大数据开发-Spark Join原理详解
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划阶段,Spark 的 Join Selection 类会根
据 Join hints 策略、Join 表的大小、 Join 是等值 Join 还是不等值以及参与 Join 的 key 是否可以排序等条件来选择最
终的 Join 策略,最后 Spark 会利用选择好的 Join 策略执行最终的计算。当前 Spark 一共支持五种 Join 策略:
Broadcast hash join (BHJ)Shuffle hash join(SHJ)Shuffle sort merge join (SMJ)Shuffle-and-replicate nested loop join,又称笛卡尔积(Cartesian product join)Broadcast nested loop join (BNLJ)
其中 BHJ 和 SMJ 这两种 Join 策略是我们运行 Spark 作业最常见的。JoinSelection 会先根据 Join 的 Key 为等值 Join
来选择 Broadcast hash join、Shuffle hash join 以及 Shuffle sort merge join 中的一个;如果 Join 的 Key 为不等值
Join 或者没有指定 Join 条件,则会选择 Broadcast nested loop join 或 Shuffle-and-replicate nested loop join。
不同的 Join 策略在执行上效率差别很大,了解每种 Join 策略的执行过程和适用条件是很有必要的。
1、Broadcast Hash Join
Broadcast Hash Join 的实现是将小表的数据广播到 Spark 所有的 Executor 端,这个广播过程和我们自己去广播数
据没什么区别:
利用 collect 算子将小表的数据从 Executor 端拉到 Driver 端
在 Driver 端调用 sparkContext.broadcast 广播到所有 Executor 端
在 Executor 端使用广播的数据与大表进行 Join 操作(实际上是执行map操作)
这种 Join 策略避免了 Shuffle 操作。一般而言,Broadcast Hash Join 会比其他 Join 策略执行的要快。
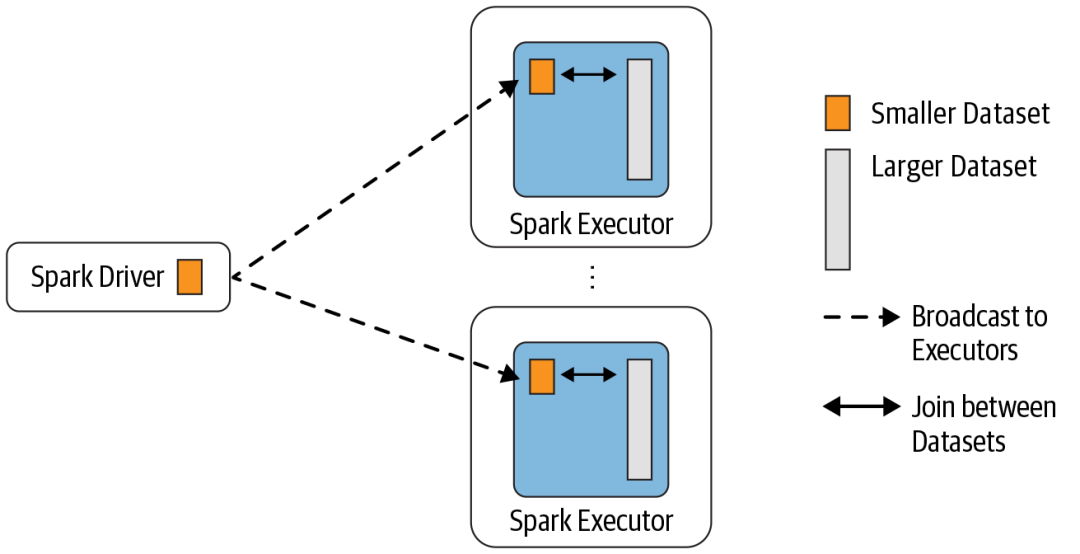
使用这种 Join 策略必须满足以下条件:
小表的数据必须很小,可以通过 spark.sql.autoBroadcastJoinThreshold 参数来配置,默认是 10MB
如果内存比较大,可以将阈值适当加大
将 spark.sql.autoBroadcastJoinThreshold 参数设置为 -1,可以关闭这种连接方式
只能用于等值 Join,不要求参与 Join 的 keys 可排序
2、Shuffle Hash Join
当表中的数据比较大,又不适合使用广播,这个时候就可以考虑使用 Shuffle Hash Join。
Shuffle Hash Join 同样是在大表和小表进行 Join 的时候选择的一种策略。它的计算思想是:把大表和小表按照相同
的分区算法和分区数进行分区(根据参与 Join 的 keys 进行分区),这样就保证了 hash 值一样的数据都分发到同一
个分区中,然后在同一个 Executor 中两张表 hash 值一样的分区就可以在本地进行 hash Join 了。在进行 Join 之
前,还会对小表的分区构建 Hash Map。Shuffle hash join 利用了分治思想,把大问题拆解成小问题去解决。
要启用 Shuffle Hash Join 必须满足以下条件:
