Python BeautifulSoup4 爬虫基础、多线程学习
针对 崔庆才老师 的 https://ssr1.scrape.center 的爬虫基础练习
BeautifulSoup官方文档:readthedocs
总共用时:2小时 (代码在最后面)
学习内容:Threading多线程库、Time库、json库、BeautifulSoup4 爬虫库、py基本语法
学习建议:我是爬虫零基础,也没有看什么教程视频,只开了bs4的官方文档,那个文档写的比较详细。重点F12观察网页的Dom结构。多用搜索引擎。我会把我搜索过的问题放在下方供大家参考。这方面库比较完善,不是很难,会应用即可。
踩过的坑
1、爬虫简介
爬虫简介 - 人生不如戏 - 博客园 (cnblogs.com)
2、Python基础时间库
Python基础时间库——time - 苦逼运维 - 博客园 (cnblogs.com)
Python库:time库_mulus的博客-CSDN博客_python time库
3、Threading多线程库
Python内置库:threading(多线程) - 山上下了雪-bky - 博客园 (cnblogs.com)
Python多线程(threading.Thread)的用法 - 简书 (jianshu.com)
Python之threading初探 - 知乎 (zhihu.com)
Python等待所有线程任务完成_Zhang Phil-CSDN博客_python 等待线程结束
Python3 多线程 | 菜鸟教程 (runoob.com)
4、python循环10次怎么写
for i in range(10):
print("123")5、Python三元运算符
使用 if else 实现三目运算符(条件运算符)的格式如下:
exp1 if contion else exp26、json.dumps输出的中文乱码问题
添加参数ensure_ascii=False
json.dumps(data, indent=4, ensure_ascii=False)7、python保留两位小数
python保留两位小数 - psztswcbyy - 博客园
8、Python 编码错误 UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 33: illegal..
file = open("data.json", "w")
# 改为
file = open("data.json", "w", encoding="utf-8")9、正则表达式re.compile()的使用
正则表达式re.compile()的使用_精灵码农-CSDN博客_recompile的意思
10、单线程与多线程时间比较
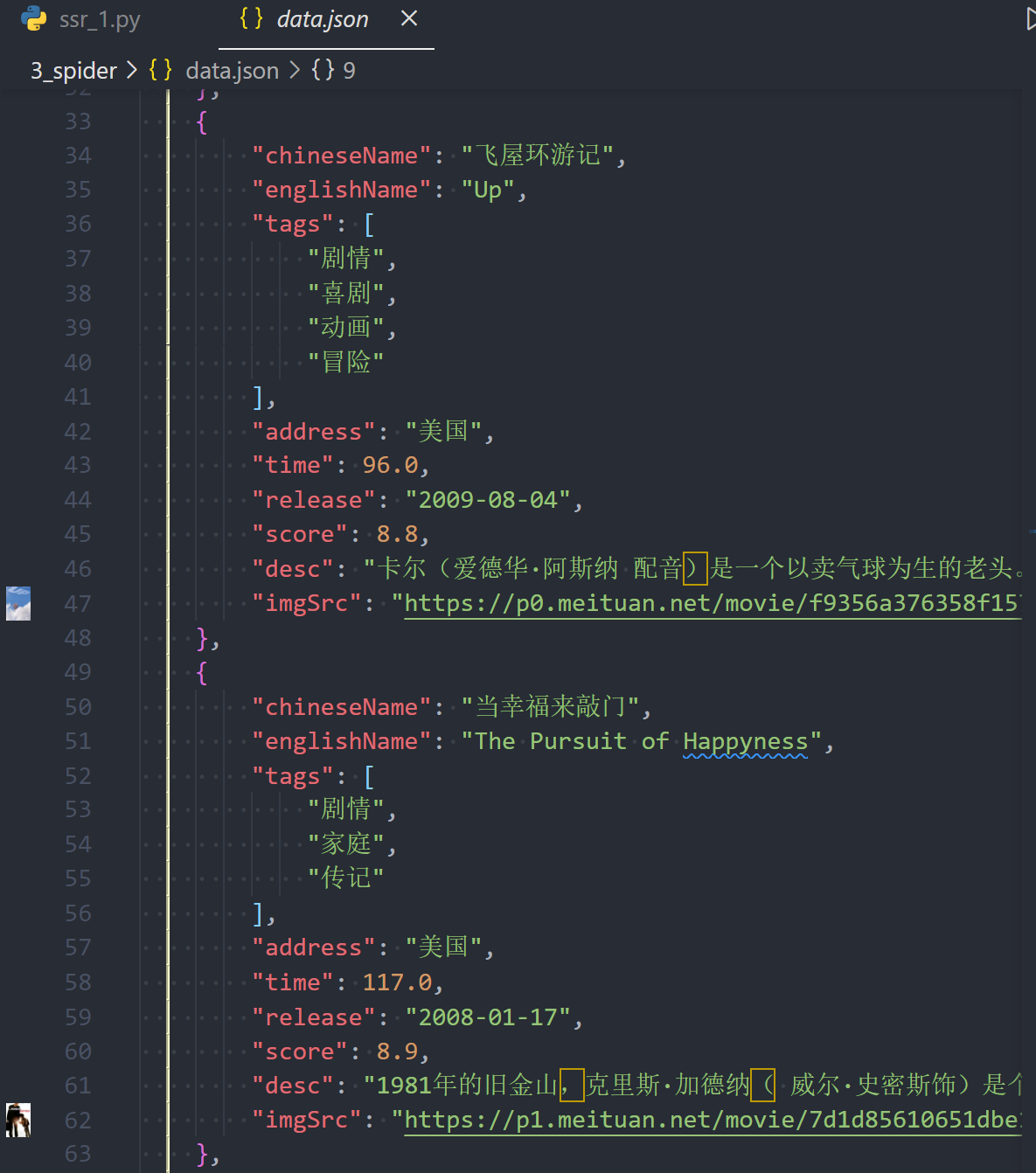
每个电影的简介在另一个单独的页面里,共100部电影有100个页面,加10个电影分页页面共110个页面
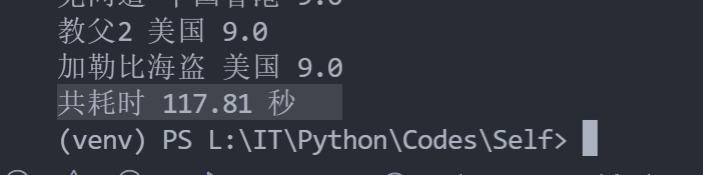
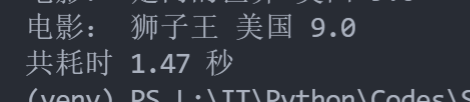
单线程耗时(110个页面)
每页一个线程耗时(110个页面)
单线程耗时(注释掉新页面电影简介读取)(10个页面)
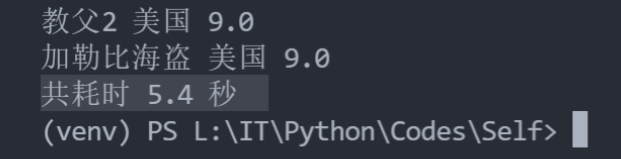
