基于long pull实现简易的消息系统参考
我们都用过消息中间件,它的作用自不必多说。但对于消费者却一直有一些权衡,就是使用push,还是pull模式的问题,这当然是各有优劣。当然,这并不是本文想讨论的问题。我们想在不使用长连接的情意下,如何实现实时的消息消费,而不至于让server端压力过大。大体上来说,这是一种主动拉取pull的方式。具体情况如何,且看且听。
1. 架构示意图
既然是一个消息中间的作用,我们必须得模拟一个生产消费者模型,如下:
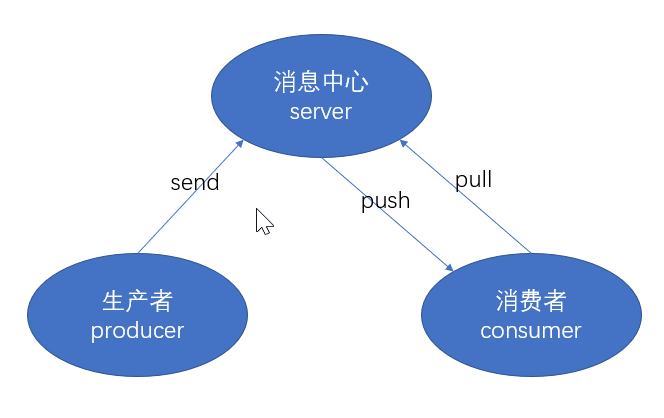
生产者集群->消息中心集群->消费者集群
只是这里的生产和消息中心也许我们可以合二为一,为简单起见,可能我们消费者只是想知道数据发生了变化。
以上是一个通用模型,接下来再说说我如何以long pull消息消费,其流程图如下:
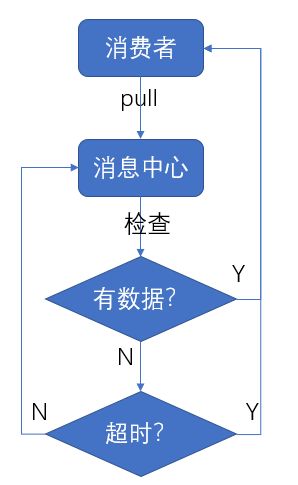
消费者一直请求连接->消息中心->有数据到来或者超时->消费者处理数据->发送ack确认->继续请求连接
如此一来,我们基本上就实现了一个消费模型了。但是有个问题,我们一直在不停地请求server,这会不会让server疲于奔命?是的,如果按照正常的http请求,就是不停地建立连接,处理数据,关闭连接等等。在没有消息到来之前,可以说,server会一直被这无用功跑死,它的qps越高,压力也越大。所以,我们使用了一种long pull的方式,让server端不要那么快返回没有意义的数据。但,这可能不是一件容易的事。
2. long pull的实现方式
long pull从原理上来说就是,必要的时候hold住连接,直到某个时机才返回。这和长链接有点类似。
至于为什么不用长连接实现,我想至少有两个原因:一是long pull一般基于http协议,实现简单且通用,而如果要基于长链接则需要了解太多的通信细节太复杂;二是端口复用问题,long pull可以直接基于业务端口实现,而长连接则必须要另外开一个通信端口,这在实际运维过程中也许不那么好操作,主要原因可能是我们往往不是真正的中间件,还达不到与架构或运维pk端口标准的资本。
说回正题,如何实现long pull?这其实和你使用的框架有关。但简单来说都可以这样干,请求进来后,我只要一直不返回即可。而且这也许是许多框架或语言的唯一选择。
如果咱们是java语言且基于spring系列框架,则可以用另外一种异步的方式。用上一种通用的实现方式的缺点是:当一个请求一直不返回后,必然占用主连接池,从而影响其他业务接口的请求处理,就是说只要你多接入几个这种请求,业务就别想有好日子过了。所以,我们选择异步的方式。异步,听起来是个好名词,但又该如何实现呢?我们普通异步,可能是直接丢到一个队列去,然后由后台线程一直处理即可,听起来不错。但这种请求至少两个问题:一是当我们提交到任务队列之后,连接还存在吗?二是我们敢让请求排队吗?因为如果排队有新数据进来,可就不面对实时的承诺了。
所以,针对上面的问题,spring系列有了解决方案。使用异步 servlet(async servlet),其操作步骤如下:
1 controller中返回异步实例callable;
2 在servlet中配置异步支持标识(统一配置);
比如下面的demo:
// controller
@GetMapping(value = "/consumeData")
public Object consumeData(@RequestParam String topicName,
@RequestParam Long offset,
@RequestParam Long maxWait) {
// 必要的时候需要在 web.xml中配置 <async-supported>true</async-supported>
Callable<String> callable = () -> {
SleepUtil.sleepMillis(10_000L);
System.out.println("data come in, got out.");
return "ok";
}; return callable;
}
// web.xml
// 所有需要的filter和servlet中,添加
<async-supported>true</async-supported>
具体的框架版本各自具体配置可能不一样,自行查找资料即可。
以上,就解决了long pull的问题了。
3. 主键id的实现
主键id至少有两个作用:一是可用于唯一定位一条消息;二是可以用于去重做幂等;其实一般还有一个目的就是用于确认消息的先后顺序;
所以主键id很重要,往往需要经过精心的设计。但,我们这里可以简单的基于redis的自增key来处理即可。既保证了性能,又保证了唯一性,还保证了先后顺序问题。这就为后续消息的存储带来了方便。比如可以用zset存储这个消息id。
4. 数据到来的检测实现
在server端hold连接的同时,它又是如何发现数据已经到来了呢?
最简单的,可以让每个请求每隔一定时间,去查询一次数据,如果有则返回。但这个实现既不优雅也不经济也不实时,但是简单,可以适当考虑。
