elastic;
create table es_sla
(
id bigint(20) unsigned primary key auto_increment,
from_time datetime,
from_timestamp int unsigned,
to_time datetime,
to_timestamp int unsigned,
status_code smallint unsigned,
count smallint unsigned,
es_index varchar(100)
);
4.4 Python定时任务
这里设计的查询的是每五分钟就执行查询Elasticsearch数据操作,python的定时任务使用框架APScheduler。查阅资料,需要先安装模块,然后定义定时执行的函数,设置执行的触发器。
- 安装模块:
pip install apscheduler
- 设置每五分钟执行的定时器代码:
from apscheduler.schedulers.blocking import BlockingScheduler
# BlockingScheduler
scheduler = BlockingScheduler() #实例化定时器,如果要后台运行,可以使用BackgroundScheduler
scheduler.add_job(es_job.query_es_job, 'interval', seconds=5 * 60)
scheduler.start()
4.5 Python连接数据库及持久化
这里连接的MySQL数据库使用MySQL官方提供的连接器Connector,我把它封装成函数获取一个数据库连接对象。
- 安装模块
pip install mysql-connector mysql-connector-python
- 获取连接对象
import mysql.connector
def get_connection(db_config):
connection = mysql.connector.connect(user=db_config['username'],
password=db_config['password'],
host=db_config['host'],
database=db_config['database'])
return connection
- 插入数据表(持久化)
def insert_list(self, es_sla_list):
cursor = self.connection.cursor()
insert_sql = ("insert into es_sla (from_time,from_timestamp,to_time,"
"to_timestamp,status_code,count,es_index)"
"values (%(from_time)s,%(from_timestamp)s,"
"%(to_time)s,%(to_timestamp)s,%(status_code)s,%(count)s,%(es_index)s)")
row = 0
for es_sla in es_sla_list:
print(es_sla['status_code'])
cursor.execute(insert_sql, es_sla)
row = row + 1
if row == len(es_sla_list):
self.connection.commit()
else:
row = 0
cursor.close()
return row
4.6 定时任务执行内容
在前面的4.1-4.5中,我介绍了一些基础,最终还是要定时任务执行的操作完成具体的Elasticsearch查询操作和数据持久化操作。定时任务的详细具体执行过程如下:

- 具体实现代码:
# function which query elasticsearch job
def query_es_job(self):
# set up query time ranger
str_from_time = (datetime.utcnow() + timedelta(seconds=-300)).strftime('%Y-%m-%dT%H:%M:%S')
str_to_time = datetime.utcnow().strftime('%Y-%m-%dT%H:%M:%S')
self.elasticsearch_config["query_object"]["query"]["bool"]["filter"]["range"]["@timestamp"]['gte'] \
= str_from_time
self.elasticsearch_config["query_object"]["query"]["bool"]["filter"]["range"]["@timestamp"]['lt'] = str_to_time
# query ElasticSearch
es = Elasticsearch([{'host': self.elasticsearch_config["host"], 'port': self.elasticsearch_config["port"]}],
http_auth=(self.elasticsearch_config['username'], self.elasticsearch_config['password']))
response = es.search(index=self.elasticsearch_config['index'], body=self.elasticsearch_config["query_object"])
# get our needed buckets
buckets = response['aggregations']['group_by_status']['buckets']
# set up time format for database attributes
from_time = (datetime.strptime(str_from_time, '%Y-%m-%dT%H:%M:%S') + timedelta(hours=8))\
.strftime('%Y-%m-%d %H:%M:%S')
to_time = (datetime.strptime(str_to_time, '%Y-%m-%dT%H:%M:%S') + timedelta(hours=8))\
.strftime('%Y-%m-%d %H:%M:%S')
if len(buckets) > 0 and buckets is not None:
# construct record object list
es_sla_list = []
for bucket in buckets:
es_sla = {
'from_time': from_time,
'from_timestamp': int(time.mktime(time.strptime(from_time, '%Y-%m-%d %H:%M:%S'))),
'to_time': to_time,
'to_timestamp': int(time.mktime(time.strptime(to_time, '%Y-%m-%d %H:%M:%S'))),
'status_code': int(bucket['key']),
'count': bucket['doc_count'],
'es_index': self.elasticsearch_config['index']
}
es_sla_list.append(es_sla)
# create ES_SLA_DAO object and insert
es_sla_dao = ES_SLA_DAO(self.database_config)
row = es_sla_dao.insert_list(es_sla_list)
if row == len(es_sla_list):
print_message('execute sql success.')
