实验 3 Spark 和 Hadoop 的安装
1. 安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装Spark(Local 模式)。
2. HDFS 常用操作
使用 hadoop 用户名登录进入 Linux 系统,启动 Hadoop,参照相关 Hadoop 书籍或网络资料,或者也可以参考本教程官网的“实验指南”栏目的“HDFS 操作常用 Shell 命令”,
使用Hadoop 提供的 Shell 命令完成如下操作:
(1) 启动Hadoop,在HDFS 中创建用户目录“/user/hadoop”;
hadoop fs -mkdir /user/hadoop
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件 test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop”目录下;
hdfs dfs -put /home/hadoop/test.txt /usr/hadoop
(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文件系统中的“/home/hadoop/下载”目录下;
hdfs dfs -get /user/hadoop/test.txt /home/hadoop
(4) 将HDFS 中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
hdfs dfs -cat /user/hadoop/test.txt
(5) 在 HDFS 中的“/user/hadoop” 目录下, 创建子目录 input ,把 HDFS 中 “/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;
hadoop fs -mkdir /user/hadoop/input
hdfs dfs -cp /user/hadoop/test.txt /user/hadoop/input
(6) 删除HDFS 中“/user/hadoop”目录下的test.txt文件,删除HDFS 中“/user/hadoop”目录下的 input 子目录及其子目录下的所有内容。
hdfs dfs -rm /user/hadoop/test.txt
hdfs dfs -rm -r /user/hadoop/input
3. Spark 读取文件系统的数据
(1) 在 spark-shell 中读取Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
bin/spark-shell
val textFile = sc.textFile("file:///home/hadoop/test1.txt")
textFile.count()

(2) 在 spark-shell 中读取HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
val textFile = sc.textFile("hdfs://node01:8020/user/hadoop/test.txt")
textFile.count()

(3) 编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,并将生成的JAR 包通过 spark-submit 提交到 Spark 中运行命令。
cd ~ # 进入用户主文件夹 mkdir ./sparkapp3 # 创建应用程序根目录 mkdir -p ./sparkapp3/src/main/scala # 创建所需的文件夹结构 vim ./sparkapp3/src/main/scala/SimpleApp.scala
---------------------------------------------------------- /* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf object SimpleApp {
def main(args: Array[String]) {
val logFile = "hdfs://localhost:9000/home/hadoop/test.csv"
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2)
val num = logData.count()
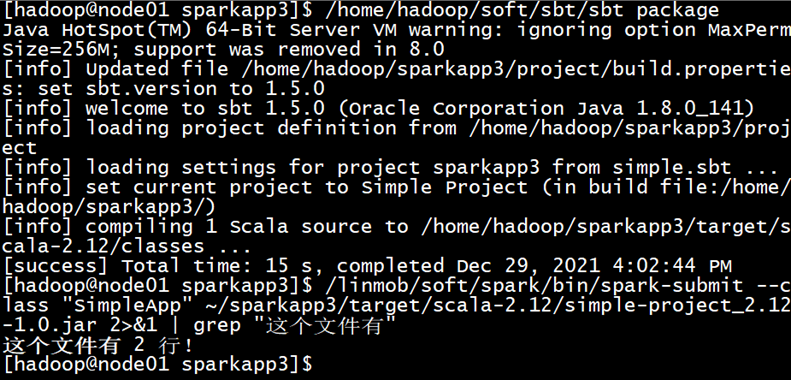
println("这个文件有 %d 行!".format(num))
}
} ----------------------------------------------------------
vim ./sparkapp3/simple.sbt
---------------------------------------------------------- name := "Simple Project"
version := "1.0"
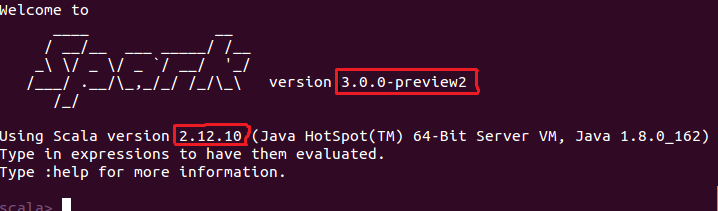
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.0.0-preview2" ----------------------------------------------------------
注意:文件 simple.sbt 需要指明 Spark 和 Scala 的版本,如下图所示:
cd ~/sparkapp3 /usr/local/sbt/sbt package #这里是需要安装一个sbt,教程在下一篇linux安装sbt - 我试试这个昵称好使不 - 博客园 (cnblogs.com)
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp3/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1 | grep "这个文件有"
实验 3 Spark 和 Hadoop 的安装的更多相关文章
- spark实验(三)--Spark和Hadoop的安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- spark实验(一)--spark安装(1)
一.实验目的 (1)掌握 Linux 虚拟机的安装方法.Spark 和 Hadoop 等大数据软件在 Linux 操作系统 上运行可以发挥最佳性能,因此,本教程中,Spark 都是在 Linux 系统 ...