仅支持等值 Join,不要求参与 Join 的 Keys 可排序
spark.sql.join.preferSortMergeJoin 参数必须设置为 false,参数是从 Spark 2.0.0 版本引入的,默认值为
true,也就是默认情况下选择 Sort Merge Join
小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold *
spark.sql.shuffle.partitions(默认值200)
而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小(stats.sizeInBytes),也就是
a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes
3、Shuffle Sort Merge Join
前面两种 Join 策略对表的大小都有条件的,如果参与 Join 的表都很大,这时候就得考虑用 Shuffle Sort Merge Join
了。
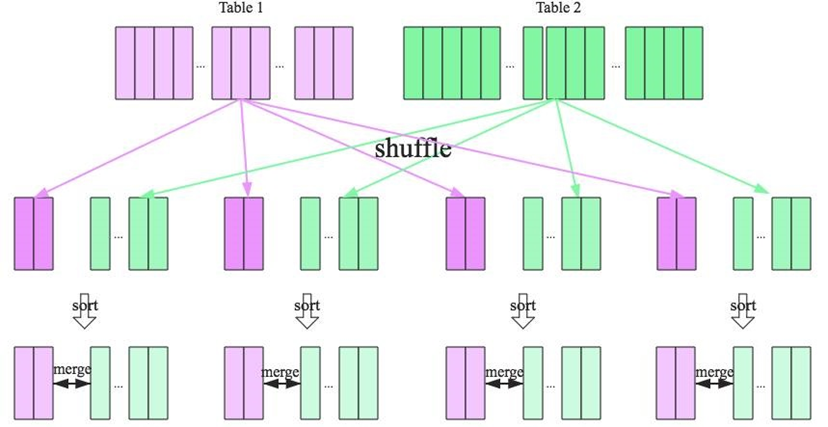
Shuffle Sort Merge Join 的实现思想:
将两张表按照 join key 进行shuffle,保证join key值相同的记录会被分在相应的分区
对每个分区内的数据进行排序
排序后再对相应的分区内的记录进行连接
无论分区有多大,Sort Merge Join都不用把一侧的数据全部加载到内存中,而是即用即丢;因为两个序列都有序。从
头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。从而大大提高了大数据量下sql join
的稳定性。
要启用 Shuffle Sort Merge Join 必须满足以下条件:
仅支持等值 Join,并且要求参与 Join 的 Keys 可排序
4、Cartesian product join
如果 Spark 中两张参与 Join 的表没指定连接条件,那么会产生 Cartesian product join,这个 Join 得到的结果其实
就是两张表行数的乘积。
5、Broadcast nested loop join
可以把 Broadcast nested loop join 的执行看做下面的计算:
for record_1 in relation_1:
for record_2 in relation_2:
join condition is executed
可以看出 Broadcast nested loop join 在某些情况会对某张表重复扫描多次,效率非常低下。从名字可以看出,这种
join 会根据相关条件对小表进行广播,以减少表的扫描次数。
Broadcast nested loop join 支持等值和不等值 Join,支持所有的 Join 类型。
吴邪,小三爷,混迹于后台,大数据,人工智能领域的小菜鸟。
更多请关注

大数据开发-Spark Join原理详解的更多相关文章
- 大数据开发-linux下常见问题详解
1.user ss is currently user by process 3234 问题原因:root --> ss --> root 栈递归一样 解决方式:exit 退出当前到ss再 ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- FusionInsight大数据开发---Spark应用开发
Spark应用开发 要求: 了解Spark基本原理 搭建Spark开发环境 开发Spark应用程序 调试运行Spark应用程序 YARN资源调度,可以和Hadoop集群无缝对接 Spark适用场景大多 ...
