C# 爬取猫眼电影数据
最近做了一个新项目,因为项目需要大量电影数据,猫眼电影又恰好有足够的数据,就上猫眼爬数据了。
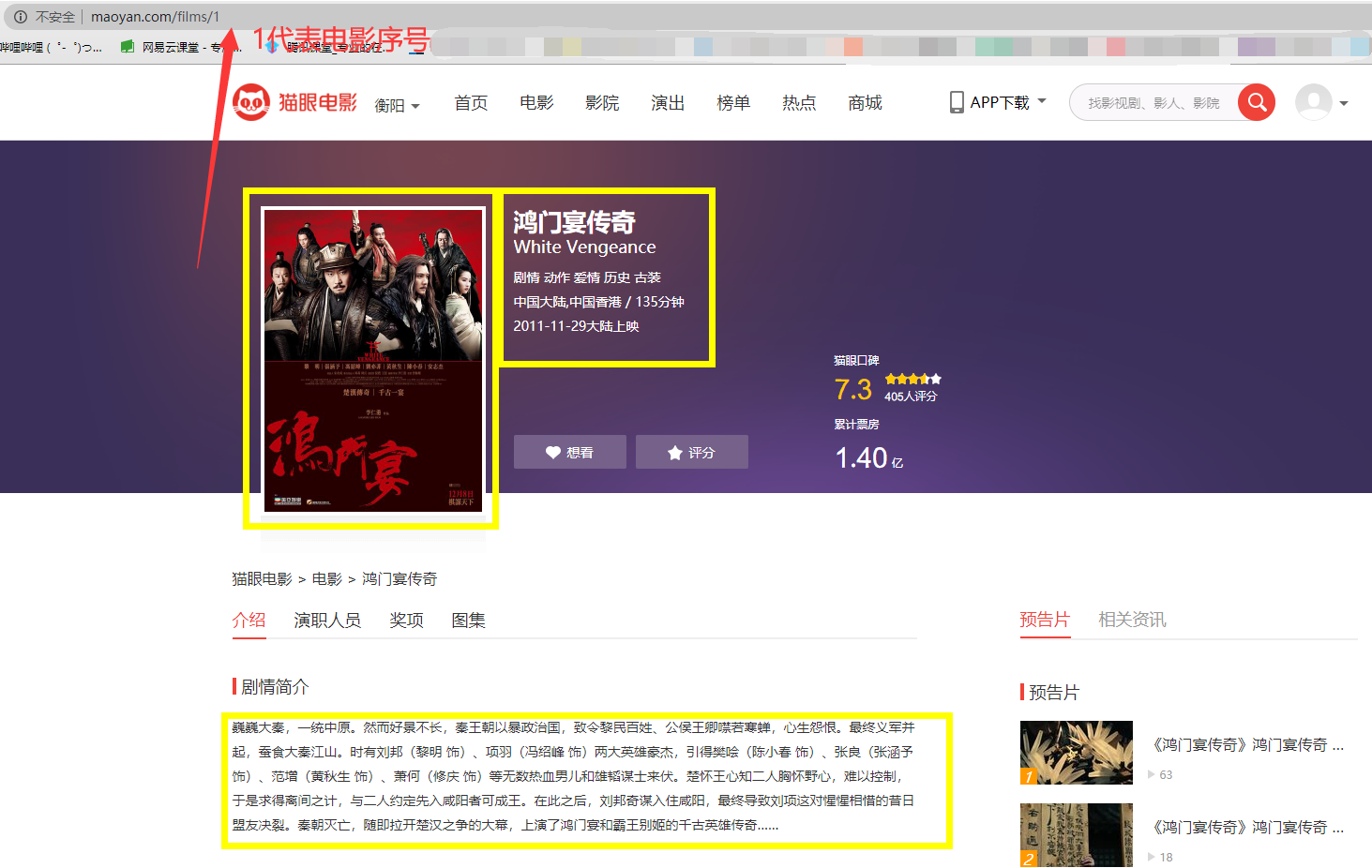
1、先分析一下网页地址,发现电影都是被排好序号了,这就很简单了。
2、在分析页面,这次主要爬取黄色框中的内容。在浏览器中按F12检查元素,只要把Div获取出来就算完成了。
下面贴代码:

主函数
static void Main(string[] args)
{
int errorCount = ;//计算爬取失败的次数
int count = ;//结束范围
for (int i = ; i <= count; i++)
{
Thread.Sleep();//每隔两秒爬取一次,不要给服务器压力
try
{
HtmlWeb web = new HtmlWeb();
//https://maoyan.com/films/1
web.OverrideEncoding = Encoding.UTF8;
HtmlDocument doc = web.Load($"https://maoyan.com/films/{i}");//把url中的1替换为i HtmlDocument htmlDoc = new HtmlDocument();
string url = $"https://maoyan.com/films/{i}"; //获取电影名
HtmlNode MovieTitle = doc.DocumentNode.SelectSingleNode("//div[@class='movie-brief-container']/h1[@class='name']");//分析页面结构后得到的div
if (MovieTitle == null)//如果是null,那么表明进入验证页面了,执行第二种方法
{
string urlResponse = URLRequest(url);
htmlDoc.LoadHtml(urlResponse);
MovieTitle = htmlDoc.DocumentNode.SelectSingleNode("//div[@class='movie-brief-container']/h1[@class='name']");
if (MovieTitle == null)//如果是null,那么表明进入验证页面了。(第二种方法也失效)
{
//此处需要进入浏览器手动完成验证 或者 自行分析验证页面实现自动验证
}
}
string title = MovieTitle.InnerText;
//Console.WriteLine(MovieTitle.InnerText); //获取电影海报
HtmlNode MovieImgSrc = doc.DocumentNode.SelectSingleNode("//div[@class='celeInfo-left']/div[@class='avatar-shadow']/img[@class='avatar']");
if (MovieImgSrc == null)
{ MovieImgSrc = htmlDoc.DocumentNode.SelectSingleNode("//div[@class='celeInfo-left']/div[@class='avatar-shadow']/img[@class='avatar']");
}
//Console.WriteLine(MovieImgSrc.GetAttributeValue("src", ""));
string imgurl = MovieImgSrc.GetAttributeValue("src", ""); //电影类型
HtmlNodeCollection MovieTypes = doc.DocumentNode.SelectNodes("//div[@class='movie-brief-container']/ul/li[@class='ellipsis']");
if (MovieTypes == null)
{
MovieTypes = htmlDoc.DocumentNode.SelectNodes("//div[@class='movie-brief-container']/ul/li[@class='ellipsis']");
}
string types = "", artime = "", releasetime = ""; foreach (var item in MovieTypes[].ChildNodes)
{
if (item.InnerText.Trim() != "")
{
//Console.WriteLine(item.InnerText.Trim());