好点的方式,使用wait/notify机制,简单来说比如使用一个CountDownLatch,没有数据时则进行wait,数据到来时进行notify。这样下不来,不用每个请求反复查询数据,导致server压力变大,同时也让系统调度压力减小了,而且能够做到实时感知数据,可以说是很棒的选择。只是,这必然有很多的细节问题需要处理,稍有不慎,可能就是一个坑。比如:死锁问题,多节点问题,网络问题。。。 随便来一个,也许就jj了。
好好处理这个问题,总是好的。
5. 消息中心实现demo
5.1. 消费者生产者controller
两个简单方法入口,生产+消费 。
@RestController
@RequestMapping("/simpleMessageCenter")
public class SimpleMessageCenterController { @Resource
private MessageService messageService; // 消费消息
@GetMapping(value = "/consumeData")
public Object consumeData(@RequestParam String topicName,
@RequestParam Long offset,
@RequestParam Long maxWait) {
// 必要的时候需要在 web.xml中配置 <async-supported>true</async-supported>
Callable<String> callable = () -> {
try {
Object data = messageService.consumeData(topicName, offset, maxWait);
return JSONObject.toJSONString(data);
}
catch (Exception e){
e.printStackTrace();
return "error";
}
}; return callable;
} // 发送消息
@GetMapping(value = "/sendMsg")
public Object sendMsg(@RequestParam String topicName,
@RequestParam String extraId,
@RequestParam String data) {
messageService.sendMsg(topicName, extraId, data);
return "ok";
}
}
5.2. 核心service简化版
由redis作为存储,展示各模块间的协作。
@Service
public class MessageService { @Resource
private RedisTemplate<String, String> redisTemplate; // 消费闭锁
private volatile ConcurrentHashMap<String, CountDownLatch>
consumeLatchContainer = new ConcurrentHashMap<>(); // 消费数据接口
public List<Map<String, Object>> consumeData(String topic,
Long offset,
Long maxWait) throws InterruptedException {
long startTime = System.currentTimeMillis();
final CountDownLatch myLatch = getOrCreateConsumeLatch(topic);
List<Map<String, Object>> result = new ArrayList<>();
do {
ZSetOperations<String, String> queueHolder
= redisTemplate.opsForZSet();
Set<ZSetOperations.TypedTuple<String>> nextData
= queueHolder.rangeByScoreWithScores(topic, offset, offset + 100);
if(nextData == null || nextData.isEmpty()) {
long timeRemain = maxWait - (System.currentTimeMillis() - startTime);
myLatch.await(timeRemain, TimeUnit.MILLISECONDS);
continue;
}
for (ZSetOperations.TypedTuple<String> queue1 : nextData) {
Map<String, Object> queueWrapped = new HashMap<>();
queueWrapped.put(queue1.getValue(), queue1.getScore());
result.add(queueWrapped);
}
break;
