Tensorflow学习笔记No.10
多输出模型
使用函数式API构建多输出模型完成多标签分类任务。
数据集下载链接:https://pan.baidu.com/s/1JtKt7KCR2lEqAirjIXzvgg 提取码:2kbc
1.读取数据并构建数据集
详细的API介绍在Tensorflow学习笔记5.0中均有提及,这里只简单讲述方法流程并展示代码。
1.1图片数据读取
首先导入需要的模块(运行环境为jupyternotebook)。
1 import tensorflow as tf
2 import numpy as np
3 import pathlib
4 import matplotlib.pyplot as plt
5 import random
6 %matplotlib inline
创建地址为数据所在位置的根目录,所创建的data_root为一个WindowsPath类型的变量。。
1 data_dir = 'E:/BaiduNetdiskDownload/多输出模型数据集(同时预测物品和颜色)/multi-output-classification/dataset'
2 data_root = pathlib.Path(data_dir)
读取该目录下所有的jpg/jpeg文件,图片存储位置为dataset/(标签文件夹)/*,所以使用.glob('*/*')来获取所有的图片文件。
1 all_image_path = list(data_root.glob('*/*'))
2 image_count = len(all_image_path) #共计2525张图片
1.2标签读取
在读取完图片之后,我们还要读取图片对应的标签信息。
我们所进行的是一个衣服分类任务,每件衣服都有颜色和类型两个标签,我们需要提取出每张图片对应的标签。
图片存储在名字为“颜色_类型”的文件夹下,对应了这些图片的颜色和类型,所以我们对文件夹名字进行处理即可。
首先我们获取所有含有标签信息的文件夹名称。
1 label_names = sorted(item.name for item in data_root.glob('*') if item.is_dir())
label_names中包含了所有的标签名称——['black_jeans', 'black_shoes', 'blue_dress', 'blue_jeans', 'blue_shirt', 'red_dress', 'red_shirt']。总共七种类别,为三种颜色类别和四种衣服类型的组合。
下一步奖颜色和类型标签分别提取出来,使用.split('_')对字符串进行分割,得到每个复合标签对应的两个基本标签。
1 color_label = set(name.split('_')[0] for name in label_names)
2 item_label = set(name.split('_')[1] for name in label_names)
然后我们通过这两个存有标签的集合构建从标签字符串映射到数字编号的字典。
1 color_to_indx = dict((name, indx) for indx, name in enumerate(color_label))
2 item_to_indx = dict((name, indx) for indx, name in enumerate(item_label))
现在我们仅仅是获得了字典,而没有获得与图片对应的基本标签,下一步我们着手制作这些标签,一个图片应该对应两个标签。
首先获取每个图片与之对应的复合类别标签(颜色_类型标签)。
使用.parent.name方法获得WindowsPath对象的父文件夹名字,即图片的标签。
1 all_image_label = list(pathlib.Path(path).parent.name for path in all_image_path)
然后通过两个字典构建出每个图片的两个数字标签。
1 color_label = list(color_to_indx[label.split('_')[0]] for label in all_image_label)
2 item_label = list(item_to_indx[label.split('_')[1]] for label in all_image_label)
1.3数据集的构建
在获取完标签和图像地址后,我们利用这些信息来制作一个标准的数据集。
首先定义一个图像处理函数,用于读取并解码图像,同时归一化为统一的尺寸。
1 def load_pregrosess_image(path):
2 image = tf.io.read_file(path)
3 image = tf.image.decode_jpeg(image, channels = 3)
4 image = tf.image.resize(image, [224, 224])
5 image = tf.cast(image, tf.float32)
6 image = image / 255
7 #image = image * 2 - 1
8 return image
使用tf.data中提供的方法对图片地址进行切片操作,变成一个dateset类型的数据,然后使用.map方法利用刚刚定义的函数将地址处理为图像。
1 train_image_ds = tf.data.Dataset.from_tensor_slices(all_image_path)
2 image_data = train_image_ds.map(load_pregrosess_image)
同样的把两个标签也切片封装为dataset类型的文件,最后再把图片和标签合并变成完整的数据集。
1 label_data = tf.data.Dataset.from_tensor_slices((color_label, item_label))