types += item.InnerText.Trim() + "-";
}
}
artime = MovieTypes[].InnerText;
releasetime = MovieTypes[].InnerText;
//Console.WriteLine(MovieTypes[i].InnerText); //剧情简介
string intro = "";
HtmlNode introduction = doc.DocumentNode.SelectSingleNode("//div[@class='mod-content']/span[@class='dra']");
if (introduction == null)
{
introduction = htmlDoc.DocumentNode.SelectSingleNode("//div[@class='mod-content']/span[@class='dra']");
}
//Console.WriteLine(introduction.InnerText);
intro = introduction.InnerText;
//Console.WriteLine(i); using (FileStream fs = new FileStream(@"d:\Sql.txt", FileMode.Append, FileAccess.Write))
{
fs.Lock(, fs.Length);
StreamWriter sw = new StreamWriter(fs);
sw.WriteLine($"INSERT INTO Movies VALUES('{title}','{imgurl}','{types}','{artime}','{releasetime}','{intro.Trim()}');");
fs.Unlock(, fs.Length);//一定要用在Flush()方法以前,否则抛出异常。
sw.Flush();
} }
catch (Exception ex)
{
errorCount++;
Console.WriteLine(ex);
}
}
Console.WriteLine($"结束 成功:{count - errorCount}条,失败:{errorCount}条");
Console.ReadLine(); }
URLRequest方法
static string URLRequest(string url)
{
// 准备请求
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); // 设置GET方法
request.Method = "GET";
request.Timeout = ; //60 second timeout
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"; string responseContent = null; // 获取 Response
using (WebResponse response = request.GetResponse())
{
using (Stream stream = response.GetResponseStream())
{
// 读取流
using (StreamReader streamreader = new StreamReader(stream))
{
responseContent = streamreader.ReadToEnd();
}
}
} return (responseContent);
}
先进入for循环,到时候把url中的 1 替换为 i ,就可以实现自动爬取所有电影了。
解析html代码我用的是第三方类库 HtmlAgilityPack,大家可以在Nuget中搜索到。
我将爬取的数据转换为Sql语句了,存在D盘根目录下 Sql.txt。
下面是结果


一共爬了200条数据
大家注意一下,程序报错 如果是空异常,那么表明没有获取到相应的div,没有获取到相应的div就表明猫眼让你跳转到验证中心页面了,你要进入到浏览器验证一下,或者更换IP访问。
最后再提醒一下大家,要慢慢的获取数据,不然会403。
C# 爬取猫眼电影数据的更多相关文章
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
- 一起学爬虫——使用xpath库爬取猫眼电影国内票房榜
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜 XPATH语法 XPATH(XML Path Language)是一门用于从XML文件中 ...
