Chatbot思考录
人工分词产生不一致性的原因主要在于人们对词的颗粒度的认知问题。在汉语里,词是表达意最基本的意思,再小意思就变了。在机器翻译中会有一种颗粒度比另外一种颗粒度更好的情况,颗粒度大的翻译效果好。
为了解决词语的多义性的问题,维护一个词语对等列表是有必要的。例如“中国银联”=“银联”,这时候主键应该保存为“中国银联”,同样很多中英文系统的互译也应该将其保存在对等列表中
[补充]维护的应该是词语相关性表(应该设定关联性>p),一些词和其他词的关联性,从而拓展两种可能:1.词义相同的两个词可以以较高的关联性进行识别,从而提高答案的准确性;2.词义较为相近的两个词关联,从而提高相近答案的输出(建议的形式输出,例如我们没有发现XXX的答案,建议查看YYY的答案),提高用户对于会话智能的认可
At Infermedica we've developed a diagnostic engine that collects symptoms, asks diagnostic questions and presents likely health issues underlying this evidence. The engine uses a complex probabilistic model built on top of a knowledge base curated by medical professionals and enriched by machine learning. It is available via API and has provided helpful information to over 1M patients through a number of symptom checker apps, intelligent patient intake forms and other applications. Symptomate Bot is our attempt at building a conversational interface to the engine that will work as a symptom checker chatbot.
客服机器人最主要的还是问答引擎,收集用户的问题,并进一步收集全面和明确用户的信息(例如机器人主动提问),引擎需要采用匹配模型来讲问题和知识库进行搭配(目前考虑使用标签),回答用户的知识,并收集反馈进行下一轮会话使用
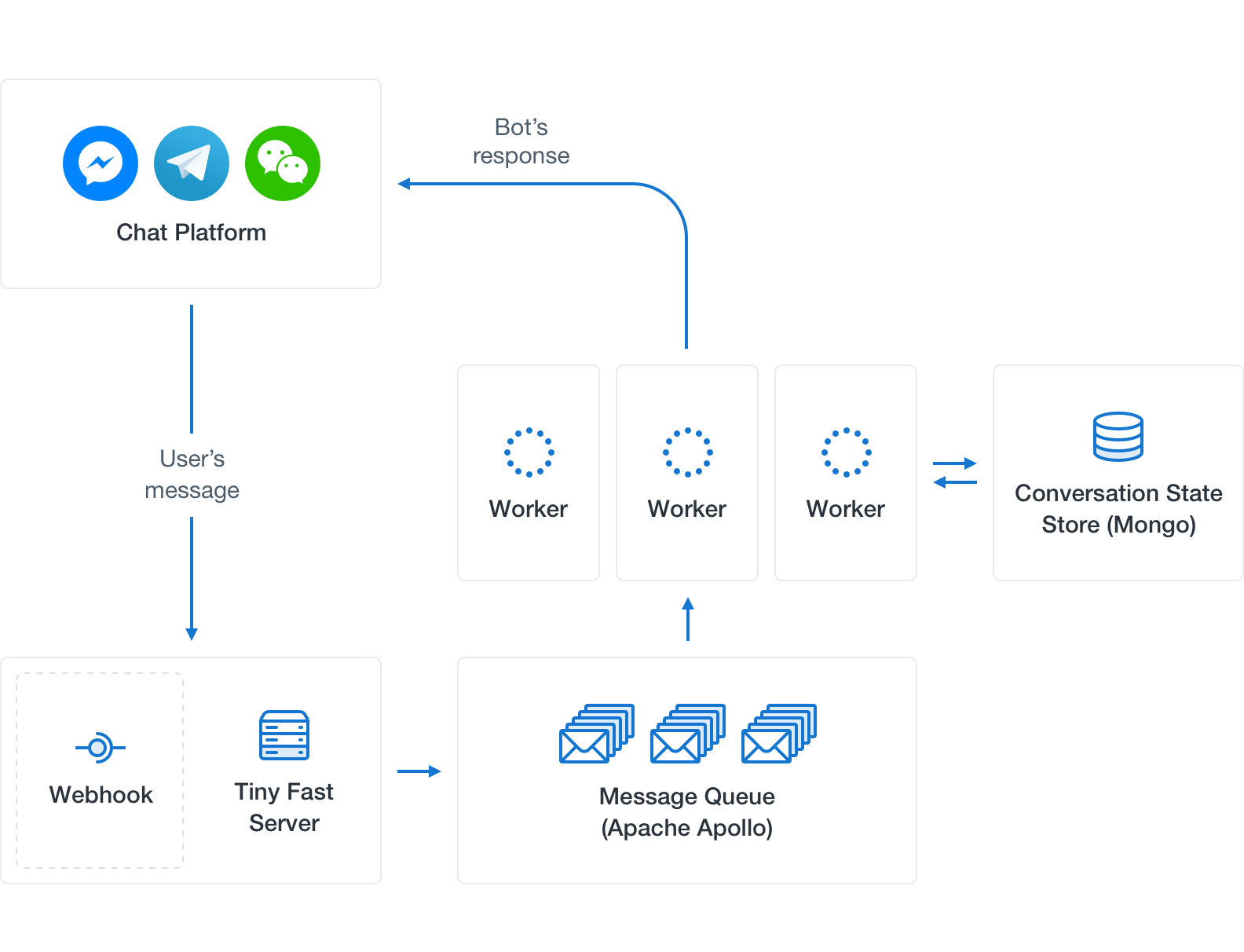
Challenge 1: Scalable architecture for handling messages
客服机器人设计的会话峰值应该考虑?是否需要排队机制?
