Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名、图片链接、名称、主演、上映时间。
思路:1.定义一个获取网页源代码的函数;
2.定义一个解析网页源代码的函数;
3.定义一个将解析的数据保存为本地文件的函数;
4.定义主函数;
5.使用多进程爬取。
步骤一:首先,导入相关的库:
import requests
import re
import json
from multiprocessing import Pool
from requests.exceptions import RequestException
步骤二:定义获取网页源代码的函数,这里使用 requests.get() 方法来获取,并调用异常处理方法:
def get_one_page(url):
response = requests.get(url)
try:
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
步骤三:定义一个函数,利用正则表达式 re.findall() 等函数解析网页源代码,并利用 yield 生成器对解析的代码进行排布,转换为字典形式:
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?">(\d+)</i>.*?data-src="(.*?)".*?</a>.*?'
+ '<a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'排名': item[0],
'图片': item[1],
'名称': item[2],
'主演': item[3].strip()[3:],
'上映时间': item[4].strip()[5:]
}
步骤四:定义主函数,爬取最受期待榜的 n 页:
def main(offset):
url = 'https://maoyan.com/board/6?offset=' +str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_one_page(item)
步骤五:多进程爬取,定义进程池,并调用 Pool.map() 方法进行多进程爬取,提高爬取效率:
if __name__ == "__main__":
pool = Pool()
pool.map(main, [i*10 for i in range(10)])
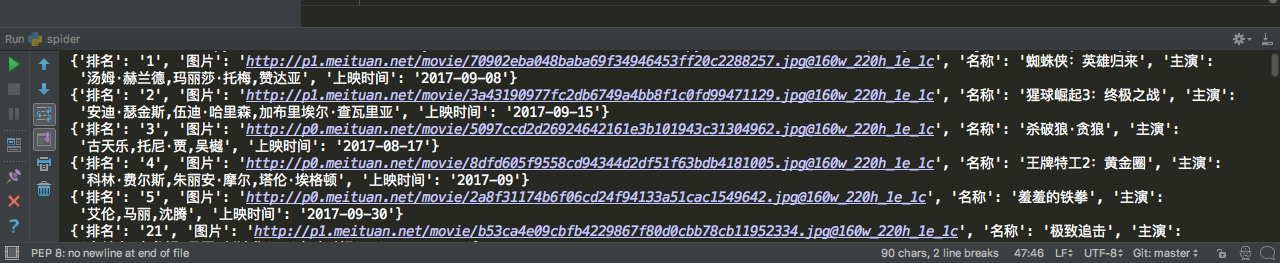
爬取的部分数据如下:
Python 爬取猫眼电影最受期待榜的更多相关文章
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 爬虫实战【4】Python获取猫眼电影最受期待榜的50部电影
前面几天介绍的都是博客园的内容,今天我们切换一下,了解一下大家都感兴趣的信息,比如最近有啥电影是万众期待的? 猫眼电影是了解这些信息的好地方,在猫眼电影中有5个榜单,其中最受期待榜就是我们今天要爬取的 ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- Python爬取猫眼电影《飞驰人生》47858万条评论并对其进行数据分析
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Yura不说数据说 ,PYuraL PS:如有需要Python学习资 ...
- Python 爬取猫眼电影《无名之辈》并对其进行数据分析
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接 ...
- Python爬取猫眼电影排行
import requests import pyquery def crawl_page(url: str) -> None: headers = { 'user-agent': 'Mozil ...
随机推荐
- Excel导出不同浏览器下文件名乱码问题
解决思路:通过请求头中的User-Agent参数中的信息来区分不同浏览器 public Object exportPz(HttpServletRequest request, HttpServletR ...
- Java虚拟机之类加载机制
⑴背景 Java虚拟机把Class文件加载到内存中,并对数据进行校验,转换解析,和初始化,最终形成被虚拟机直接使用的Java类型,这就是类加载机制. ⑵Jvm加载Class文件机制原理 类的生命周 ...
- eclipse如何debug调试jdk源码(任何源码)并显示局部变量
最近要看struts2源码 仿照了一下查看jdk源码的方式 首先你要有strtus2的jar包和源码,在struts官网上下载时,选择full版本,里面会有src也就是源码了. jar导入项目,保证可 ...
- JAVA使用和操作properties文件
java中的properties文件是一种配置文件,主要用于表达配置信息,文件类型为*.properties,格式为文本文件,文件的内容是格式是"键=值"的格式,在properti ...
- 第八条:覆盖equals时请遵守通用约定
==是物理相等 equals是逻辑相等 因为每个类的实例对象本质上都是唯一的 ,利用物理相等(==)是指一个实例只能相等于它自己. 利用逻辑相等是(equals)指 一个实例是否和另一个实例的某些关键 ...
- Codeforces 193 D. Two Segments
http://codeforces.com/contest/193/problem/D 题意: 给一个1~n的排列,在这个排列中选出两段区间,求使选出的元素排序后构成公差为1的等差数列的方案数. 换个 ...
- Scala 操作符与提取器
实际上Scala没有操作符, 只是以操作符的格式使用方法. 操作符的优先级取决于第一个字符(除了赋值操作符), 而结合性取决于最后一个字符 Scala的操作符命名更加灵活:) 操作符 中置操作符(In ...
- jupyter notebook下python2和python3共存(Ubuntu)
提示NOTICE 时间:2018/04/06 主题:Ubuntu 下CAFFE框架 主角:Jupyter Notebook 简介: Jupyter Notebook(此前被称为 IPython not ...
- angular4学习笔记整理(二)angular4的路由使用
这章说一下angular的路由 先说angular路由怎么引入,一开始new出来的angular项目它路由帮你配好了,但看要看app.module.ts里面 1.首先最上面要引入路由模块 import ...
- WPF 自定义DataGrid控件样式
内容转自https://www.cnblogs.com/xiaogangqq123/archive/2012/05/07/2487166.html 一.DataGrid基本样式(一) 小刚已经把Dat ...