【pytest官方文档】解读- 如何自定义mark标记,并将测试用例的数据传递给fixture函数
在之前的分享中,我们知道可以使用yield或者return关键字把fixture函数里的值传递给test函数。
这种方法很实用,比如我在fixture函数里向数据库里插入必要的测试数据,那我就可以把相关数据返回给test函数用来做相关断言查询等操作。
那如果我想把test函数(也就是测试用例)中的数据传给fixture函数使用,要如何实现呢?
直接先贴上一段示例代码:
import pytest
@pytest.fixture
def fixt(request):
marker = request.node.get_closest_marker("fixt_data")
if marker is None:
# Handle missing marker in some way...
data = None
else:
data = marker.args[0]
# Do something with the data
return data
@pytest.mark.fixt_data(42)
def test_fixt(fixt):
assert fixt == 42
一、前置知识
代码中可能有2个知识点,可能有的小伙伴并不熟悉,分别来看下。
1. Mark 标记
什么是mark标记,干什么用?
标记可以将元数据应用于测试函数(注意,不能是fixture函数),后续可以通过fixture函数或者plugins插件进行访问。
框架有一些内置的marks,也可以支持我们自定义。
内置的在之前的系列分享中有出现过几个,比如:
pytest.mark.parametrize:参数化pytest.mark.skip:跳过测试用例pytest.mark.skipif: 根据条件跳过用例
其他就不展开了,上述提到的分享文章链接会附在文末。
而在上述示例代码中,pytest.mark.fixt_data则是属于自定义的mark标记,fixt_data我也可以改成fixt_pingguo也是可以的。
2. request
request本身也是一个fixture函数,但是很特殊,用于提供当前正在执行请求的上下文信息。
在上述示例代码中,测试函数test_fixt请求了fixture函数fixt,那么在这次请求中相关联到的信息就可以在request中获得。
比如:
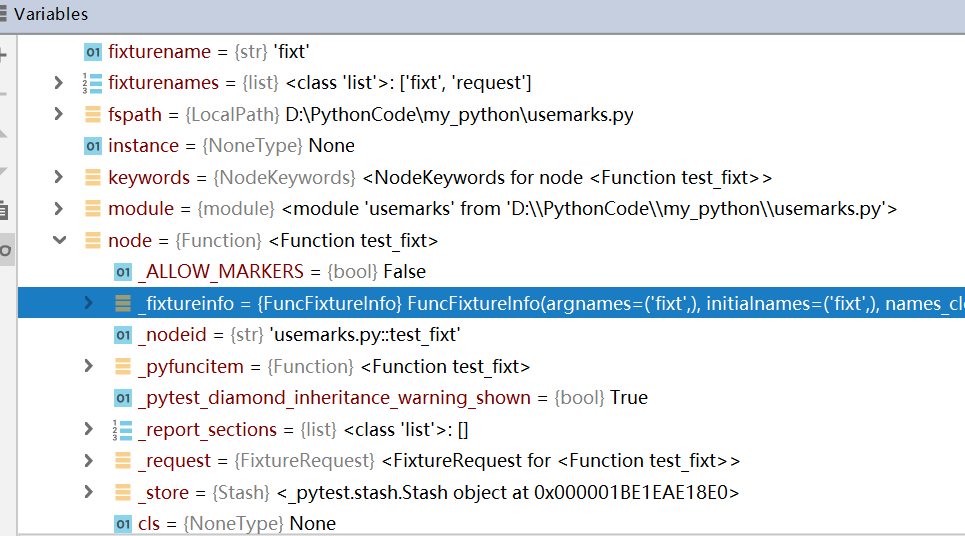
fixturename: 当前这个fixture函数的名称module: 当前测试函数所在的模块scope:当前fixture函数作用范围node:基于当前测试范围搜集到的底层节点对象,这里又包含了很多信息。
...