会话机制的建立(新会话/老会话未结束),随时保存,状态转移的。
会话处理的流程:收集消息,获取与会话关联的客服模型状态,处理消息,回复用户,并将更新状态推回客服模型。
会话的保存应该适用灵活的结构和快速的读写访问,应该是NoSQL数据库,考虑MongoDB和redis。
Challenge 2: A conversational agent must converse
应该使用一些问答模板来代替“回复1”、“输入1”这样的问答,这样显得你的系统很傻。
这些简答模板包括:再次确认/纠正歧义/获取更多信息/…Challenge 3:Users will get frustrated
大部分用户会被误解,我们只为真正的顾客提供服务(基于场景的开发),就是说不正常的用户输入在我们的系统中将不会得到有效的答复。
失望的原因包括:
1.很多用户是因为存在问题或者发生故障来寻找客服服务的,本身带有消极的情绪,例如愤怒、着急、失望等。
会话机器人理解问题的规模取决于知识库的大小,如果是询问银联总裁是不会存在任何误解的可能,但是客户机器人使用的知识库往往是落后于实际的业务开展情况的,而且客户很有可能问不存在与知识库的知识。
另外,我们提供三个方法来解决“失望的用户”问题:
1.感知用户的情绪并给予安慰;
2.自动开出跟踪服务单引入人工客服的机制来解决问题;
3.定期数据统计,跟踪出现用户失望的会话,并从设计和数据方面进行改善。
消息队列的使用
即使能够写出涵盖所有自然语言现象的语法规则集合,也很难用计算机来解析。描述自然语言的文法和计算机高级程序语言的文法不同。自然语言在延边过程中,产生了词义和上下文相关的特性。
——《自然之美》p22
我们的会话机器人要基于当前会话上下文相关进行。在同一个会话中,用户提交的信息能在后续的会话中进行思考。应该有好的算法和模型来处理上下文会话理解的难题。Context Dependent Grammar.解决多义性。
只能回答“是什么”,但是没有计算机能够回答“为什么”和“怎么做”这一类的难题。
目前我们的Chatbot只需要考虑是什么就行了。
模型训练中一个重要的问题就是训练书怒,语料库的选取。 p38
如何寻找会话机器人的语料库?训练数据库越多越好,模型参数估计的越准确。
Bots简单理解,就是智能对话机器人,是基于自然语言理解的智能对话系统,它应用了智能识别技术(如语言、文字、图像),还有机器学习、知识表示、云计算、大数据等。在美剧【西部世界】中,机器人居民与人类的沟通,就是用自然语言完成。一个Bot能部署到微信、QQ、网站、微博等渠道,用户通过任何数字入口都可以唤醒,并使用它提供服务,同时,Bot与Bot之间可以通过自然语言相互进行调用,实现跨平台操作。未来,Bots可对接万物,让从虚拟到实体的应用都能与人类自然对话。所以,Bots被界定为后App时代的全新人机交互方式。苹果Siri,微软找冰,小i机器人都属于这个领域的代表。
通用的会话场景是无穷尽的
但是客服的会话场景是可以进行穷尽的,是否可以基于场景进行会话机器人设计?