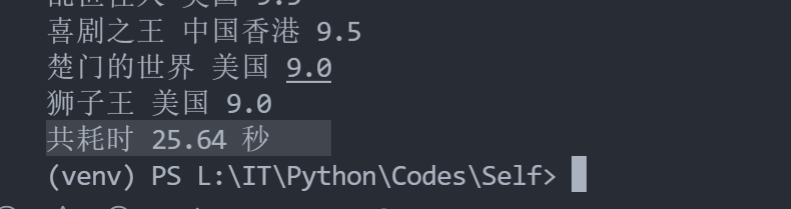
每页一个线程耗时(注释掉新页面电影简介读取)(10个页面)
11、怎么使用开发者工具
- 打开你的浏览器,网址 Scrape | Movie
- 按下F12打开开发者控制台
- 对网页上感兴趣的内容右键点检查
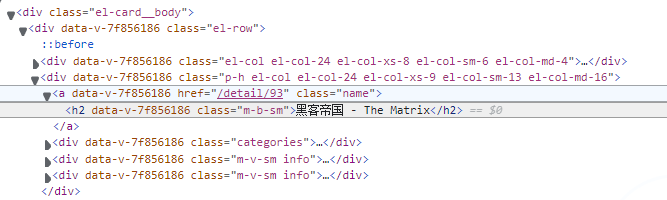
- 可以看到标签为h2,class="m-b-sm" 的标签有我们感兴趣的内容,查阅bs4文档使用相关方法
我的代码
import requests
import threading
import time
import json
from bs4 import BeautifulSoup
# @ 将需要爬的URL拆分
host = 'https://ssr1.scrape.center'
api = '/page/{}'
page = 1
data = []
def MySpider(host, api, page):
web = requests.get(host+api.format(page))
# @ 官方建议的解析方法
web = BeautifulSoup(web.text, 'lxml')
# print(web.title)
# @ 使用浏览器的F12开发者工具查看DOM结构,找到我们感兴趣的层的class
res = web.find_all(class_="el-card__body")
# print(res.__len__())
# print(res[0])
# @ 每页十条,res是个数组
for item in res:
# ^ 读取电影名称
Name = item.find(class_="name")
name = Name.h2.string.split('-')
# @ 用这种方式去左右空格和字符
chineseName = name[0].strip()
englishName = name[1].strip()
# print(chineseName, englishName)
# ^ 读取电影地址
href = host+Name['href']
# print(href)
# ^ 读取电影图片地址
# @ src 是属性,所以不用string获取
imgSrc = item.find('img', class_="cover")['src']
# print(imgSrc)
# ^ 读取类别信息
tags = []
Tags = item.find_all(class_="category")
for tag in Tags:
tags.append(tag.span.string)
# print(tags)
# ^ 读取其他信息
Info = item.find_next(class_="info")
Infos = Info.find_all('span')
address = Infos[0].string
time = float(Infos[2].string.strip(' 分钟'))
# ^ 切换到下一个info div
Info = Info.find_next(class_="info")
# @ 三元运算符
release = Info.span.string.strip(' 上映') if Info.span else ""
