Spark的checkpoint源码讲解
一、Checkpoint相关源码分为四个部分
1、Checkpoint的基本使用:spark_core & spark_streaming
2、初始化的源码
3、Checkpoint的job生成及执行的过程
4、读Checkpoint的过程
二、Checkpoint的基本使用
Checkpoint可以是还原药水。辅助Spark应用从故障中恢复。SparkStreaming宕机恢复,适合调度器有自动重试功能的。对于 SparkCore 则适合那些计算链条超级长或者计算耗时的
关键点进行 Checkpoint, 便于故障恢复 。
Checkpoint和persist从根本上是不一样的:
1、Cache or persist:
Cache or persist保存了RDD的血统关系,假如有部分cache的数据丢失可以根据血缘关系重新生成。
2、Checkpoint
会将RDD数据写到hdfs这种安全的文件系统里面,并且抛弃了RDD血缘关系的记录。即使persist存储到了磁盘里面,在driver停掉之后会被删除,而checkpoint可以被下次启动使用。
Checkpoint基本使用
对于spark_streaming的checkpoint:
spark streaming有一个单独的线程CheckpointWriteHandler,每generate一个batch interval的RDD数据都会触发checkpoint操作。对于kafka的DirectKafkaInputDStreamCheckpointData,实质是重写DStreamCheckpointData的update和restore方法,这样checkpoint的数据就是topic,partition,fromOffset和untilOffset。更多请参考源码例子RecoverableNetworkWordCount
对于spark_core的checkpoint:
docheckpoint:

recover:

二、Checkpoint的初始化源码
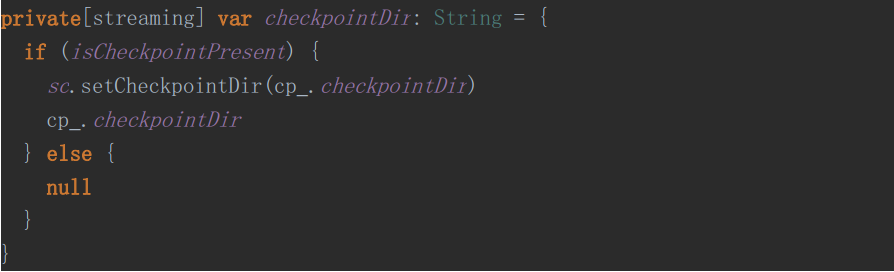
1、设置Checkpoint目录

2、调用Checkpoint方法,构建checkpointData

三、DoCheckpoint源码
在SparkContext的runjob方法中

进入之后

RDDCheckpointData中真正做Checkpoint返回一个新的RDD并清除掉依赖关系
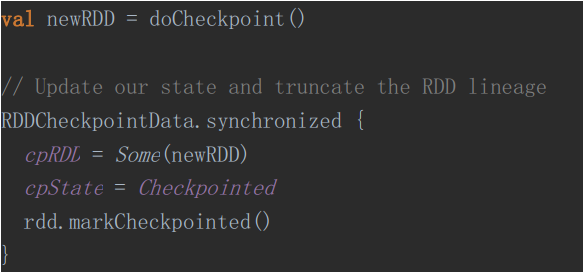
ReliableRDDCheckpointData中真正进行Checkpoint操作

在该方法中
1、获取sc

2、创建输出目录

3、以Job的方式进行Checkpoint操作
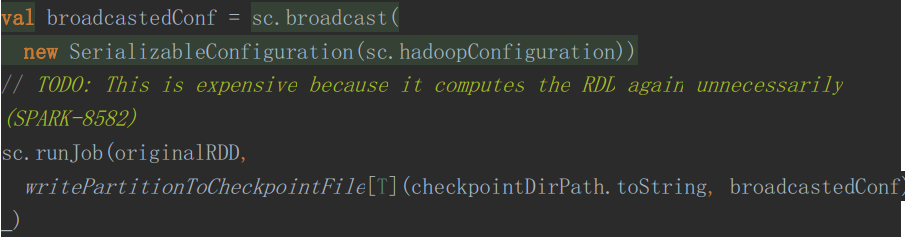
4、将分区策略写入Checkpoint目录