问答系统六个层次:基础搜索、词联想、本体知识库,短程关系、长程关系、基于上下文的自由问答。从知识提取,知识存储,知识表达,知识检索,到人机交互、知识库,不知道多少个小零件要逐一打造。
机器善于做短程关系的查找(lookup),一层,罕见的情况下可以做两层。长程关系的发现(discovery)是机器做不好的,只能由人来写,最后变成规则机器执行。那些Siri里有趣的回答,都是人写的,和机器智能无关。
客服机器人做多少层比较好?三层?两层?客服机器人的本质是通过问答的方式提供客服服务,所以关键的动作还是问和答。
如何准确的捕捉问的操作呢?关键词(为什么?是什么?怎么?)
人工智能理论体系的系统梳理,会话机器人理论体系的系统梳理;目前会话机器人的学术研究最新进展,偏向国外,偏向博士论文,偏向技术方面(最新技术/主流技术)
- 人工智能理论体系介绍
- 会话机器人理论体系
- 最新学术研究进展:
知识库的构建 用AIML可以做吗?
自然语言处理很困难:(1)语言是不完全有规律的,规律是错综复杂的。有一定的规律,也有很多例外。因为语言是经过上万年的时间发明的,这一过程类似于建立维基百科。因此,一定会出现功能冗余、逻辑不一致等现象。但是语言依旧有一定的规律,若不遵循一定的规范,交流会比较困难;(2)语言是可以组合的。语言的重要特点是能够将词语组合起来形成句子,能够组成复杂的语言表达;(3)语言是一个开放的集合。我们可以任意地发明创造一些新的表达。比如,微信中“潜水”的表达就是一种比喻。一旦形成之后,大家都会使用,形成固定说法。语言本质的发明创造就是通过比喻扩展出来的;(4)语言需要联系到实践知识;(5)语言的使用要基于环境。在人与人之间的互动中被使用。如果在外语的语言环境里去学习外语,人们就会学习得非常快,理解得非常深。
基于这个设定,我们的会话机器人目前是否只针对无歧义的语句进行准确展出,有歧义的由客户进行选择呢?即在用户的帮助下解决语言的歧义问题
所有的自然语言处理的问题都可以分类成为五大统计自然语言处理的方法或者模型,即分类、匹配、翻译、结构预测,马尔可夫决策过程。各种各样的自然语言处理的应用,都可以模型化为这五大基本问题,基本能够涵盖自然语言处理相当一部分或者大部分的技术。主要采用统计机器学习的方法来解决。第一是分类,就是你给我一个字符串,我给你一个标签,这个字符串可以是一个文本,一句话或者其他的自然语言单元;其次是匹配,两个字符串,两句话或者两段文章去做一个匹配,判断这两个字符串的相关度是多少;第三就是翻译,即更广义的翻译或者转换,把一个字符串转换成另外一个字符串;第四是结构预测,即找到字符串里面的一定结构;第五是马可夫决策过程,在处理一些事情的时候有很多状态,基于现在的状态,来决定采取什么样的行动,然后去判断下一个状态。