就不一一展开了,有兴趣的童鞋可以在编辑器里打个断点,查看对应的信息详情。
二、通过自定义mark传递数据
回到示例代码,我们可以先直接执行一下代码。
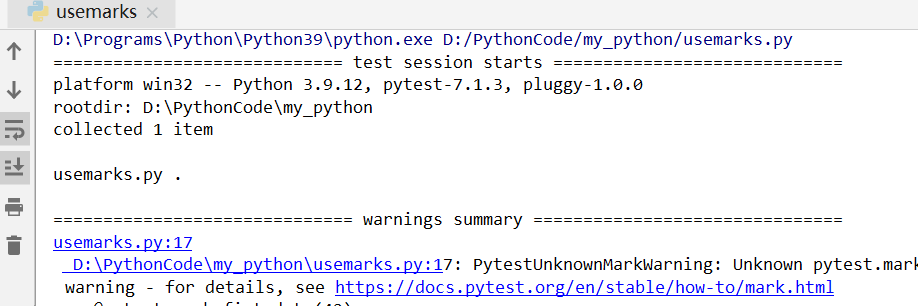
测试是通过的(warning先忽略,因为没有注册自定义的mark),也就是说@pytest.mark.fixt_data(42)中的42是成功的带到了fixture函数中,经过函数中的处理后最后返回出来。
其中的get_closest_marker("fixt_data")方法,是返回与名称fixt_data匹配的第一个mark,从最近的级别到更远的级别,比如从函数到模块级别。
所以在这里,被找到的mark就是我们自定义的这个@pytest.mark.fixt_data(42)标记了。
1. 自定义mark知识点
标记是使用工厂对象pytest.mark动态创建的,用于装饰器,所以我们可以用语法糖@直接使用即可。
mark对象被创建之后,就被会收集起来,然后可以通过fixture或带有Node.iter_markers的钩子函数访问,可以访问到这个mark对象的属性。
有 2 个属性:
mark.args:这是个元组mark.kwargs:这是个字典
所以我们可以使用上面的方式来进行传参,比如现在新建一个自定义mark:
@pytest.mark.timeout(10, "slow", method="thread")
def test_function():
...
这里传参实际上就是
mark.args == (10, "slow")
mark.kwargs == {"method": "thread"}
回到最上方的示例代码,在fixture函数中就可以使用data = marker.args[0]来获取到参数42。
如果在测试函数上同时使用了多个自定义mark,那么举例测试函数最近的mark就会被首先迭代。比如:
@pytest.mark.timeout(10, "slow", method="thread")
@pytest.mark.slow
def test_function():
...
结果就是先@pytest.mark.slow,然后是@pytest.mark.timeout。
2. 注册自定义的mark
在运行最上方的示例代码时出现了一个warning,因为我们没有注册自定义的标记导致,现在来进行注册。
新建pytest.ini配置文件,在里面添加即可:
[pytest]
markers =
fixt_data: pingguo test
fixt_data2
这里冒号:后面的描述是可选的,比如fixt_data2就是没有添加描述。
重新执行下最上方的代码:
platform win32 -- Python 3.9.12, pytest-7.1.3, pluggy-1.0.0
rootdir: D:\PythonCode\my_python, configfile: pytest.ini
collected 1 item
usemarks.py .
============================== 1 passed in 0.00s ==============================
Process finished with exit code 0
注册完成。
pytest合集见连接
【pytest官方文档】解读- 如何自定义mark标记,并将测试用例的数据传递给fixture函数的更多相关文章
- 【pytest官方文档】解读fixtures - 1.什么是fixtures
在深入了解fixture之前,让我们先看看什么是测试. 一.测试的构成 其实说白了,测试就是在特定的环境.特定的场景下.执行特定的行为,然后确认结果与期望的是否一致. 就拿最常见的登录来说,完成一次正 ...
- 【pytest官方文档】解读fixtures - 2. fixtures的调用方式
既然fixtures是给执行测试做准备工作的,那么pytest如何知道哪些测试函数 或者 fixtures要用到哪一个fixtures呢? 说白了,就是fixtures的调用. 一.测试函数声明传参请 ...
- 【pytest官方文档】解读fixtures - 3. fixtures调用别的fixtures、以及fixture的复用性
pytest最大的优点之一就是它非常灵活. 它可以将复杂的测试需求简化为更简单和有组织的函数,然后这些函数可以根据自身的需求去依赖别的函数. fixtures可以调用别的fixtures正是灵活性的体 ...
- Cuda 9.2 CuDnn7.0 官方文档解读
目录 Cuda 9.2 CuDnn7.0 官方文档解读 准备工作(下载) 显卡驱动重装 CUDA安装 系统要求 处理之前安装的cuda文件 下载的deb安装过程 下载的runfile的安装过程 安装完 ...