- 14-Requests+正则表达式爬取猫眼电影
'''Requests+正则表达式爬取猫眼电影TOP100''''''流程框架:抓去单页内容:利用requests请求目标站点,得到单个网页HTML代码,返回结果.正则表达式分析:根据HTML代码分析 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- Python使用asyncio+aiohttp异步爬取猫眼电影专业版
asyncio是从pytohn3.4开始添加到标准库中的一个强大的异步并发库,可以很好地解决python中高并发的问题,入门学习可以参考官方文档 并发访问能极大的提高爬虫的性能,但是requests访 ...
随机推荐
- node实现图片分割
前言 最近,女王大大日常找我弄图片,本来之前我一直是ps帮他弄得,后来- -,ps不能分割过长的图片,我就想想能不能通过代码来帮他实现好了. 经过我在npm搜索一番,发现没有一个纯代码层面的high ...
- kka-typed(5) - cluster:集群节点状态监视
akka-cluster对每个节点的每种状态变化都会在系统消息队列里发布相关的事件.通过订阅有关节点状态变化的消息就可以获取每个节点的状态.这部分已经在之前关于akka-cluster的讨论里介绍过了 ...
- KVM Web管理平台 WebVirtMgr
WebVirtMgr介绍 WebVirtMgr是一个KVM管理平台,让kvm管理变得更为可视化,对中小型kvm应用场景带来了更多方便.WebVirtMgr采用几乎纯Python开发,其前端是基于Pyt ...
- 环境篇:CM+CDH6.3.2环境搭建(全网最全)
环境篇:CM+CDH6.3.2环境搭建(全网最全) 一 环境准备 1.1 三台虚拟机准备 Master( 32g内存 + 100g硬盘 + 4cpu + 每个cpu2核) 2台Slave( 12g内存 ...
- WinForm通用自动更新AutoUpdater项目实战
目前我们做的上位机项目还是以Winform为主,在实际应用过程中,可能还会出现一些细节的修改.对于这种情况,如果上位机带有自动更新功能,我们只需要将更新后的应用程序打包放在指定的路径下,可以让用户自己 ...
- netty实现消息中心(二)基于netty搭建一个聊天室
前言 上篇博文(netty实现消息中心(一)思路整理 )大概说了下netty websocket消息中心的设计思路,这篇文章主要说说简化版的netty聊天室代码实现,支持群聊和点对点聊天. 此demo ...
- 第一个SpringMVC程序 (配置版)
通过配置版本的MVC程序,可以了解到MVC的底层原理,实际开发我们用的是注解版的! 1.新建一个普通Maven的项目,然后添加web的支持 2.导入相关的SpringMVC的依赖 3.配置web.xm ...
- CentOS Linux release 7.7.1908 (Core)--rabbitmq用户创建以及相关防火墙端口开启问题
增加访问用户,默认用户guest只能本地访问. #添加用户 rabbitmqctl add_user 账号 密码 rabbitmqctl add_user admin admin #分配用户标签(ad ...
- 税务ukey如何批量开票
最近税局开始大力推税务ukey版本,不过目前接口还未开放,就连航信,百旺否还没有对应接口,所以自己研究了下,在之前税控基础上,谁知道搞定了,通过安装插件可以批量开票,包括纸质,电子发票ofd格式. 联 ...
- Task.Result跟 Task.GetAwaiter.GetResult()相同吗?怎么选?
前几天在用线程池执行一些任务时运到一种情形,就是回调方法中使用到了异步方法,但是回调方法貌似不支持async await的写法.这时候我应该如何处理呢?是使用Task.Result来获取返回结果,还是 ...