四、读取Checkpoint数据
三个方法:
1、同一个Spark任务,共有了Checkpoint的RDD,在该RDD的iterator方法中
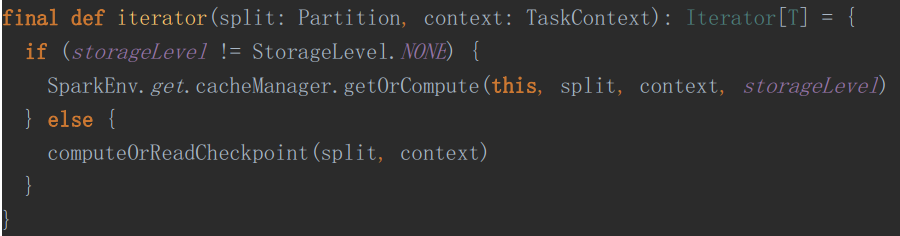
进入 computeOrReadCheckpoint
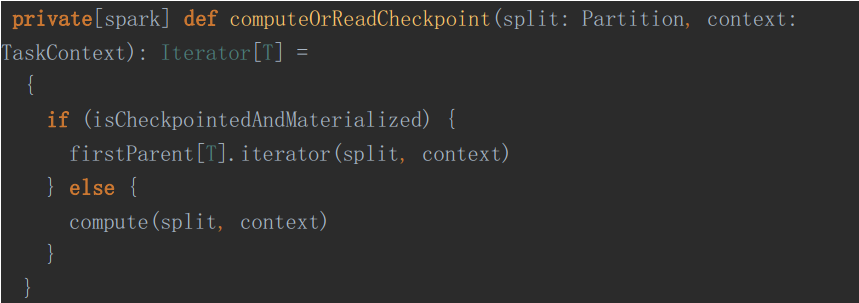
如果进行了 Checkpoint, 条件为真firstParent[T].iterator(split, context)其中, firstParent 为
/** Returns the first parent RDD */

接着是获取依赖

假如进行了Checkpoint,那么CheckpointRDD就是存在

在初始化Checkpoint的时候,我们已经初始化了CheckpointData了。
2、RDD的计算链条失败,主动去读Checkpoint文件的过程
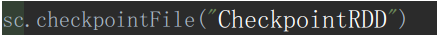
这个要求我们的入口类在下面这个包

3、SparkStreaming的故障恢复


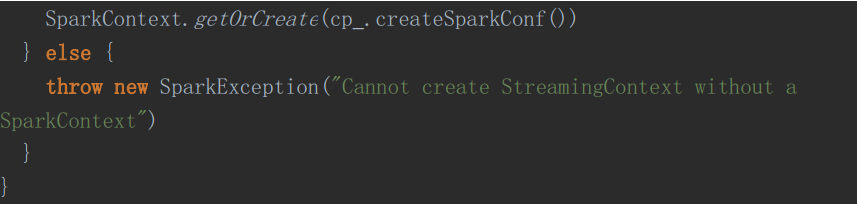
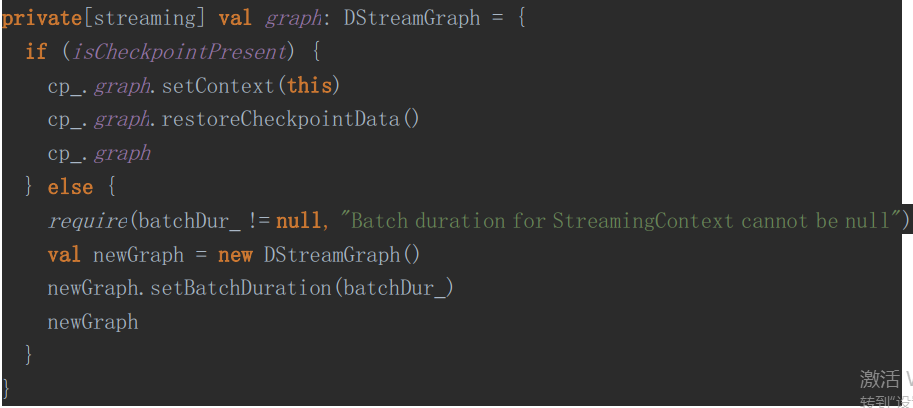
首先,看一下SteamingContext的需要
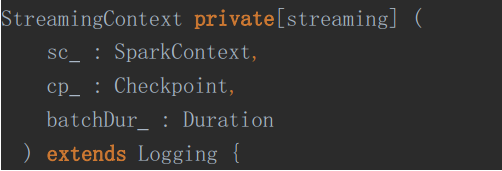
然后去读取Checkpoint

分两个步骤:
A、获取最新的Checkpoint目录
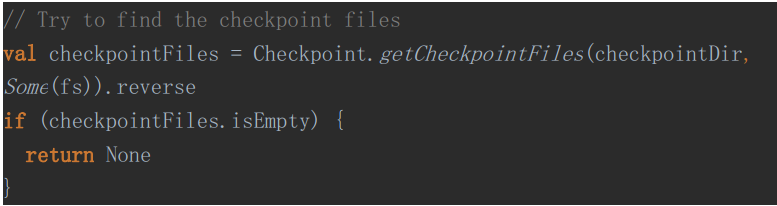
B、迭代找到最新的Checkpoint就返回
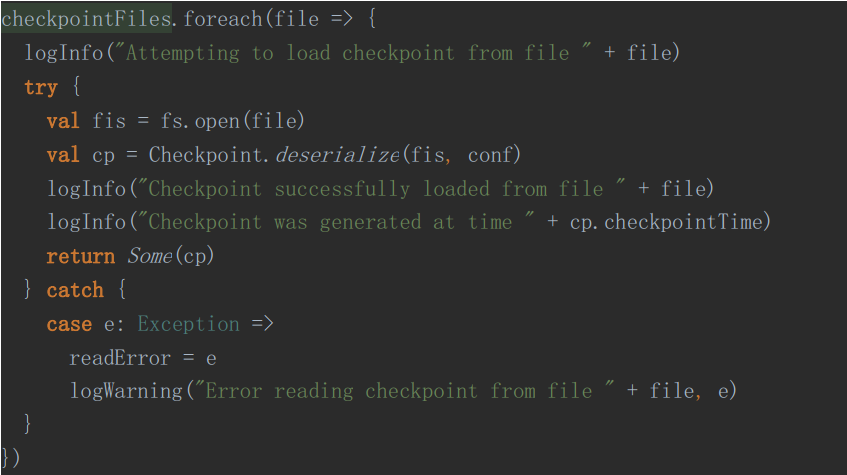
最后就是使用获取的Checkpoint去构建ssc