} while (System.currentTimeMillis() - startTime <= maxWait);
return result;
} // 获取topic级别的锁
private CountDownLatch getOrCreateConsumeLatch(String topicName) {
return consumeLatchContainer.computeIfAbsent(
topicName, k -> new CountDownLatch(1));
} // 接收到消息存储请求
public void sendMsg(String topic, String extraIdSign, String data) {
ValueOperations<String, String> strOp = redisTemplate.opsForValue();
Long msgId = strOp.increment(topic + ".counter");
// todo: 1. save real data
// 2. 加入通知队列
ZSetOperations<String, String> zsetOp = redisTemplate.opsForZSet();
zsetOp.add(topic, extraIdSign, msgId);
wakeupConsumers(topic, extraIdSign);
} // 唤醒消费者,一般是有新数据到来
private void wakeupConsumers(String topic, String extraIdSign) {
CountDownLatch consumeLatch = getOrCreateConsumeLatch(topic);
consumeLatch.countDown();
rolloverConsumeLatch(topic, extraIdSign);
} // 产生新一轮的锁
private void rolloverConsumeLatch(String topic, String extraIdSign) {
consumeLatchContainer.put(topic, new CountDownLatch(1));
}
}
5.3. 功能测试
因为是使用http接口实现,所以,可以直接通过浏览器实现功能测试。一个地址打开生产者链接,一个打开消费者链接。
// 1. 先访问消费者
http://localhost:8081/simpleMessageCenter/consumeData?topicName=q&offset=19&maxWait=50000
// 2. 再访问生产者
http://localhost:8081/simpleMessageCenter/sendMsg?topicName=q&extraId=d3&data=aaaaaaaaaaa
在生产者没有数据进来前,消费者会一直在等待,而生产者产生数据后,消费者就立即展示结果了。我们要实现的,不就是这个效果吗?
5.4. 消费者一直请求样例
在浏览器上我们看到的只是一次请求,但如果真正想实现,一直消费数据,则必须有一种订阅的感觉。其实就是不停的请求,处理,再请求的过程。
public class SimpleMessageCenterTest {
@Test
public void testConsumerSubscribe() {
long offset = 0;
String urlPrefix = "http://localhost:8081/simpleMessageCenter/consumeData?topicName=q&maxWait=50000&offset=";
while (!Thread.interrupted()) {
String dataListStr = HttpUtils.doGet(urlPrefix + offset);
System.out.println("offsetStart: " + offset + ", got data:" + dataListStr);
List<Object> dataListParsed = JSONObject.parseArray(dataListStr);
// 不解析最终的offset了,大概就是根据最后一次offset再发起请求即可
offset += dataListParsed.size();
}
}
}
以上,就是本次分享的小轮子了。我们抛却了消息系统中的一个重要且复杂的环节:存储。供参考。
基于long pull实现简易的消息系统参考的更多相关文章
- Kafka 分布式的,基于发布/订阅的消息系统
Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 高吞吐量:即使是非常 ...
- [转] 消息系统该Push/Pull模式分析
信息推拉技术简介 “智能信息推拉(IIPP)技术”是在网上信息获取技术中加入了智能成份,从而有助于用户在海量信息中高效.及时地获取最新信息,提高了信 息系统主动信息服务的能力.如果引入基于IIPP的主 ...