# print(address, time, release)
# ^ 读取分数(类型转换)
score = float(item.find(class_='score').string)
# print(score)
# ^ 读取剧情简介
WebDetail = requests.get(href)
WebDetail = BeautifulSoup(WebDetail.text, 'lxml')
detail = WebDetail.find(class_="drama").p.string.strip()
# print(detail)
# ^ test
print("电影:", chineseName, address, score)
data.append(
dict(
chineseName=chineseName,
englishName=englishName,
tags=tags,
address=address,
time=time,
release=release,
score=score,
desc=detail,
imgSrc=imgSrc
)
)
# ^ 统计时间
start = time.perf_counter()
threads = []
for page in range(10):
# MySpider(host, api, page)
t = threading.Thread(target=MySpider, args=(host, api, page))
threads.append(t)
t.start()
# ^ 等待所有子线程结束,主线程再运行
for t in threads:
t.join()
end = time.perf_counter()
print("共耗时", round(end-start, 2), "秒")
print(data)
# ^ 格式化JSON,并防止转换成Unicode
data = json.dumps(data, indent=4, ensure_ascii=False)
# ^ encoding="utf-8" 防止保存出错
file = open("data.json", "w", encoding="utf-8")
file.write(data)
file.close()
print(data)
点赞是一种积极的生活态度,喵喵喵!(疯狂暗示)
Python BeautifulSoup4 爬虫基础、多线程学习的更多相关文章
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- Python扫描器-爬虫基础
0x1.基础框架原理 1.1.爬虫基础 爬虫程序主要原理就是模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中 1.1.基础原理 1.发起HTTP请求 2 ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python 网页爬虫+保存图片+多线程+网络代理
今天,又算是浪费了一天了.python爬虫,之前写过简单的版本,那个时候还不懂原理,现在算是收尾吧. 以前对网页爬虫不了解,感觉非常神奇,但是解开这面面纱,似乎里面的原理并不是很难掌握.首先,明白一个 ...
