几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步
题记
关系型数据库Mysql/Oracle增量同步Elasticsearch是持续关注的问题,也是社区、QQ群等讨论最多的问题之一。
问题包含但不限于:
1、Mysql如何同步到Elasticsearch?
2、Logstash、kafka_connector、canal选型有什么不同,如何取舍?
3、能实现同步增删改查吗? .....
本文给出答案。
1、Canal同步
1.1 canal官方已支持Mysql同步ES6.X
同步原理,参见之前: 干货 | Debezium实现Mysql到Elasticsearch高效实时同步。
canal 1.1.1版本之后, 增加客户端数据落地的适配及启动功能。canal adapter 的 Elastic Search 版本支持6.x.x以上。
需要借助adapter实现。
1.2 同步效果
1)已验证:仅支持增量同步,不支持全量已有数据同步。这点,canal的初衷订位就是“阿里巴巴mysql数据库binlog的增量订阅&消费组件”。
2)已验证:由于采用了binlog机制,Mysql中的新增、更新、删除操作,对应的Elasticsearch都能实时新增、更新、删除。
3)推荐使用场景
canal适用于对于Mysql和Elasticsearch数据实时增、删、改要求高的业务场景。
实时场景要求不高的业务场景,logstashinputjdbc也能满足。
建议,做好选型甄别。
2、同步版本:
ES:6.6.1
Mysql: 5.7.25
canal:v1.1.3-alpha-2
canal-adapter:v1.1.3-alpha-2
canal下载地址:https://github.com/alibaba/canal/releases
3、同步步骤解读
3.1 启动canal,可作为常驻进程后台运行。
官网已有详细描述https://github.com/alibaba/canal/wiki/QuickStart,
以下仅列举关键注意事项。
对应下载文件:canal.deployer-1.1.3-SNAPSHOT.tar.gz, 可以实时关注最新版本。
3.1.1 启用binlog
canal的原理是基于mysql binlog技术,所以这里一定需要开启mysql的binlog写入功能,建议配置binlog模式为row.
[mysqld]
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
3.1.2 修改配置文件
vi conf/example/instance.properties
配置数据库基本信息。
3.1.3 启动canal
bin/startup.sh可通过日志排查错误。
3.2 配置ElasticSearch适配器,并实现同步。
官网已有详细描述:https://github.com/alibaba/canal/wiki/Sync-ES。
以下仅针对部署遇到的坑做描述。
3.2.1 部署版本
anal.adapter-1.1.3-SNAPSHOT.tar.gz,如有更新,建议使用最新版本。
3.2.2 核心配置
[root@localhost es]# cat mytest_user.yml
dataSourceKey: defaultDS
destination: example
esMapping:
_index: baidu_index
_type: _doc
_id: _id
pk: id
sql: "select a.id as _id, a.title, a.url, a.publish_time, a.content,
from baidu_info as a"
# objFields:
# _labels: array:;
etlCondition: "where a.id >= 1"
commitBatch: 3000
实现目的:库表id字段作为Elasticsearch的_id,以期实现自增。
4、多表关联实现
建议参考官网:https://github.com/alibaba/canal/wiki/Sync-ES
支持:
一对一
一对多
多对多
5、坑
坑1:canal.adapter-1.1.2 启动失败
启动失败:https://github.com/alibaba/canal/issues/1513
该问题在1.1.3版本已经修复。
坑2:不支持全量同步
全量同步建议使用logstash或者其他工具:
坑3:必须先在ES创建好对应索引的Mapping
否则,会没有识别索引,会报写入错误。
坑4:多张表的同步如何实现?
在canal.adapter-1.1.3/conf/es的新增*.yml配置即可。
也就是说,可以一张Mysql表一个配置文件。
坑5:空指针异常错误
解决方案:sql语句部分,指定对应库表id为ES中的_id,否则会报错。
举例:
select sx_sid as _id, name from baidu_info
坑6:基于 row 模式的 binlog 会不会记录变更前、变更后的值呢?
