【机器学习】--xgboost初始之代码实现分类
一、前述
上节我们讲解了xgboost的基本知识,本节我们通过实例进一步讲解。
二、具体
1、安装
默认可以通过pip安装,若是安装不上可以通过https://www.lfd.uci.edu/~gohlke/pythonlibs/网站下载相关安装包,将安装包拷贝到Anacoda3的安装目录的Scrripts目录下, 然后pip install 安装包安装。

2、代码实例
import xgboost
# First XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
或者每次插入一颗树,看看效果
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
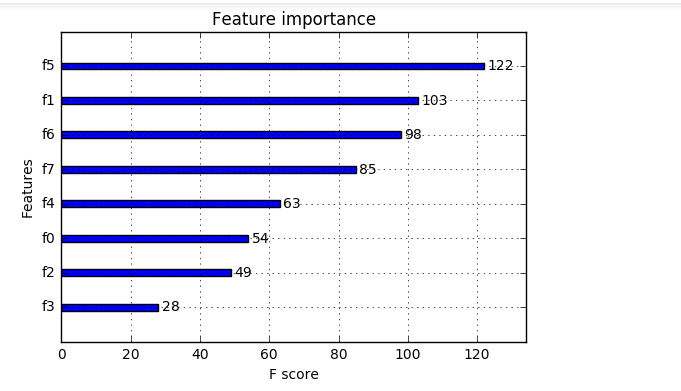
观看特征的重要程度:
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
y = dataset[:,8]
# fit model no training data
model = XGBClassifier()
model.fit(X, y)
# plot feature importance
plot_importance(model)
pyplot.show()
xgboost参数:
- 'booster':'gbtree',
- 'objective': 'multi:softmax', 多分类的问题
- 'num_class':10, 类别数,与 multisoftmax 并用
- 'gamma':损失下降多少才进行分裂
- 'max_depth':12, 构建树的深度,越大越容易过拟合
- 'lambda':2, 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
- 'subsample':0.7, 随机采样训练样本
- 'colsample_bytree':0.7, 生成树时进行的列采样
- 'min_child_weight':3, 孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束
- 'silent':0 ,设置成1则没有运行信息输出,最好是设置为0.
- 'eta': 0.007, 如同学习率
- 'seed':1000,
- 'nthread':7, cpu 线程数
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
交叉验证:
# Tune learning_rate
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# grid search
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))
【机器学习】--xgboost初始之代码实现分类的更多相关文章
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码) Python 被称为是最接近 AI 的语言.最近一位名叫Anna-Lena Popkes的小姐姐在GitHub上分享了自己如何使用P ...
- 04-04 AdaBoost算法代码(鸢尾花分类)
目录 AdaBoost算法代码(鸢尾花分类) 一.导入模块 二.导入数据 三.构造决策边界 四.训练模型 4.1 训练模型(n_e=10, l_r=0.8) 4.2 可视化 4.3 训练模型(n_es ...
- 修改xcode初始生成代码
xcode在新建新的工程的时候会默认生成一份代码,例如新建一个c++工程,其初始的代码如下: #include <iostream> int main(int argc, const ch ...
- 机器学习——XGBoost大杀器,XGBoost模型原理,XGBoost参数含义
0.随机森林的思考 随机森林的决策树是分别采样建立的,各个决策树之间是相对独立的.那么,在我们得到了第k-1棵决策树之后,能否通过现有的样本和决策树的信息, 对第m颗树的建立产生有益的影响呢?在随机森 ...
- 机器学习 xgboost 笔记
一.数据预处理.特征工程 类别变量 labelencoder就够了,使用onehotencoder反而会降低性能.其他处理方式还有均值编码(对于存在大量分类的特征,通过监督学习,生成数值变量).转换处 ...
- 机器学习——XGBoost
基础概念 XGBoost(eXtreme Gradient Boosting)是GradientBoosting算法的一个优化的版本,针对传统GBDT算法做了很多细节改进,包括损失函数.正则化.切分点 ...
- 用Python开始机器学习(7:逻辑回归分类) --好!!
from : http://blog.csdn.net/lsldd/article/details/41551797 在本系列文章中提到过用Python开始机器学习(3:数据拟合与广义线性回归)中提到 ...
- 【机器学习实验】学习Python来分类现实世界的数据
引入 一个机器能够依据照片来辨别鲜花的品种吗?在机器学习角度,这事实上是一个分类问题.即机器依据不同品种鲜花的数据进行学习.使其能够对未标记的測试图片数据进行分类. 这一小节.我们还是从scikit- ...
- 机器学习--Xgboost调参
Xgboost参数 'booster':'gbtree', 'objective': 'multi:softmax', 多分类的问题 'num_class':10, 类别数,与 multisoftma ...
随机推荐
- 最短寻道优先算法----SSTF算法
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. 该算法选择这样的进程,其要求访问的磁道与当前磁头所在的磁道距离最近,以使每次的寻道时间最短 java代码实现如下: import java.ut ...
- 带BOM头文件解析
在java中apache提供了一个工具类BOMStream,在获取文件流时,将获取到的文件流转化成为BOM流: InputStreamReader is = new InputStreamReader ...
- 深入理解SpringCloud之分布式配置
Spring Cloud Config Server能够统一管理配置,我们绝大多数情况都是基于git或者svn作为其配置仓库,其实SpringCloud还可以把数据库作为配置仓库,今天我们就来了解一下 ...
- TestNG entryset的用法及遍历map的用法
以下内容引自 http://blog.csdn.net/bestone0213/article/details/47904107 (注: 该 url不是原出处.其博主注明转载,但未注明转自何处) k ...
- golang 中 string 转换 []byte 的一道笔试题
背景 去面试的时候遇到一道和 string 相关的题目,记录一下用到的知识点.题目如下: s:="123" ps:=&s b:=[]byte(s) pb:=&b s ...
- Github泄露扫描系统
Github leaked patrol Github leaked patrol为一款github泄露巡航工具: 提供了WEB管理端,后台数据库支持SQLITE3.MYSQL和POSTGRES 双引 ...
- js获取数组中最大值和最小值
var max = Math.max.apply(null, 数组); 获取最大值 var min = Math.min.apply(null, 数组);获取最小值 一句话获取数组中最大的数,最小数
- c#Socket服务器与客户端的开发(2)
上一篇文章我们使用原生的socket分别实现了服务器和客户端, 本篇文章使用SuperSocket来开发实现服务器, 之前也介绍了SuperSocket是一个轻量级, 跨平台而且可扩展的 .Net/M ...
- Promise, Generator, async/await的渐进理解
作为前端开发者的伙伴们,肯定对Promise,Generator,async/await非常熟悉不过了.Promise绝对是烂记于心,而async/await却让使大伙们感觉到爽(原来异步可以这么简单 ...
- Java8新特性之五:Optional
NullPointerException相信每个JAVA程序员都不陌生,是JAVA应用程序中最常见的异常.之前,Google Guava项目曾提出用Optional类来包装对象从而解决NullPoin ...