ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1、 中文分词器
1.1 默认分词器
先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好。
GET /_analyze
{
"analyzer": "standard",
"text": "中华人民共和国"
}我们想要的效果是什么:“中华人民共和国”作为一整个词语。
得到的结果是:
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "华",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "人",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "民",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "共",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "和",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
得到的结果不如人意,IK分词器就是目前最流行的es中文分词器
1.2 安装ik分词器
安装我就不详细说了,教程很多。
1.3 ik分词器基础知识
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民大会堂,人民大会,大会堂”,会穷尽各种可能的组合;
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国人民大会堂"
}
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国人",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "人民大会堂",
"start_offset" : 7,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "人民大会",
"start_offset" : 7,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 10
},
{
"token" : "人民",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 11
},
{
"token" : "大会堂",
"start_offset" : 9,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 12
},
{
"token" : "大会",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 13
},
{
"token" : "会堂",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 14
}
]
}
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国,人民大会堂”。
GET /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国人民大会堂"
}{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "人民大会堂",
"start_offset" : 7,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 1
}
]
}
1.4 ik分词器的使用
存储时,使用ik_max_word,搜索时,使用ik_smart,原因也很容易想到:存储时,尽量存储多的可能性,搜索时做粗粒度的拆分
例如,创建以下映射
PUT /my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}2、ik配置文件
ik配置文件地址:插件的config目录下
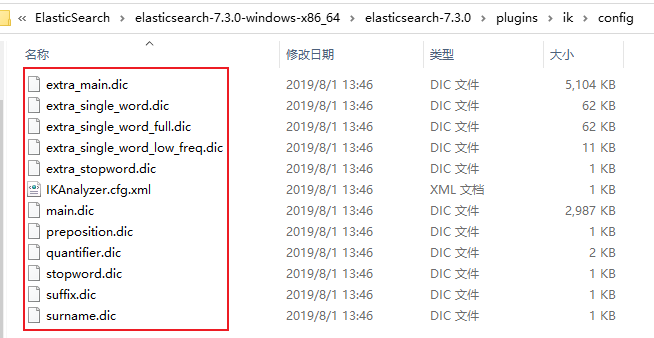
部分文件内容如下:
- IKAnalyzer.cfg.xml:用来配置自定义词库
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起,都会按照这个里面的词语去分词,ik原生最重要的两个配置文件之一
- preposition.dic: 介词
- quantifier.dic:放了一些单位相关的词,量词
- suffix.dic:放了一些后缀
- surname.dic:中国的姓氏
- stopword.dic:包含了英文的停用词,a the and at but等。会在分词的时候,直接被干掉,不会建立在倒排索引中。ik原生最重要的两个配置文件之一
3、自定义词库
3.1 自定义分词词库