- 【pytest官方文档】解读- 插件开发之hooks 函数(钩子)
上一节讲到如何安装和使用第三方插件,用法很简单.接下来解读下如何自己开发pytest插件. 但是,由于一个插件包含一个或多个钩子函数开发而来,所以在具体开发插件之前还需要先学习hooks函数. 一.什 ...
- 【pytest官方文档】解读- 开发可pip安装的第三方插件
在上一篇的 hooks 函数分享中,开发了一个本地插件示例,其实已经算是在编写插件了.今天继续跟着官方文档学习更多知识点. 一个插件包含一个或多个钩子函数,pytest 正是通过调用各种钩子组成的插件 ...
- 【pytest官方文档】解读fixtures - 8. yield和addfinalizer的区别(填坑)
在上一章中,文末留下了一个坑待填补,疑问是这样的: 目前从官方文档中看到的是 We have to be careful though, because pytest will run that fi ...
- 【pytest官方文档】解读fixtures - 7. Teardown处理,yield和addfinalizer
当我们运行测试函数时,我们希望确保测试函数在运行结束后,可以自己清理掉对环境的影响. 这样的话,它们就不会干扰任何其他的测试函数,更不会日积月累的留下越来越多的测试数据. 用过unittest的朋友相 ...
- 【pytest官方文档】解读fixtures - 10. fixture有效性、跨文件共享fixtures
一.fixture有效性 fixture有效性,说白了就是fixture函数只有在它定义的使用范围内,才可以被请求到.比如,在类里面定义了一个fixture, 那么就只能是这个类中的测试函数才可以请求 ...
随机推荐
- 上线项目之局域网上线软件使用-----phpStudy
上面的图片是phpStudy的软件截图.那么你在哪里会下到呢?链接: https://pan.baidu.com/s/1lvX9jY_K6gGkMOqo76p4nA 提取码: h1it 复制这段内容后 ...
- 校验日期格式为yyyy-MM-dd
/** * 校验时间 * * @param text * @return */ public static boolean checkTime(String text) { DateFormat fo ...
- Linux YUM制作自己的yum repository
Linux YUM制作自己的yum repository 配置步骤: 1.通过网络发布自己的package目录 2.创建本地repository 3.配置自己的yum源 操作实现: 1 安装creat ...
- NC24840 [USACO 2009 Mar S]Look Up
NC24840 [USACO 2009 Mar S]Look Up 题目 题目描述 Farmer John's N (1 <= N <= 100,000) cows, convenient ...
- 多校联训 DP 专题
[UR #20]跳蚤电话 将加边变为加点,方案数为 \((n-1)!\) 除以一个数,\(dp\) 每种方案要除的数之和即可. 点击查看代码 #include<bits/stdc++.h> ...
- 《A Neural Algorithm of Artistic Style》理解
在美术中,特别是绘画,人类掌握了通过在图像的内容和风格间建立复杂的相互作用从而创造独特的视觉体验的技巧.到目前为止,这个过程的算法基础是未知的,也没有现存的人工系统拥有这样的能力.然而在视觉感知的其他 ...
- 常用Linux命令整理
常见系统命令 export 查看或修改环境变量 # 例:临时修改命令提示符为字符串$ export PS1=$ # 例:临时修改命令提示符显示系统时间 时间使用\t 表示 export PS1=&qu ...
- 如何学习Vim
如果你是Linux用户,学习Vim会有很大的好处. 如果你是windows用户,个人建议还是使用vscode. 准备大约40min的学习时间,打开终端,输入下面命令开启自带教程 vimtutor 按操 ...
- 快来体验快速通道,netty中epoll传输协议详解
目录 简介 epoll的详细使用 EpollEventLoopGroup EpollEventLoop EpollServerSocketChannel EpollSocketChannel 总结 简 ...
- 2022 07 13 第一小组 田龙跃 Java再学习笔记
1.类名命名规则: 只能由数字字母,下划线,美元符号组成(不能以数字开头,尽量不要用下划线开头) 2.注释(养成多写注释的好习惯) 单行注释 // ctrl+/ 多行注释 // ctrl+shirt+ ...