- Spark Hadoop Free 安装遇到的问题
运行 ./sbin/start-master.sh : SparkCommand:/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java -cp /home/se ...
- spark的standlone模式安装和application 提交
spark的standlone模式安装 安装一个standlone模式的spark集群,这里是最基本的安装,并测试一下如何进行任务提交. require:提前安装好jdk 1.7.0_80 :scal ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark大数据平台安装教程
一.Spark介绍 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎.Spark是开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapRe ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客 Spark运行模式概述 Spark standalone简介与运行wordcount(master.slave1和slave2) 开篇要明白 (1)spark-env.sh 是环境变量配 ...
- 网站用户行为分析——Hadoop的安装与配置(单机和伪分布式)
Hadoop安装方式 Hadoop的安装方式有三种,分别是单机模式,伪分布式模式,伪分布式模式,分布式模式. 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行.非分布 ...
随机推荐
- 矩池云 | 利用LSTM框架实时预测比特币价格
温馨提示:本案例只作为学习研究用途,不构成投资建议. 比特币的价格数据是基于时间序列的,因此比特币的价格预测大多采用LSTM模型来实现. 长期短期记忆(LSTM)是一种特别适用于时间序列数据(或具有时 ...
- java 注释与标识符
JAVA基础 注释与标识符 注释 书写注释是一个非常好的习惯 三种注释: 单行,多行,文档 .单行 ://注释 .多行:/* 注释 / .文档** 注释 */ 标识符 1. 关键字 2.标识符注意点 ...
- 【python】kNN基础算法--推荐系统(辅助研究)
# -*- coding:utf-8 -*- # import numpy as np #import numpy 和from numpy import *是不一样的 # # # import num ...
- Redis常用命令代码实例集合
//连接本地的 Redis 服务 $redis = new Redis(); $redis->connect('127.0.0.1', 6379); $redis->auth('12345 ...
- tp5 缩略图自写
1:php终端 安装扩展 使用Composer安装ThinkPHP5的图像处理类库: composer require topthink/think-image2:控制器代码: public func ...
- NETPLIER : 一款基于概率的网络协议逆向工具(一)理论
本文系原创,转载请说明出处:信安科研人 关注微信公众号 信安科研人 获取更多网络安全学术技术资讯 今日介绍一篇发表在2021 NDSS会议上的一项有关协议逆向的工作: @ 目录 1 网络协议逆向工程简 ...
- 写给开发人员的实用密码学(七)—— 非对称密钥加密算法 RSA/ECC
本文部分内容翻译自 Practical-Cryptography-for-Developers-Book,笔者补充了密码学历史以及 openssl 命令示例,并重写了 RSA/ECC 算法原理.代码示 ...
- Docker 学习之命令篇
Docker 学习之命令篇 1. docker images //镜像列表 2. docker ps –a //所有运行过的容器 3. docker ps –l 最后运行的容器 4. docker ...
- Docker——镜像讲解
镜像是什么 镜像是一种轻量级,可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码.运行时.库.环境变量和配置文件. 所有的应用,直接打包doc ...
- web自动化之定位
UI自动化必不可少的操作--元素定位 8大基础定位 driver.find_element_by_id() # id定位 driver.find_element_by_name() # name定位 ...