简要MR与Spark在Shuffle区别
一、区别
①本质上相同,都是把Map端数据分类处理后交由Reduce的过程。
②数据流有所区别,MR按map, spill, merge, shuffle, sort, r
educe等各阶段逐一实现。Spark基于DAG数据流,可实现更复杂数据流操作(根据宽/窄依赖实现)
③实现功能上有所区别,MR在map中做了排序操作,而Spark假定大多数应用场景Shuffle数据的排序操作不是必须的,而是采用Aggregator机制(Hashmap每个元素<K,V>形式)实现。(下面有较详细说明)
ps:为了减少内存使用,Aggregator是在磁盘进行,也就是说,尽管Spark是“基于内存的计算框架”,但是Shuffle过程需要把数据写入磁盘
二、MR中的Shuffle
在MR框架中,Shuffle是连接Map和Reduce之间的桥梁,Map的输出结果需要经过Shuffle过程之后,也就是经过数据分类以后再交给Reduce进行处理。因此,Shuffle的性能高低直接影响了整个程序的性能和吞吐量。由此可知,Shuffle是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。因此,MapReduce的Shuffle过程分为Map端的操作和Reduce端的操作,如下图:
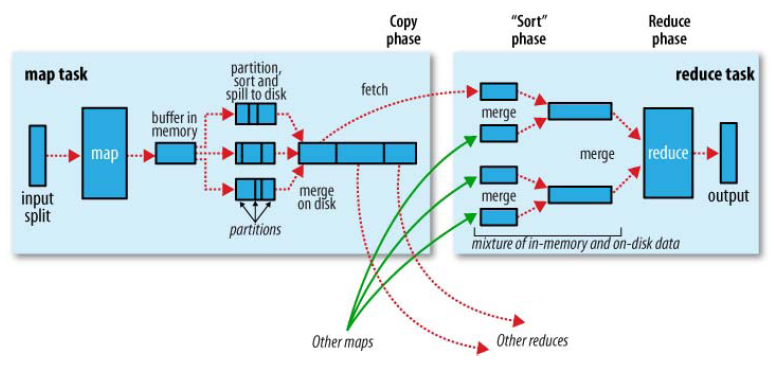
简单点说: Map端Shuffle过程,就是对Map输出结果写入缓存、分区、排序、合并再写入磁盘。
Reduce端Shuffle过程,就是从不同Map机器取回输出进行归并后交给Reduce进行处理。
三、Spark中的Shuffle
①、Spark作为MR框架的改进,也实现了Shuffle的逻辑,如下图:
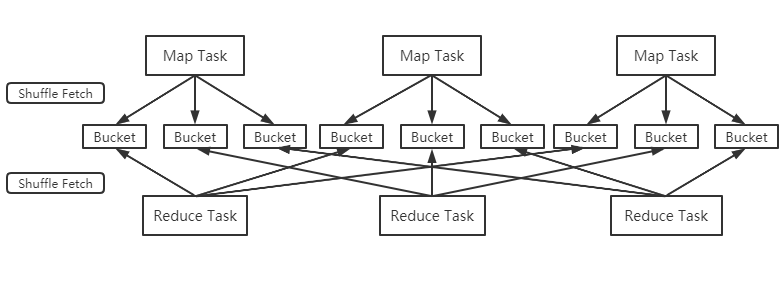
Map端的Shuffle写入(Shuffle Write)方面,每个Map根据Reduce任务的数量创造相应桶数量m*r(桶为抽象概念,m是map任务r是reduce任务),Map任务产生的结果根据分区算法(默认hash)到不同桶中。当Reduce任务启动时,会根据自己任务的id和所依赖的Map任务的id,从远端或本地取得对应的桶,作为Reduce任务的输入进行处理。
ps:在Spark1.2的版本后,Shuffle引擎改为SortShuffleManager(原来为HashShuffleManager),也就是把每个Map任务所有输出数据都写到同一个任务中,避免小文件太多对性能的影响。因此Shuffle过程中,每个Map任务会产生数据文件及所有文件两个。
②、在Reduce端的Shuffle读取(Shuffle Fetch)方面,大多数场景Spark并不在Reduce端做归并和排序,而是采用Aggregator机制。Aggregator本质是个HashMap,其中每个元素都是<K,V>形式。
ps:以词频统计为例,它会将从Map端拉取到的每一个(key,value),更新或插入到HashMap中。若在HashMap中没有查找到这个key,则把这个(key,value)插入其中;若找到这个key,则把value的值累加到V上去。这样就不需要预先把所有的(key,value)进行归并和排序,而是来一个处理一个,避免外部排序这一步骤。
③、窄依赖宽依赖
以是否包含Shuffle操作为判断依据,RDD中的依赖关系可以分为窄依赖与宽依赖,区别如下

窄依赖:一个父RDD的分区对应一个子RDD的分区,或者多个父RDD的分区对应一个子RDD的分区。典型操作包括map/filter/union等,不会包含Shuffle操作
宽依赖:一个父RDD的一个分区对应一个子RDD的多个分区。典型操作包括groupByKey/sortByKey等,通常包含Shuffle操作
ps:对于join操作,视情况而定,如上图左侧进行协同划分,数据窄依赖。如上图右侧做非协同划分,属于宽依赖。
④、阶段划分
Spark根据DAG图中的RDD依赖关系,把一个作业分成多个阶段。参考下图例子过程:
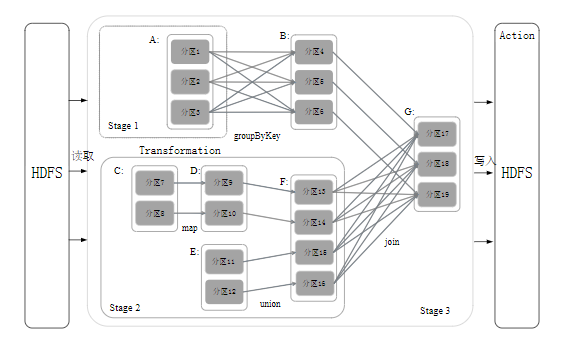
Stage2为窄依赖,可以把多个fork/join合并为一个,不但减少了大量的全局路障,而且无需保存很多中间结果RDD,可以极大提高性能,该过程叫流水线优化(Pipeline)
学习交流,有任何问题还请随时评论指出交流。
简要MR与Spark在Shuffle区别的更多相关文章
- spark.sql.shuffle.partitions和spark.default.parallelism的区别
在关于spark任务并行度的设置中,有两个参数我们会经常遇到,spark.sql.shuffle.partitions 和 spark.default.parallelism, 那么这两个参数到底有什 ...