else:
print_message('execute sql fail.')
else:
print_message('Buckets length is 0. Noting to do.')
4.7 Grafana展示SA数据
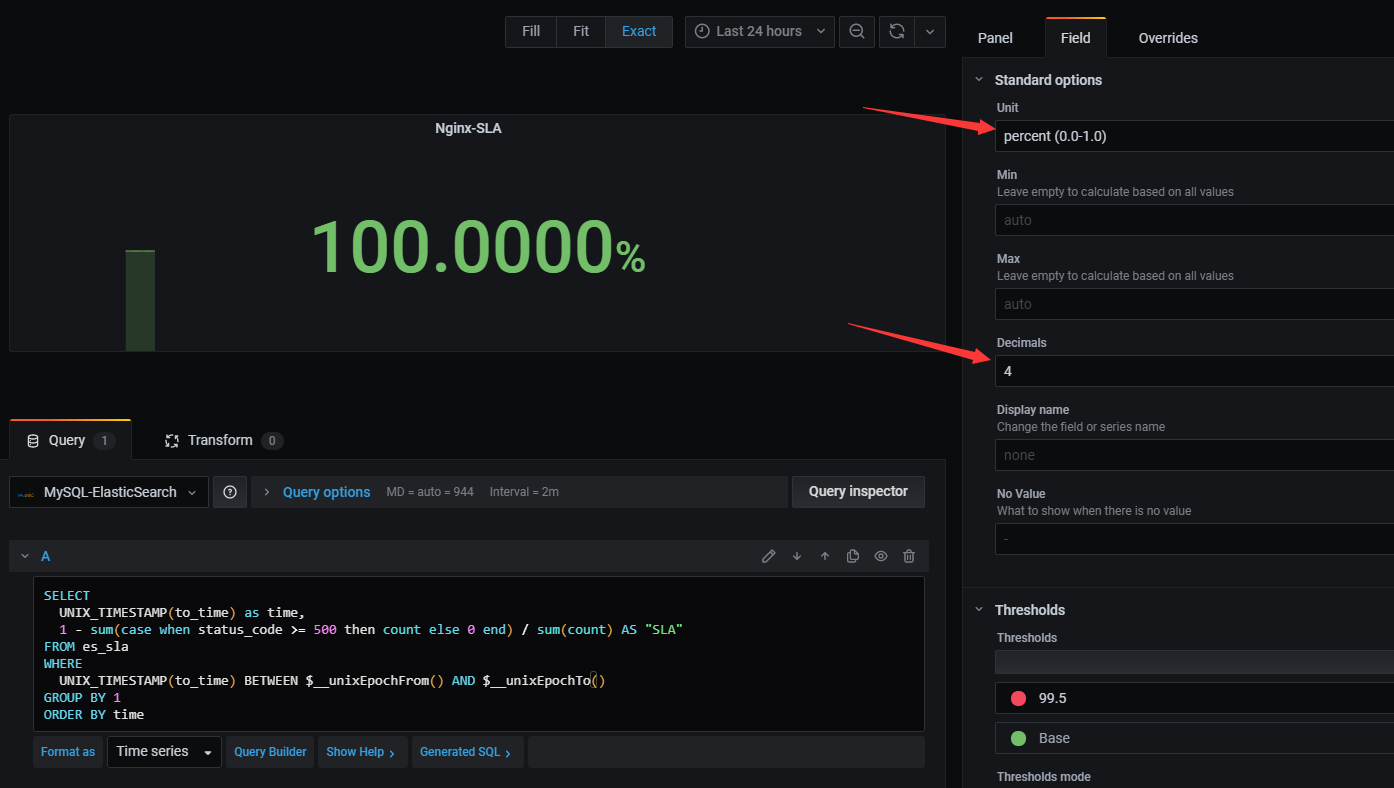
Grafana展示系统可用性SA是通过配置MySQL数据库源的,然后在Dashboard面板上添加Stat图。在我这里是直接编辑SQL语句查询出来,使用MySQL记录es_sla表,以to_time(结束时间)作为Grafana的时间戳,依据公式SA = 1- (响应码大于等于500的数量 / 请求总数)进行查询。
- SQL语句
SELECT
UNIX_TIMESTAMP(to_time) as time,
1 - sum(case when status_code >= 500 then count else 0 end) / sum(count) AS "SLA"
FROM es_sla
WHERE
UNIX_TIMESTAMP(to_time) BETWEEN 1603249298 AND 1603335698
GROUP BY 1
ORDER BY time
- SQL添加Grafana宏函数
SELECT
UNIX_TIMESTAMP(to_time) as time,
1 - sum(case when status_code >= 500 then count else 0 end) / sum(count) AS "SLA"
FROM es_sla
WHERE
UNIX_TIMESTAMP(to_time) BETWEEN $__unixEpochFrom() AND $__unixEpochTo()