分类:For 客服机器人,分类是指从答案中抽取一个或多个标签,并有效评估答案和标签的关联紧密程度
匹配:For 客服机器人,如何把用户输入的问题与知识库中的标签进行关联,并匹配标签对应的知识点 and 解决未匹配的情况
翻译:即如何将一个文本认为是标签的另外一个翻译
结构预测:寻找字符串里面的结构
马尔科夫决策:基于当前的状态太采取什么样的活动
分类主要有文本分类和情感分类,匹配主要有搜索、问题回答、对话(主要是单轮对话);翻译主要有机器翻译,语音识别,手写识别,单轮对话;结构预测主要有专门识别,词性标注,句法分析,文本的语义分析;马可夫决策过程可以用于多轮对话。
自然语言处理,在一定程度上需要考虑技术上界和性能下界的关系。现在的自然语言处理,最本质是用数据驱动的方法去模拟人,通过人工智能闭环去逼近人的语言使用能力。
在设计之前我们必须对于客服机器人有一个使用上的认识,我们的产品是原型产品,但是也可以满足用户的正常使用,后期随着技术资源的投入在准确性和响应及时性上会有更多的提升,但是基本的准确性和响应及时性也应该有一个保证,所以我们必须对准确性、响应及时性等指标有个下界的评估
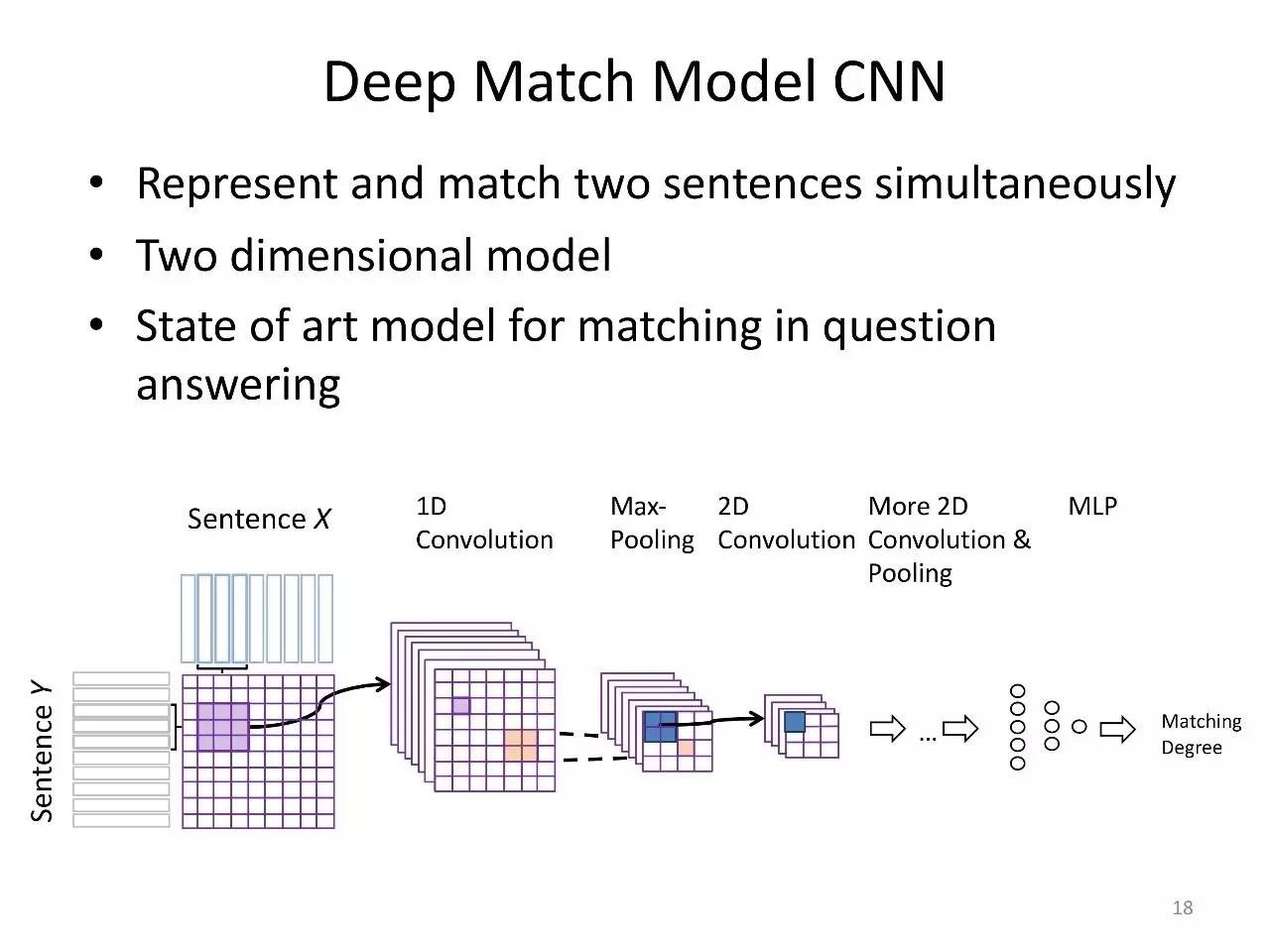
参考这个图,似乎我们可以用SVD来解决匹配问题啊
Chatbot思考录的更多相关文章
- Atitit。 沉思录 与it软件开发管理中的总结 读后感
Atitit. 沉思录 与it软件开发管理中的总结 读后感 1. <沉思录>,古罗马唯一一位哲学家皇帝马可·奥勒留所著 2 2. 沉思录与it软件开发管理中的总结 2 2.1. 要有自己的 ...
- TDD(测试驱动开发)培训录(转)
本文转载自:http://www.cnblogs.com/whitewolf/p/4205761.html 最近也在了解TDD,发现这篇文章不错,特此转载一下. TDD(测试驱动开发)培训录 2015 ...
- [原创]cocos2d-x研习录—前言
我认为很多开发者面对层出不穷的新技术.新思想和新理念,最为之苦恼的是找不到行之有效的学习方法,对于知识的本质缺乏认识,虽阅读了大量教材,却无法将其融入自己的知识体系,并搭建自己的知识树.不可否认,教材 ...