- 自学Python六 爬虫基础必不可少的正则
要想做爬虫,不可避免的要用到正则表达式,如果是简单的字符串处理,类似于split,substring等等就足够了,可是涉及到比较复杂的匹配,当然是正则的天下,不过正则好像好烦人的样子,那么如何做呢,熟 ...
- 自学Python四 爬虫基础知识储备
首先,推荐两个关于python爬虫不错的博客:Python爬虫入门教程专栏 和 Python爬虫学习系列教程 .写的都非常不错,我学习到了很多东西!在此,我就我看到的学到的进行总结一下! 爬虫就是 ...
- python网络爬虫与信息提取 学习笔记day2
Day2: 查看robots协议: 查看京东的robots协议 查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233 爬取京东商品页面相关信息: import requests url = ...
- Java基础-多线程学习目录
1.Java多线程并发编程一览笔录 2.什么时候使用CountDownLatch 3.Java并发学习系列-绪论
- Python归纳 | 爬虫基础知识
1. urllib模块库 Urllib是python内置的HTTP请求库,urllib标准库一共包含以下子包: urllib.error 由urllib.request引发的异常类 urllib.pa ...
随机推荐
- Java 反射的用法 有关Class类的解释
package com.imooc.test;public class ClassDemo1 { public static void main(String[] args) { Foo fool = ...
- Python之VSCode
在学习Python的过程中,一直没有找到比较趁手的第三方编辑器,用的最多的还是Python自带的编辑器.由于本人用惯了宇宙第一IDE(Visual Studio),所以当Visual Studio C ...
- 超详细GoodSync11.2.7.8单机、两个服务器之间的文件同步使用教程
GoodSync安装教程 第一步:双机GoodSync_v11.2.7.8.exe文件 链接:https://pan.baidu.com/s/16FVater4f9vu07QiGGIK9A 提取码:b ...
- python豆瓣250爬取
import requests from bs4 import BeautifulSoup from lxml import etree # qianxiao996精心制作 #博客地址:https:/ ...
- request的自动urlencode问题解决
今天写盲注脚本的时候,由于题目对空格进行了过滤,所以必须要用%09进行代替,然而当我在脚本中,将payload的空格替换成%09的时候,抓包发现进行了两次编码,导致脚本一直跑不通. 自己在网上也没有找 ...
- python练习册 每天一个小程序 第0001题
1 # -*-coding:utf-8-*- 2 __author__ = 'Deen' 3 ''' 4 题目描述: 5 做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生 ...
- BGP的五种报文六种状态
BGP的五种报文 Open报文:用于协商BGP参数,包括版本号,AS号等信息.在两个路由器之间建立了TCP会话之后开始交换Open信息以确认是否能形成邻居关系,是TCP建立后发送的第一个信息,类似OS ...
- 为什么你需要在用 Vue 渲染列表数据时指定 key
本文改写整理自一篇博文,原文链接如下: Why you should use the key directive in Vue.js with v-for Application state and ...
- Linux下离线安装docker与fastDFS
一.Linux下离线安装Docker 基础环境 1.操作系统:CentOS 7 2.Docker版本:docker-19.03.9.tgz 官方下载地址(打不开可能需要科学-上网) 3.官方参考文档: ...
- String常用方法解析
package com.javaBase.string; import java.util.Locale; /** * 〈一句话功能简述〉; * 〈String类中常用的方法整理〉 * * @auth ...