GROUP BY 1
ORDER BY time
根据Grafana的参考资料,$__unixEpochFrom()表示当前选择的开始时间(UNIX_TIMESTAMP),$__unixEpochTo()表示当前选择的结束时间(UNIX_TIMESTAMP)。还需要调整显示的stat图形的单位为0.0~1.0的百分数,保留4位小数,如下图所示:
5. 资料
所有的代码我上传到GitHub仓库:es-sla . 项目文件结构如下图所示:
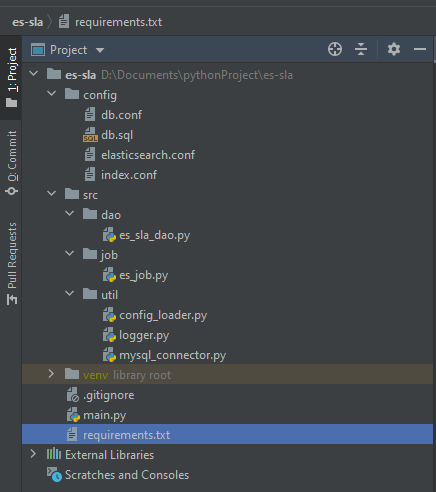
- 说明:
| 目录/文件 | 说明 |
|---|---|
| config | 配置目录,放置了ES的配置文件elasticsearch.conf、MySQL数据库配置文件db.conf、建表语句文件db.sql和待查询的ES索引存储文件index.conf |
| src | 源码目录,包括数据库的操作dao,定时任务job和一些工具包 |
| main.py | 主执行程序,主要是加载配置文件,创建定时任务执行 |
| .gitignore | git忽略文件的配置文件 |
| requirement.txt | Python程序所需的模块包,可以执行pip install -r requirement.txt安装 |
基于Python实现的系统SLA可用性统计的更多相关文章
- 基于python 信用卡评分系统 的数据分析
基于python 信用卡评分系统 的数据分析 import pandas as pd import matplotlib.pyplot as plt #导入图像库 from sklearn.ensem ...