- loadrunner---<二>---菜鸟对cookie的思考
http://www.cnblogs.com/Pierre-de-Ronsard/archive/2012/11/19/2772630.html loadrunner---<二>---菜鸟 ...
- 关于图计算和graphx的一些思考[转]
原文链接:http://www.tuicool.com/articles/3MjURj “全世界的网络连接起来,英特纳雄耐尔就一定要实现.”受益于这个时代,互联网从小众的角落走到了历史的中心舞台.如果 ...
- 智能机器人chatbot论文集合
机器不学习 jqbxx.com-专注机器学习,深度学习,自然语言处理,大数据,个性化推荐,搜索算法,知识图谱 今年开始接触chatbot,跟着各种专栏学习了一段时间,也读了一些论文,在这里汇总一下.感 ...
- 《女神异闻录 5》的 UI 设计
转自:https://www.zhihu.com/question/50995871?sort=created <女神异闻录5>是近两年最为火热的JRPG游戏之一,它的出色不仅在于剧情暗讽 ...
- 来自Unix/Linux的编程启发录
本篇文章已授权微信公众号 guolin_blog (郭霖)独家公布重点内容 2017年第一篇文章,祝各位好友新年快乐. 年前因为不小心坐到了自己左手大拇指导致轻微的骨裂,没有按时更新,实在是羞愧.今年 ...
- 性能学习笔记之四--事务,思考时间,检查点,集合点和手写lr接口
一.事物,思考时间,检查点,集合点 1.事务 lr里面的事物是lr运行脚本的基础.lr里面 要测试的三个维度都以事物为单位,所以一定要有事物.事务的概念贯穿loadrunner的使用,比如我们说的响应 ...
随机推荐
- java设计模式---合成模式3
实例 下面以一个逻辑树为例子,以上面的原理图为蓝本,看看如何实现并如何使用这个树,这个结构很简单,但是如何去使用树,遍历树.为我所用还是有一定难度的. 这里主要用到树的递归遍历,如何递归.如何控制 ...
- 基于IMX515EVK+WINCE6.0---支持PB6.0通过USB下载镜像文件
基于IMX515EVK+WINCE6.0---支持PB6.0通过USB下载镜像文件 在INAND还没有写入镜像文件之前,通过ATK工具烧录xldr.nb0和eboot.nbo到INAND中,见相关链接 ...
- BAT有增有减 互联网2015校园…
又到一年开学季,也是毕业生开始被各种招聘.宣讲所围绕的时节. 在众多行业中,互联网在过往几年,也属于较热门的第一梯队之中.不过,在2015年的经济形势下,大家不由地疑问,互联网企业的招聘还会持续吗? ...
- UI设计切忌墨守成规,但改变也须用数据说话
因为我提倡一种非标准的方法,Jon Galloway在一段评论里点了我的名: 年,他们很清楚怎么去填写这些表单.如果采用其他方法,用户会感到困惑,有些人还会落荒而逃(丢掉购物车,等等).Web表单很有 ...
- pig的cogroup详解
从实例出发 %default file test.txt A = load '$file' as (date, web, name, food); B = load '$file' as (date, ...
- Android 自定义View -- 简约的折线图
转载请注明出处:http://write.blog.csdn.net/postedit/50434634 接上篇 Android 圆形百分比(进度条) 自定义view 昨天分手了,不开心,来练练自定义 ...
- 【一天一道LeetCode】#18. 4Sum
一天一道LeetCode (一)题目 Given an array S of n integers, are there elements a, b, c, and d in S such that ...
- 菜鸟玩云计算之廿一: saltstack之pillar
菜鸟玩云计算之廿一: saltstack之pillar 参考: 点击打开链接 查看pillar数据: # salt '*' pillar.items pillar的默认根目录在:/srv/pillar ...
- Java学习笔记(三)Java2D组件
一 概述 Java2D的一切都基于java.awt包中的Graphics2D类,它是Graphics的子类. 为了绘制图形,需要使用面板作为画布,例如使用JPanel作为画布,面板有一个paintC ...
- Android4.0Sd卡移植之使用vold自动挂载sd卡
在cap631平台上移植android4.0,发现内核驱动没有任何问题,能够读写,当总不能挂载. 后来发现是因为自动挂载需要vold的支持.vold程序负责检查内核的 sysfs 文件系统,发现有SD ...