2 dataset = tf.data.Dataset.zip((image_data, label_data))
随后按照8:2分为训练集和验证集即可。
1 BATCHSIZE = 8
2 train_count = int(image_count * 0.8)
3 test_count = image_count - train_count
4
5 train_dataset = dataset.take(train_count)
6 test_dataset = dataset.skip(train_count)
7
8 train_dataset = train_dataset.shuffle(train_count).repeat().batch(BATCHSIZE)
9 test_dataset = test_dataset.repeat().batch(BATCHSIZE)
至此数据集构建完毕,下一步将搭建模型并进行训练。
2.多输出模型
由于我们要预测图片的两个属性,颜色和衣服类型,同样的我们也需要两个输出,然而线性模型显然无法满足我们的需求。所以我们使用函数式API构建非线性模型来完成目标。
2.1构建模型
我们的模型结构为一个卷积神经网络和两个分类器,如图所示。(3D画图随手一画很丑见谅(。﹏。*))
由卷积神经网络提取特征,然后通过两个分类器输出图片在两个不同标签上的分类结果。
我们采用预训练的Mobile-Net作为卷积部分并冻结其可训练参数,使用函数式API搭建模型,注意这里有两个输出层,在keras.Model方法中用列表形式作为输入,同时给两个输出层添加name参数进行命名便于区分和后续调用。
函数式API在Tensorflow学习笔记No.2中有详细介绍这里也不再做赘述,预训练网络的使用在Tensorflow学习笔记No.8中有相关介绍。
1 input = tf.keras.Input(shape = (224, 224, 3))
2
3 mobile_net = tf.keras.applications.MobileNetV2(weights = 'imagenet', input_shape = (224, 224, 3), include_top = False)
4 mobile_net.trianable = False
5
6 x = mobile_net(input)
7 x = tf.keras.layers.GlobalAveragePooling2D()(x)
8 x1 = tf.keras.layers.Dense(1024, activation = 'relu')(x)
9 x2 = tf.keras.layers.Dense(1024, activation = 'relu')(x)
10 output_color = tf.keras.layers.Dense(3, activation = 'softmax', name = 'output_color')(x1)
11 output_item = tf.keras.layers.Dense(4, activation = 'softmax', name = 'output_item')(x2)
12
13 model = tf.keras.Model(inputs = input, outputs = [output_color, output_item])
将全连接层和softmax组合在一起作为分类器,按照上图所示方式进行连接即可。
得到的模型如下图所示,使用model.summary()进行查看:

2.2模型训练
不熟悉model.complie()和model.fit()方法的小伙伴可以翻看Tensorflow学习笔记No.1进行学习这里也不在赘述(主要是因为懒)。
注意,因为有两个分类器,所以对每个分类器要单独规定一个损失函数,使用字典的方式按照{输出层名称:损失函数,......}的格式指定分类器,前面对卷积命名也是方便此步骤的进行。
steps_per_epoch和validation_steps代表了训练集和验证集每一个epoch需要训练多少步,也就是数据总数/BATCH_SIZE。
注意学习率设置为0.0001等较小的学习率,使用较大的学习率会导致loss异常增大。
1 model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate=0.0001),
2 loss = {'output_color':'sparse_categorical_crossentropy',
3 'output_item':'sparse_categorical_crossentropy'},
4 metrics = ['acc']
5 )
6
7 history = model.fit(train_dataset,
8 steps_per_epoch = train_count//BATCHSIZE,
9 epochs = 5,
10 validation_data = test_dataset,
11 validation_steps = test_count//BATCHSIZE,
12 )
由于使用了预训练模型,只需要5个epochs便可以达到90%以上的准确率,得到如下所示结果(仅供参考)。
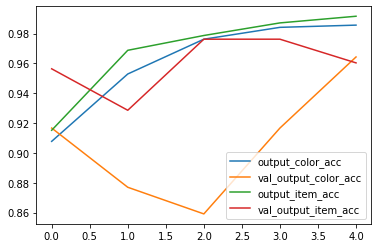
到这里多输出模型的实例就结束了,前段时间由于事情较多断更了一段时间,后续会继续更新Tensorflow的学习笔记。由于本人正在参加AI算法竞赛(入门菜鸡),后续可能会分享一些与竞赛有关的内容,撒悠娜拉 Bey~ o(* ̄▽ ̄*)ブ。
Tensorflow学习笔记No.10的更多相关文章
- Tensorflow学习笔记No.11
图像定位 图像定位是指在图像中将我们需要识别的部分使用定位框进行定位标记,本次主要讲述如何使用tensorflow2.0实现简单的图像定位任务. 我所使用的定位方法是训练神经网络使它输出定位框的四个顶 ...