INSERT:只有变更后的值。
UPDATE:包含了变更前、变更后的值。
DELETE:变更前的值
关于全量同步:https://github.com/alibaba/canal/issues/376
6 同步选型小结
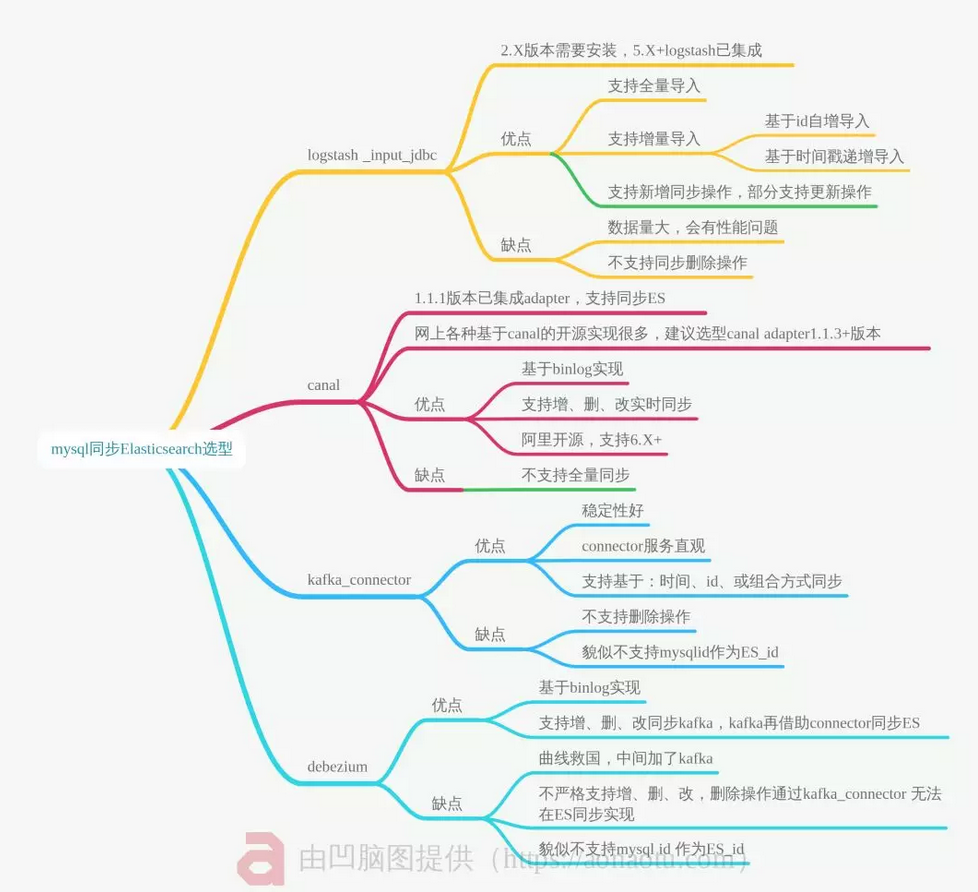
以上不同选型各有利弊,建议 结合实际业务斟酌选择。

几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步的更多相关文章
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第一篇:Debezium实现Mysql到Elasticsearch高效实时同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484358&idx=1&sn=3a78347 ...
- canal 实现Mysql到Elasticsearch实时增量同步
简介: MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据 ...
- orcale增量全量实时同步mysql可支持多库使用Kettle实现数据实时增量同步
1. 时间戳增量回滚同步 假定在源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序.通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后 ...
- WINDOWS下更改MYSQL数据路径(datadir)后服务启动1067解决不能改变mysql数据库存储位置
晚上安装完MYSQL(系统:深度WINXPSP2, MYSQL版本:5.1.32)后,用MYSQL自带的配置工具配置完发现默认的数据存放路径是:C:/Documents and Settings/Al ...
- [转]分析MySQL数据类型的长度【mysql数据字段 中length和decimals的作用!熟悉mysql必看】
转载自:http://blog.csdn.net/daydreamingboy/article/details/6310907 分析MySQL数据类型的长度 MySQL有几种数据类型可以限制类型的&q ...
- rsync无密码实时增量同步
rsync -azvP /rsync/ --password-file=/etc/rsyncd/rsyncd.password ruiy@192.168.11.199:/rsync/ rsync - ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
随机推荐
- day01 Java_JVM,JCR,JDK
精华笔记: java开发环境: 编译运行过程: 编译期:.java源文件,经过编译,生成.class字节码文件 运行期:JVM加载.class并运行.class(0和1) 特点:跨平台.一次编程到处使 ...
- IDEA中web项目打成war包并在本地tomcat部署(超细版)
准备工作:相关软件及插件IDEA(2021.1.3).tomcat(8.5.50)且在IDEA中调用tomcat运行时没有任何错误的,如何下载安装百度都有详细的介绍,这里就不过多的介绍了,版本不同操作 ...
- AtCoder Beginner Contest 253 F - Operations on a Matrix // 树状数组
题目传送门:F - Operations on a Matrix (atcoder.jp) 题意: 给一个N*M大小的零矩阵,以及Q次操作.操作1(l,r,x):对于 [l,r] 区间内的每列都加上x ...
- Deployment之滚动更新策略。
1.Deployment控制器详细信息中包含了其更新策略的相关配置.kubectl describe命令中输出的StrategyType.RollingUpdateStrategy字段等: root@ ...
- 什么是双网口以太网IO模块
MXXXE系列远程IO模块工业级设计,适用于工业物联网和自动化控制系统,MxxxE工业以太网远程 I/O 配备 2 个mac层数据交换芯片的以太网端口,允许数据通过可扩展的菊花链以太网远程 I/O 阵 ...
- Win10环境下使用Flask配合Celery异步推送实时/定时消息(Socket.io)/2020年最新攻略
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_163 首先得明确一点,和Django一样,在2020年Flask 1.1.1以后的版本都不需要所谓的三方库支持,即Flask-Ce ...
- .NET静态代码织入——肉夹馍(Rougamo) 发布1.1.0
肉夹馍(https://github.com/inversionhourglass/Rougamo)通过静态代码织入方式实现AOP的组件,其主要特点是在编译时完成AOP代码织入,相比动态代理可以减少应 ...
- 从零开始Blazor Server(7)--使用Furion权限验证
序 上面两篇我们讲了怎么用OnNavigateAsync来验证权限,又写了怎么用策略来验证权限. 其实我们既然集成了Fution,就可以用Furion带的方式来验证. 创建AdminHandler 我 ...
- Windows Embedded CE 6.0开发环境的搭建(2)
最近开始在学习嵌入式,在这里首先得安装Windows Embedded CE 6.0,其中遇到了很多问题,电脑的系统以及相关配置都会在安装过程中受到影响,因此笔者就安装中的问题以及环境搭建来介绍一下. ...
- @Autowired注解 --required a single bean, but 2 were found出现的原因以及解决方法
@Autowired注解是spring用来支持依赖注入的核心利器之一,但是我们或多或少都会遇到required a single bean, but 2 were found(2可能是其他数字)的问题 ...