主要是做了一下动作



Spark的checkpoint源码讲解的更多相关文章
- Qt5.5.0使用mysql编写小软件源码讲解---顾客信息登记表
Qt5.5.0使用mysql编写小软件源码讲解---顾客信息登记表 一个个人觉得比较简单小巧的软件. 下面就如何编写如何发布打包来介绍一下吧! 先下载mysql的库文件链接:http://files. ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- 源码讲解 node+mongodb 建站攻略(一期)第二节
源码讲解 node+mongodb 建站攻略(一期)第二节 上一节,我们完成了模拟数据,这次我们来玩儿真正的数据库,mongodb. 代码http://www.imlwj.com/download/n ...
- Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend
本文是Scheduler模块源码分析的第二篇,第一篇Spark Scheduler模块源码分析之DAGScheduler主要分析了DAGScheduler.本文接下来结合Spark-1.6.0的源码继 ...
- Spark Scheduler模块源码分析之DAGScheduler
本文主要结合Spark-1.6.0的源码,对Spark中任务调度模块的执行过程进行分析.Spark Application在遇到Action操作时才会真正的提交任务并进行计算.这时Spark会根据Ac ...
- Spark RPC框架源码分析(一)简述
Spark RPC系列: Spark RPC框架源码分析(一)运行时序 Spark RPC框架源码分析(二)运行时序 Spark RPC框架源码分析(三)运行时序 一. Spark rpc框架概述 S ...
- Spark RPC框架源码分析(二)RPC运行时序
前情提要: Spark RPC框架源码分析(一)简述 一. Spark RPC概述 上一篇我们已经说明了Spark RPC框架的一个简单例子,Spark RPC相关的两个编程模型,Actor模型和Re ...
随机推荐
- 第15.33节 PyQt(Python+Qt)入门学习:containers容器类部件QTabWidget选项窗部件简介
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 容器部件就是可以在部件内放置其他部件的部件,在Qt Designer中可以使用的容器部件有 ...
- PyQt(Python+Qt)学习随笔:QScrollArea的widgetResizable属性
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 滚动区域的widgetResizable属性用于控制滚动区域的内容部署层是否应跟随滚动区域的大小变化 ...
- PHP代码审计分段讲解(12)
28题 <!DOCTYPE html> <html> <head> <title>Web 350</title> <style typ ...
- john破解kali密码
实验环境:kali 实验工具:john 所用命令: 1.查看/etc目录下的shadow文档,此文档记录了所有用户的用户名及密码hash值 2.使用命令echo 用户名:密码 > shadow, ...
- kubeadm 的工作原理
kubeadm 的工作原理 作者:张首富 时间:2020-06-04 w x:y18163201 相信使用二进制部署过 k8s 集群的同学们都知道,二进制部署集群太困难了,有点基础的人部署起来还有成功 ...
- Codeforces Edu Round 59 A-D
A. Digits Sequence Dividing 注意特殊情况,在\(n = 2\)时除非\(str[1] >= str[2]\),否则可以把第一个数划分下来,剩下的数直接当成一组,一定满 ...
- SseEmitter推送
后端代码SseController.java package com.theorydance.mywebsocket.server; import java.util.HashMap; import ...
- Nginx安装配置教程
转自https://www.cnblogs.com/zhouxinfei/p/7862285.html nginx概述 nginx是一款自由的.开源的.高性能的HTTP服务器和反向代理服务器:同时也是 ...
- 迭代 可迭代对象 迭代器的bj
1.迭代的概念 迭代是重复反馈过程的活动,其目的通常是为了逼近所需目标或结果.每一次对过程的重复称为一次"迭代",而每一次迭代得到的结果会作为下一次迭代的初始值. 2.可迭代对象 ...
- 网络 IO 模型简单介绍
一.同步阻塞 IO(BIO) 当用户线程调用了 read 系统调用,内核(kernel)就开始了 IO 的第一个阶段:准备数据.很多时候,数据在一开始还没有到达(比如,还没有收到一个完整的Socket ...