- Spark的shuffle和MapReduce的shuffle对比
目录 MapperReduce的shuffle Spark的shuffle 总结 MapperReduce的shuffle shuffle阶段划分 Map阶段和Reduce阶段 任务 MapTask和 ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- 详细探究Spark的shuffle实现
Background 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环 节,shuffle的性能高低直接影响 ...
- [Spark] - HashPartitioner & RangePartitioner 区别
Spark RDD的宽依赖中存在Shuffle过程,Spark的Shuffle过程同MapReduce,也依赖于Partitioner数据分区器,Partitioner类的代码依赖结构主要如下所示: ...
- 【Spark篇】---Spark中Shuffle文件的寻址
一.前述 Spark中Shuffle文件的寻址是一个文件底层的管理机制,所以还是有必要了解一下的. 二.架构图 三.基本概念: 1) MapOutputTracker MapOutputTracker ...
- 【Spark篇】---Spark中Shuffle机制,SparkShuffle和SortShuffle
一.前述 Spark中Shuffle的机制可以分为HashShuffle,SortShuffle. SparkShuffle概念 reduceByKey会将上一个RDD中的每一个key对应的所有val ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
随机推荐
- 使用IDEA搭建SpringBoot进行增删改查
功能环境:java1.8以上 .IntellJIDEA First: 创建项目,请根据项目图一步一步完成建立. 二.配置数据库 三.创建实体对象建表或对应存在表,根据需要加入相应注解 四.创建应用 ...
- 前端使用canvas生成盲水印的加密解密
为了保障信息安全,防止重大信息泄露,并且能够锁定泄露用户,需要对页面展示的图片加入当前用户信息的盲水印,即最终图片外观看起来和原图一样,但是经过解码以后可以识别出水印信息,并且在截图后仍能进行较好的识 ...
- 用 Roslyn 做个 JIT 的 AOP
0. 前言 上接:AOP有几种实现方式 接下来说说怎么做AOP的demo,先用csharp 说下动态编织和静态编织,有时间再说点java的对应内容. 第一篇先说Roslyn 怎么做个JIT的AOP d ...
- 3分钟快速搞懂Java的桥接方法
什么是桥接方法? Java中的桥接方法(Bridge Method)是一种为了实现某些Java语言特性而由编译器自动生成的方法. 我们可以通过Method类的isBridge方法来判断一个方法是否是桥 ...
- CMake将生成的可执行文件保存到其他目录
在运行一些程序的时候,我们一般会把数据文件放在其他位置.而当在修改程序时,需要不断的修改代码,编译,执行.每次编译之后,都得将可执行文件复制到数据文件的目录. 这一问题有两种解决方法,一是直接在数据目 ...
- sqlmap进阶篇—POST注入三种方法
测试是否存在post注入 第一种方法 直接加--form让它自动加载表单 第二种方法 把form表单里面提交的内容复制出来,放到data中跑 第三种方法 先用burp suite抓包,把包的内容存到本 ...
- CCNP第二天之复习CCNA
1.静态路由的扩展配置: (1).环回接口: 在设备上用于测试TCP/IP协议栈能否正常使用.默认没有.需要手工创建 R1(config)#interface loopback 1 ...
- Web自动化测试:xpath & CSS Selector定位
Xpath 和 CSS Selector简介 CSS Selector CSS Selector和Xpath都可以用来表示XML文档中的位置.CSS (Cascading Style Sheets)是 ...
- 自定义 demo 集合
各种写着玩的自定义控件demo 有时网上看到一些比较有意思的开源项目,有时间的话就会自己也撸一个出来,但是一般只关注实现样式.动画等,不会太去细致完整地完成,俗称占个坑~ 持续更新中... githu ...
- Mac苹果电脑安装虚拟机
Mac上的虚拟机推荐安装 Parallel Desktop For Mac 1.安装Parallel Desktop 2.下载Windows7 3.用Parallel Desktop安装Window ...