- 大数据入门第八天——MapReduce详解(四)本地模式运行与join实例
一.本地模式调试MR程序 1.准备 参考之前随笔的windows开发说明处:http://www.cnblogs.com/jiangbei/p/8366238.html 2.流程 最重要的是设置Loc ...
- 大数据入门第九天——MapReduce详解(六)MR其他补充
一.自定义in/outputFormat 1.需求 现有一些原始日志需要做增强解析处理,流程: 1. 从原始日志文件中读取数据 2. 根据日志中的一个URL字段到外部知识库中获取信息增强到原始日志 3 ...
- 大数据入门第九天——MapReduce详解(五)mapJoin、GroupingComparator与更多MR实例
一.数据倾斜分析——mapJoin 1.背景 接上一个day的Join算法,我们的解决join的方式是:在reduce端通过pid进行串接,这样的话: --order ,,P0001, ,,P0001 ...
- 大数据开发-从cogroup的实现来看join是宽依赖还是窄依赖
前面一篇文章提到大数据开发-Spark Join原理详解,本文从源码角度来看cogroup 的join实现 1.分析下面的代码 import org.apache.spark.rdd.RDD impo ...
- 大数据开发-Spark-拷问灵魂的5个问题
1.Spark计算依赖内存,如果目前只有10g内存,但是需要将500G的文件排序并输出,需要如何操作? ①.把磁盘上的500G数据分割为100块(chunks),每份5GB.(注意,要留一些系统空间! ...
- 详解Kafka: 大数据开发最火的核心技术
详解Kafka: 大数据开发最火的核心技术 架构师技术联盟 2019-06-10 09:23:51 本文共3268个字,预计阅读需要9分钟. 广告 大数据时代来临,如果你还不知道Kafka那你就真 ...
随机推荐
- linux自定义位置安装tomcat8.5
1 下载tomcat安装文件 下载地址:https://tomcat.apache.org/download-80.cgi 2 解压文件 tar -zxvf apache-tomcat-8.5.56 ...
- linux设备
设备初始化时同样要执行一个device_register函数,该函数传入一个struct device *类型的指针,因此要定义一个struct device类型的变量作为我们的设备. struct ...
- Vue基础之生命周期函数[残缺版]!
Vue基础之生命周期函数[残缺版]! 为什么说是残缺版呢?! 因为有一些周期函数我并没有学到!所以是残缺版! 01 beforeCreate //在实例初始化之后,数据观测 (data observe ...
- Jmeter5.1.1 把默认语言调整为中文
进入安装目录:apache-jmeter-5.1.1\bin\ 找到 jmeter.properties文件 搜索" language=en ",前面带有"#" ...
- javax.servlet.ServletException: No adapter for handler
问题描述: 我的web.xml如下: <?xml version="1.0" encoding="UTF-8"?> <web-app xmln ...
- php artisan db:seed 报错
在laravel 5中执行,要执行数据填充时报如下错误 php artisan db:seed 错误: [ReflectionException] Cla ...
- Compile-time Dependency Injection With Go Cloud's Wire 编译时依赖注入 运行时依赖注入
Compile-time Dependency Injection With Go Cloud's Wire - The Go Blog https://blog.golang.org/wire Co ...
- 外观模式(Facade) Adapter及Proxy 设计模式之间的关系 flume 云服务商多个sdk的操作 face
小结: 1. 外观模式/门面模式 Facade 往是多个类或其它程序单元,通过重新组合各类及程序单元,对外提供统一的接口/界面. Proxy(代理)注重在为Client-Subject提供一个访问的 ...
- 大数据之Hadoop技术入门汇总
今天,小编对Hadoop入门学习知识进行了汇总,帮助大家更好地入手大数据.小编关于Hadoop入门总共发写了12篇原创文章,文章是参照尚硅谷大数据视频教程来进行撰写的. 今天,小编带你解锁正确的阅读顺 ...
- LOJ10201
题目描述 原题来自:Codeforces Round #400 B. Sherlock 有了一个新女友(这太不像他了!).情人节到了,他想送给女友一些珠宝当做礼物. 他买了n 件珠宝.第i 件的价 ...