每年都会涌现一些特殊的流行词,内卷,耗子尾汁,不讲武德等,这些词一般不会出现在ik的原生词典里,分词的时候也不会把这些词汇当作整个词汇来进行分词。所以需要我们自己补充自己的最新的词语,到ik的词库里面。
就拿耗子尾汁来说,不做自定义分词的效果如下。

在实际的搜索过程中,肯定不希望把它分词,而是希望把它作为一个整体的词汇。
(1)首先在IK插件的config目录下,有一个IKAnalyzer.cfg.xml文件。
(2)使用Notepad++打开该文件
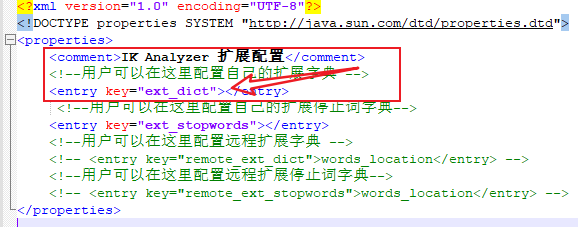
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
(3)可以看到上面的提示
(4)于是我们创建一个名为mydict.dic的文件,内容如下
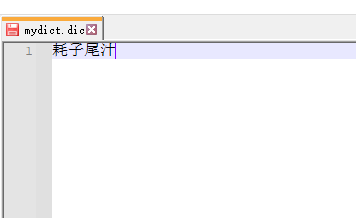
(5)注意如果多个词语,就着下一行接着录入,然后把这个文件放在与配置文件的相同目录下。
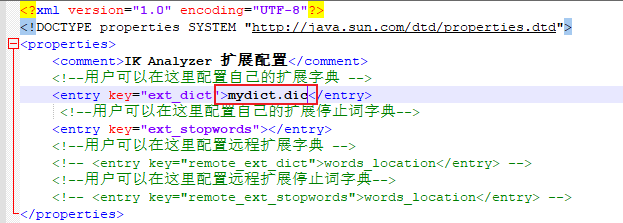
(6)然后再把文件名mydict.dic添加在IKAnalyzer.cfg.xml文件中,然后保存
(7)然后重启es,查看效果
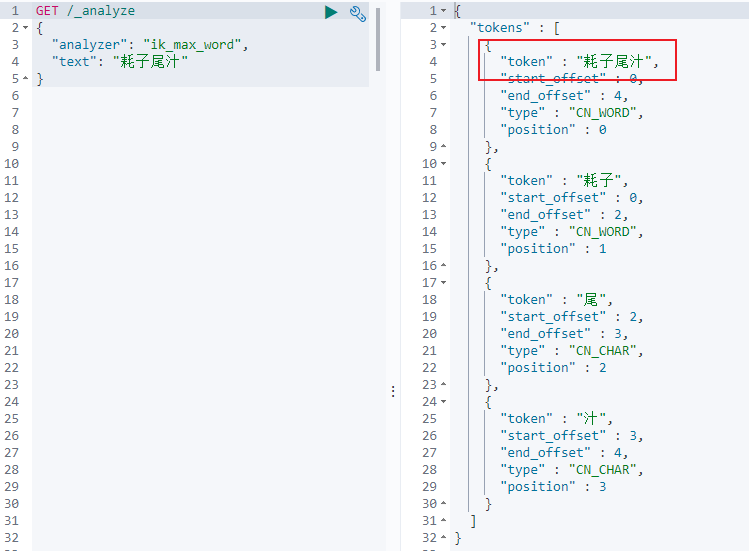
(9)可以看到,耗子尾汁这个词已经能够作为一个整体的词语来做分词了。
3.2 自定义停用词库
比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索。
做法与上面自定义词库类似,这里只是简单的说一下,比方说建立一个mystop.dic文件,把不想建立的索引的词写进文件,把文件与配置文件放在同一个目录,然后在把文件名写进配置文件对应的位置,如下所示
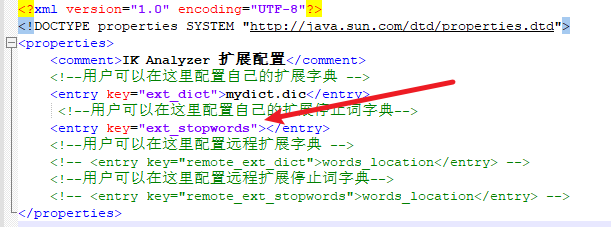
然后在重启es,就可以查看效果了。
这样做的一个好处就是,已经有了常用的中文停用词,但是可以补充自己的停用词。
4、热更新词库
4.1 热更新
每次都是在es的扩展词典中,手动添加新词语,很坑
(1)每次添加完,都要重启es才能生效,非常麻烦
(2)es是分布式的,可能有数百个节点,你不能每次都一个一个节点上面去修改
所以引出热更新的解决方案。es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语
热更新的方案
(1)基于ik分词器原生支持的热更新方案,部署一个web服务器,提供一个http接口,通过modified和tag两个http响应头,来提供词语的热更新,这种方式在官网也提到过。https://github.com/medcl/elasticsearch-analysis-ik

修改了插件配置之后需要重启,如果之后对远程的词库.txt文件修改就不需要再重启ES了,该插件支持热更新分词。
(2)修改ik分词器源码,然后手动支持从数据库中每隔一定时间,自动加载新的词库
一般来说采用第二种方案,第一种,ik git社区官方都不建议采用,觉得不太稳定
4.2 步骤
1、下载源码,https://github.com/medcl/elasticsearch-analysis-ik/releases
ik分词器,是个标准的java maven工程,直接导入idea就可以看到源码
2、修改源
org.wltea.analyzer.dic.Dictionary类,160行Dictionary单例类的初始化方法,在这里需要创建一个我们自定义的线程,并且启动它
org.wltea.analyzer.dic.HotDictReloadThread类:就是死循环,不断调用Dictionary.getSingleton().reLoadMainDict(),去重新加载词典
Dictionary类,399行:this.loadMySQLExtDict(); 加载mysql字典。
Dictionary类,609行:this.loadMySQLStopwordDict();加载mysql停用词
config下jdbc-reload.properties。mysql配置文件
3、mvn package打包代码
target\releases\elasticsearch-analysis-ik-7.3.0.zip
4、解压缩ik压缩包
将mysql驱动jar,放入ik的目录下
5、修改jdbc相关配置
6、重启es
观察日志,日志中就会显示我们打印的那些东西,比如加载了什么配置,加载了什么词语,什么停用词
7、在mysql中添加词库与停用词
8、分词实验,验证热更新生效
这里只是大概的一个步骤,具体情况按照自己的业务逻辑进行开发。
ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库的更多相关文章
- 【自定义IK词典】Elasticsearch之中文分词器插件es-ik的自定义词库
Elasticsearch之中文分词器插件es-ik 针对一些特殊的词语在分词的时候也需要能够识别 有人会问,那么,例如: 如果我想根据自己的本家姓氏来查询,如zhouls,姓氏“周”. 如 ...