- 基于SQL Server 2008 Service Broker构建企业级消息系统
注:这篇文章是为InfoQ 中文站而写,文章的地址是:http://www.infoq.com/cn/articles/enterprisemessage-sqlserver-servicebroke ...
- 分布式开放消息系统(RocketMQ)的原理与实践
分布式消息系统作为实现分布式系统可扩展.可伸缩性的关键组件,需要具有高吞吐量.高可用等特点.而谈到消息系统的设计,就回避不了两个问题: 消息的顺序问题 消息的重复问题 RocketMQ作为阿里开源的一 ...
- kafka:一个分布式消息系统
1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布式实现的很奇怪,所以希望找一个适 ...
- Kafka是分布式发布-订阅消息系统
Kafka是分布式发布-订阅消息系统 https://www.biaodianfu.com/kafka.html Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apa ...
- 分布式消息系统:Kafka
Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务.它主要用于处理活跃的流式数据. ...
- Kafka——分布式消息系统
Kafka——分布式消息系统 架构 Apache Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群. 设 ...
- 【转载】Apache Kafka:下一代分布式消息系统
http://www.infoq.com/cn/articles/kafka-analysis-part-1 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩 ...
随机推荐
- SQL 在数据库中查找拥有此列名的所有表
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE COLUMN_NAME='Column' #"Column"为要查询 ...
- 非极大值抑制算法(Python实现)
date: 2017-07-21 16:48:02 非极大值抑制算法(Non-maximum suppression, NMS) 算法原理 非极大值抑制算法的本质是搜索局部极大值,抑制非极大值元素. ...
- SQL注入蠕虫分析//未完待续
蠕虫代码: DECLARE @S VARCHAR(4000);SET @S=CAST(0x4445434C415245204054205641524348415228323535292C4043205 ...
- java-23种设计模式概述【软件设计模式基本介绍(是什么、作用、优点)、模式的分类和介绍】
一.设计模式基本介绍(是什么.作用.优点) 1.软件设计模式是什么? 软件设计模式(Software Design Pattern),又称设计模式. 2.设计模式的作用 ★ 提高代码的可复用性.可维护 ...
- bugku ctf 杂项 旋转跳跃 (熟悉的声音中貌似又隐藏着啥,key:syclovergeek)
做这道题之前先给出工具 MP3Stego 下载地址 链接:https://pan.baidu.com/s/1W2mmGJcrm570EdJ6o7jD7g 提取码:1h1b 题目下载加压后 是一个 ...
- [题解]Codeforces Round #519 - A. Elections
[题目] A. Elections [描述] Awruk和Elodreip参加选举,n个人投票,每个人有k张票,第i个人投a[i]张票给Elodreip,投k-a[i]张票给Awruk.求最小的k,使 ...
- Html简单标签
学习html <h1> 标题标签</h1> 标题标签 <p>段落标签</p> 段落标签 换行标签</br> 换行标签 水平线标签</h ...
- C# 成员访问修饰符protected internal等
1.C#4个修饰符的权限修饰符 级别 适用成员 解释public 公开 类及类成员的修饰符 对访问成员没有级别限制private 私有 类成员的修饰符 只能在类的内部访问protected 受保护 ...
- Hadoop - HDFS学习笔记(详细)
第1章 HDFS概述 hdfs背景意义 hdfs是一个分布式文件系统 使用场景:适合一次写入,多次读出的场景,且不支持文件的修改. 优缺点 高容错性,适合处理大数据(数据PB级别,百万规模文件),可部 ...
- 初识html及网络爬虫概念
网络爬虫 HTML超文本标记语言 HTTP协议 简单的网络请求 python模块模拟浏览器发送请求 爬虫小案例 爬虫简介 我们一般情况 都是通过浏览器正常访问服务端获取资源浏览器展示给用户看 爬虫 模 ...