【机器学习】--xgboost初始之代码实现分类
一、前述
上节我们讲解了xgboost的基本知识,本节我们通过实例进一步讲解。
二、具体
1、安装
默认可以通过pip安装,若是安装不上可以通过https://www.lfd.uci.edu/~gohlke/pythonlibs/网站下载相关安装包,将安装包拷贝到Anacoda3的安装目录的Scrripts目录下, 然后pip install 安装包安装。

2、代码实例
import xgboost
# First XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
或者每次插入一颗树,看看效果
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
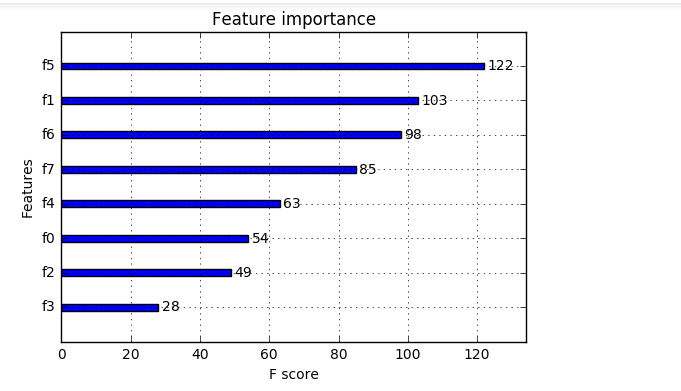
观看特征的重要程度:
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
y = dataset[:,8]
# fit model no training data
model = XGBClassifier()
model.fit(X, y)
# plot feature importance
plot_importance(model)
pyplot.show()
xgboost参数:
- 'booster':'gbtree',
- 'objective': 'multi:softmax', 多分类的问题
- 'num_class':10, 类别数,与 multisoftmax 并用
- 'gamma':损失下降多少才进行分裂
- 'max_depth':12, 构建树的深度,越大越容易过拟合
- 'lambda':2, 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
- 'subsample':0.7, 随机采样训练样本
- 'colsample_bytree':0.7, 生成树时进行的列采样
- 'min_child_weight':3, 孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束
- 'silent':0 ,设置成1则没有运行信息输出,最好是设置为0.
- 'eta': 0.007, 如同学习率
- 'seed':1000,
- 'nthread':7, cpu 线程数
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
交叉验证:
# Tune learning_rate
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# grid search
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))
【机器学习】--xgboost初始之代码实现分类的更多相关文章
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码) Python 被称为是最接近 AI 的语言.最近一位名叫Anna-Lena Popkes的小姐姐在GitHub上分享了自己如何使用P ...
- 04-04 AdaBoost算法代码(鸢尾花分类)
目录 AdaBoost算法代码(鸢尾花分类) 一.导入模块 二.导入数据 三.构造决策边界 四.训练模型 4.1 训练模型(n_e=10, l_r=0.8) 4.2 可视化 4.3 训练模型(n_es ...
- 修改xcode初始生成代码
xcode在新建新的工程的时候会默认生成一份代码,例如新建一个c++工程,其初始的代码如下: #include <iostream> int main(int argc, const ch ...
- 机器学习——XGBoost大杀器,XGBoost模型原理,XGBoost参数含义
0.随机森林的思考 随机森林的决策树是分别采样建立的,各个决策树之间是相对独立的.那么,在我们得到了第k-1棵决策树之后,能否通过现有的样本和决策树的信息, 对第m颗树的建立产生有益的影响呢?在随机森 ...
- 机器学习 xgboost 笔记
一.数据预处理.特征工程 类别变量 labelencoder就够了,使用onehotencoder反而会降低性能.其他处理方式还有均值编码(对于存在大量分类的特征,通过监督学习,生成数值变量).转换处 ...
- 机器学习——XGBoost
基础概念 XGBoost(eXtreme Gradient Boosting)是GradientBoosting算法的一个优化的版本,针对传统GBDT算法做了很多细节改进,包括损失函数.正则化.切分点 ...
- 用Python开始机器学习(7:逻辑回归分类) --好!!
from : http://blog.csdn.net/lsldd/article/details/41551797 在本系列文章中提到过用Python开始机器学习(3:数据拟合与广义线性回归)中提到 ...
- 【机器学习实验】学习Python来分类现实世界的数据
引入 一个机器能够依据照片来辨别鲜花的品种吗?在机器学习角度,这事实上是一个分类问题.即机器依据不同品种鲜花的数据进行学习.使其能够对未标记的測试图片数据进行分类. 这一小节.我们还是从scikit- ...
- 机器学习--Xgboost调参
Xgboost参数 'booster':'gbtree', 'objective': 'multi:softmax', 多分类的问题 'num_class':10, 类别数,与 multisoftma ...
随机推荐
- Redis数据库及其基本操作
Redis 是一个高性能的key-value数据库, 支持主从同步, 完全实现了发布/订阅机制, 因此可以用于聊天室等场景. 主要表现于多个浏览器之间的信息同步和实时更新. 和Memcached类似, ...
- 问题(一) DebugAugmenter
问题: DebugAugmenter的作用是什么?是任何一个自创建的变量都可以取代它还是它有特定含义? public class DebugAugmenter Test { @Test public ...
- Windows 使用 Visual Studio 编译 caffe
说明:最近看 caffe 发现在 github 上下载的源码没有windows版本的,需要自己生成项目文件才能用 Visual Studio 编译,这里记录一下生成Windows项目文件的方法以及编译 ...
- 【双连通分量】Bzoj2730 HNOI2012 矿场搭建
Description 煤矿工地可以看成是由隧道连接挖煤点组成的无向图.为安全起见,希望在工地发生事故时所有挖煤点的工人都能有一条出路逃到救援出口处.于是矿主决定在某些挖煤点设立救援出口,使得无论哪一 ...
- java 理解如何实现图片验证码 傻瓜都能看懂。
先代码后解释: 只要把代码复制到你的项目中就可以了. 代码: 验证码工具类: package cn.happy.util.imagesVerTion; /** * Author: SamGroves ...
- 微服务架构 - 巧妙获取被墙的Docker镜像
在国内由于种种原因,有些Docker镜像直接是获取不到的,特别是k8s中的一些镜像.本人在部署k8s中的helm组件时需要获取tiller镜像,如果直接用如下命令: docker pull gcr.i ...
- 利用ATiny85制作BadUSB
0x00.准备: ATiny85的板子 淘宝十元包邮.有两款,两款都可以,建议选择左边的,这样可以直接插入USB口,第二款也可以,不过需要一根Micro的数据线(旧款安卓手机使用的线). 电脑安装驱动 ...
- .NETCore 快速开发做一个简易商城
介绍 上一篇介绍 <.NETCore 基于 dbfirst 体验快速开发项目>,讲得不太清楚有些多人没看懂.这次吸取教训,将一个简易商城做为案例,现实快速开发. 本案例用于演示或学习,不具 ...
- java基础(七)-----深入剖析Java中的装箱和拆箱
本文主要介绍Java中的自动拆箱与自动装箱的有关知识. 基本数据类型 基本类型,或者叫做内置类型,是Java中不同于类(Class)的特殊类型.它们是我们编程中使用最频繁的类型. Java是一种强类型 ...
- 委托与lambda关系
什么是委托委托是没有方法体的,声明委托就是一个关键字: delegate ,委托可以试有参无参,有返回值无返回值.和我们的方法是一样的.不同的区别是 委托没有方法体的,委托可放在类下也可以放在类的外面 ...