- Elasticsearch之中文分词器插件es-ik的自定义词库
它在哪里呢? 非常重要! [hadoop@HadoopMaster custom]$ pwd/home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 31.IK分词器配置文件讲解以及自定义词库
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用 ...
- 30.IK分词器配置文件讲解以及自定义词库
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用 ...
- Elasticsearch之中文分词器插件es-ik的自定义热更新词库
不多说,直接上干货! 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- 沉淀再出发:ElasticSearch的中文分词器ik
沉淀再出发:ElasticSearch的中文分词器ik 一.前言 为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了 ...
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
随机推荐
- [LeetCode]4.寻找两个正序数组的中位数(Java)
原题地址: median-of-two-sorted-arrays 题目描述: 示例 1: 输入:nums1 = [1,3], nums2 = [2] 输出:2.00000 解释:合并数组 = [1, ...
- MySQL 5.7 基于GTID主从复制+并行复制+半同步复制
环境准备 IP HOSTNAME SERVICE SYSTEM 192.168.131.129 mysql-master1 mysql CentOS7.6 192.168.131.130 mysql- ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(十八)——服务保护之多级缓存
很久没有更新dapr系列了.今天带来的是一个小的组件集成,通过多级缓存框架来实现对服务的缓存保护,依旧是一个简易的演示以及对其设计原理思路的讲解,欢迎大家转发留言和star 目录:一.通过Dapr实现 ...
- 【Kotlin】初识Kotlin(二)
[Kotlin]初识Kotlin(二) 1.Kotlin的流程控制 流程控制是一门语言中最重要的部分之一,从最经典的if...else...,到之后的switch,再到循环控制的for循环和while ...
- 已经安装的nginx增加额外配置步骤
这里以安装第三方ngx_http_google_filter_module模块为例nginx的模块是需要重新编译nginx,而不是像apache一样配置文件引用.so1. 下载第三方扩展模块ngx_h ...
- Selenium自动化测试面试题合集
1.什么是自动化测试.自动化测试的优势是什么? 通过工具或脚本代替手工测试执行过程的测试都叫自动化测试. 自动化测试的优势: 1.减少回归测试成本 2.减少兼容性测试成本 3.提高测试反馈速度 4.提 ...
- STL漫游之vector
std::vector 源码分析 从源码视角观察 STL 设计,代码实现为 libstdc++(GCC 4.8.5). 由于只关注 vector 的实现,并且 vector 实现几乎全部在头文件中,可 ...
- low-code
low-code特点: 1. 一个创造软件的开发环境,类似vs-code: 2. 通过可视化拖拽和参数配置高效开发. 1. 背景 1.1 目标 需求的交付质量和交付效率一直是中后台项目开发中非常关注的 ...
- 基于JQuery打造无缝滚动新闻
JQuery实现 新闻无缝滚动 一.使用"首尾追加"实现无缝滚动 <head lang="en"> <meta charset="U ...
- 03-Eureka注册中心
1.介绍 2.快速开始 2.1 pom文件依赖 <?xml version="1.0" encoding="UTF-8"?> <project ...