- Tensorflow学习笔记2019.01.03
tensorflow学习笔记: 3.2 Tensorflow中定义数据流图 张量知识矩阵的一个超集. 超集:如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S ...
- TensorFlow学习笔记之--[compute_gradients和apply_gradients原理浅析]
I optimizer.minimize(loss, var_list) 我们都知道,TensorFlow为我们提供了丰富的优化函数,例如GradientDescentOptimizer.这个方法会自 ...
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- tensorflow学习笔记(4)-学习率
tensorflow学习笔记(4)-学习率 首先学习率如下图 所以在实际运用中我们会使用指数衰减的学习率 在tf中有这样一个函数 tf.train.exponential_decay(learning ...
- tensorflow学习笔记(3)前置数学知识
tensorflow学习笔记(3)前置数学知识 首先是神经元的模型 接下来是激励函数 神经网络的复杂度计算 层数:隐藏层+输出层 总参数=总的w+b 下图为2层 如下图 w为3*4+4个 b为4* ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
随机推荐
- 记录一次读取hdfs文件时出现的问题java.net.ConnectException: Connection refused
公司的hadoop集群是之前的同事搭建的,我(小白一个)在spark shell中读取hdfs上的文件时,执行以下指令 >>> word=sc.textFile("hdfs ...
- python之路《九》 迭代器与生成器
1.生成器 通过列表生成式,我们可以直接创建一个列表.但是,受到内存限制,列表容量肯定是有限的.而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面 ...
- nginx开启目录浏览
使用nginx作为下载站点,开启目录浏览的功能 在/etc/nginx/sites-enabled/default中添加: autoindex on ; autoindex_exact_size of ...
- 协程实现爬虫的例子主要优势在于充分利用IO时间去请求其他的url
# 分别使用urlopen和requests两个模块进行演示 # import requests # 需要安装的 # from urllib.request import urlopen # # ur ...
- sublime 3 phpfmt配置(大括号对齐)
默认选项: default: phpfmt.sublime-settings: { "version": 2, "php ...
- Fastjson远程代码执行漏洞复现
fastjson漏洞简介 Fastjson是一个Java库,可用于将Java对象转换为其JSON表示形式.它还可以用于将JSON字符串转换为等效的Java对象,fastjson爆出多个反序列化远程命令 ...
- Linux Command Line_1_Shell基础
引言 图形用户界面(GUI)让简单的任务更容易完成,命令行界面(CLI)使完成复杂的任务成为可能. 第一部分:Shell 本部分包括命令行基本语言,命令组成结构,文件系统浏览.编写命令行.查找命令 ...
- 【MathType教学】表示分类的大括号怎么打
大括号是一种常见的数学符号,可以用于集合.分段函数中,其实大括号还可以用来总结数学知识,比如对三角形进行分类,此时用的大括号可以称为表示分类的大括号.MathType作为专业的数学公式编辑器,可以快速 ...
- ubuntu安装imagick扩展
注意:安装该扩展不要求安装ImageMagick从http://pecl.php.net/package/imagick找到imagick的最新的版本 Linux代码 wget http://pecl ...
- pycharm2020激活破解和汉化
一:破解补丁和程序下载:链接:https://pan.baidu.com/s/1u-aZrKMmfRBlQHtcivUt8Q 提取码:tvko 二:破解步骤: 1.安装下载的pycharm202 ...