- 基于Redis位图实现系统用户登录统计
项目需求,试着写了一个简单登录统计,基本功能都实现了,日志数据量小.具体性能没有进行测试~ 记录下开发过程与代码,留着以后改进! 1. 需求 1. 实现记录用户哪天进行了登录,每天只记录是否登录过,重 ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时监控Android系统和应用进程
基于Python结合InfluxDB及Grafana图表实时监控Android系统和应用进程 By: 授客 QQ:1033553122 1. 测试环境 2. 实现功能 3. 使用前提 4. ...
- 数据分析:基于Python的自定义文件格式转换系统
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- 看我如何基于Python&Facepp打造智能监控系统
由于种种原因,最近想亲自做一个基于python&facepp打造的智能监控系统. 0×00:萌芽 1:暑假在家很无聊 想出去玩,找不到人.玩个lol(已卸载),老是坑人.实在是无聊至极,不过, ...
- 使用Python获取Linux系统的各种信息
哪个Python版本? 当我提及Python,所指的就是CPython 2(准确的是2.7).我会显式提醒那些相同的代码在CPython 3 (3.3)上是不工作的,以及提供一份解释不同之处的备选代码 ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据
基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据 by:授客 QQ:1033553122 实现功能 测试环境 环境搭建 使用前提 使用方法 运行程序 效果展 ...
- 基于python的opcode优化和模块按需加载机制研究(学习与个人思路)(原创)
基于python的opcode优化和模块按需加载机制研究(学习与思考) 姓名:XXX 学校信息:XXX 主用编程语言:python3.5 个人技术博客:http://www.cnblogs.com/M ...
随机推荐
- mysql主从双机keepalived配置
1.关闭selinux SELINUX=disabled 2.yum安装keepalived yum install -y keepalived 3.修改配置文件 主库配置文件: ! Configur ...
- LLVM程序分析日记之CMake使用
我们编写LLVM Pass或者将LLVM嵌入自己的项目时,需要用到CMake来组织自己的项目目录. Documents [1] http://llvm.org/docs/CMake.html#embe ...
- windows宿主机访问ubuntu虚拟机中的docker服务
查看docker容器地址和虚拟机地址 windows主机中添加路由 #route -p add 172.17.0.0 mask 255.255.0.0 虚拟机地址 route -p add 172.1 ...
- [日常摸鱼]poj1741Tree-点分治
还有两天就要去FJWC啦- 题意:一颗无根树,$k$为给定常数,求树上距离不超过$k$的点对的数量,多组数据,$n \leq 10^4$. 应该是点分治经典题~ 一般对于无根树我们都可以把它转变成有根 ...
- 8. 老板 不加薪,我用了 这篇 加了 3K
在K8S中,容器本身是非持久化的,当容器崩溃后,kubelet将以镜像的初始状态重新启动容器,但是此时之前容器的数据已经丢失,我们该如何保护好容器的数据呢? 在同一Pod中的容器往往需要共享一些数据, ...
- ubuntu20.04 LTS 更换国内163源、阿里源、清华源、中科大源
Ubuntu 20.04 是 Ubuntu 的第 8 个 LTS 版本,其重大更新和改进将在 2030 年前终止,计划于2020年 4 月 23 日发布. 国内有很多Ubuntu的镜像源,有阿里的.网 ...
- python简单爬去前程无忧信息招聘
import sys reload(sys) sys.setdefaultencoding('utf-8') import requests import csv from BeautifulSoup ...
- .net MVC 微信公众号 点击菜单拉取消息时的事件推送
官方文档:https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421141016&token=&lang=zh_CN ...
- [.NET] - 基础知识 - .NET Overview
.NET Framework是有一个Framework Class Libray(FCL)和一个Common Language Runtim环境构成的,它 提供一个一致的面向对象的编程环境,而无论对象 ...
- 简单介绍下各种 JavaScript 解析器
作者:沧海 各种js解析器是前端工程化的基石,可以说如果没有它,很多工程化都无法正常执行,我们每天用到的babel.webpack.eslint.TypeScript背后都需要一套对应的js解析器,今 ...