python网络爬虫与信息提取 学习笔记day2
Day2:
查看robots协议:
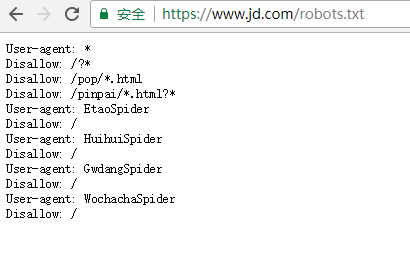
查看京东的robots协议
查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233

爬取京东商品页面相关信息:
import requests
url = "https://item.jd.hk/1974631870.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("产生异常")

爬取亚马逊商品页面相关信息:
由于亚马逊拒绝爬虫访问,所以需要更改header的值,将python伪装成浏览器访问
import requests
url = "https://www.amazon.cn/dp/B0186FESGW/ref=fs_kin"
try:
kv = { 'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers = kv)
r.status_code
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("产生异常")

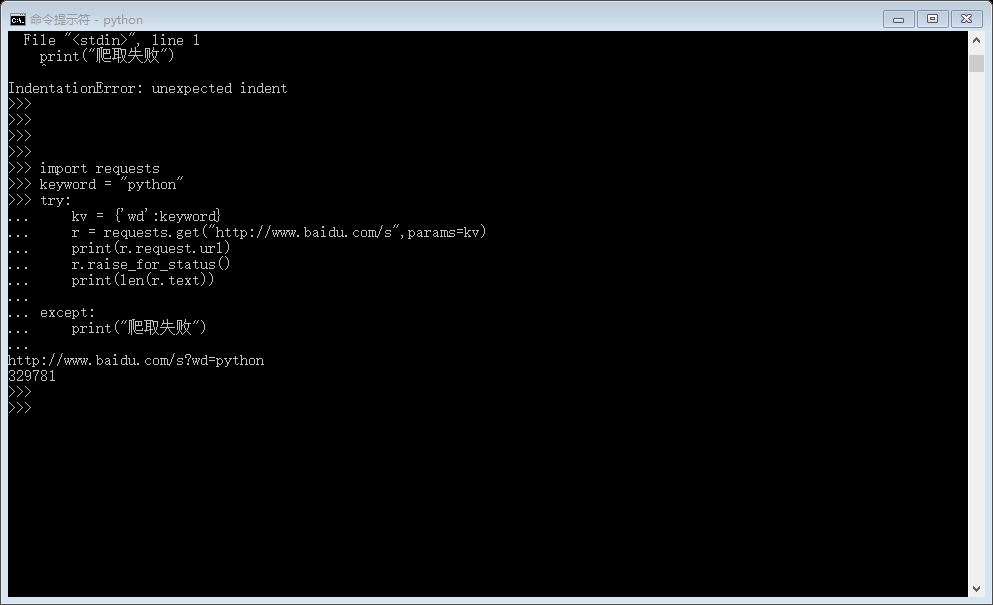
爬取百度关键词查询结果 : 本例关键词为python
import requests
keyword = "python"
try:
kv = {'wd':keyword}
r = requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text)) except:
print("爬取失败")
网络图片,视频等二进制文件的爬取和保存:
import requests
import os url = "http://image.nationalgeographic.com.cn/2017/0819/20170819021922613.jpg"
root = "f://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root): #处理根目录是否存在问题
os.mkdir(root)
if not os.path.exists(path): #处理文件是否存在问题
kv = { 'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers = kv) r.status_code
with open(path,'wb') as f:
f.write(r.content)#r.content为二进制形式
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
Ip地址归属地的查询:
import requests
url = "http://m.ip138.com/ip.asp?ip="
try:
r=requests.get(url+'202.204.80.112')
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")

python网络爬虫与信息提取 学习笔记day2的更多相关文章
- python网络爬虫与信息提取 学习笔记day3
Day3: 只需两行代码解析html或xml信息 具体代码实现:day3_1 注意BeautifulSoup的B和S需要大写,因为python大小写敏感 import requests r ...
- python网络爬虫与信息提取 学习笔记day1
Day1: 安装python之后,为其配置requests第三方库,并爬取百度主页内容. 语句解释: r.status_code检测请求的状态码,如果状态码为200,则说明访问成功,否则,则说明访问失 ...
- python 网络爬虫与信息提取 学习笔记day4
正则表达式简介: 简洁表示一组字符串的特征或者模式,在文本处理中十分常用,主要应用于字符串匹配中 1. 通用的字符串表达框架 2. 简洁表达一组字符串的表达式 3. 针对字符串表达简洁和特征思想 ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
随机推荐
- Java虚拟机系列-Java类加载机制
原文:http://www.ityouknow.com/jvm/2017/08/19/class-loading-principle.html 一. 类加载: 1. 将.class文件的二进制数据加载 ...
- 回顾JS Date()对象
突然想写一个日历插件发现Date对象的一些常识快忘光了,复习一下 new Date()返回当前时间 年月日 getFullYear() 返回年份 getMonth() 返回月份(因为从0开始算 所以要 ...
- java或判断优化小技巧
写业务代码的时候,我们经常要做条件判断,有的时候条件判断的或判断长达20多个.reg.equals("1") || reg.equals("2") || reg ...
- Python基础-week01
本节内容摘要:http://www.cnblogs.com/Jame-mei Python介绍 Python是怎么样的语言? Python 2 or 3? 安装 Hello World程序 变量 用户 ...
- Lombok介绍、使用方法和总结
1 Lombok背景介绍 官方介绍如下: Project Lombok makes java a spicier language by adding 'handlers' that know how ...
- Nginx+Tomcat 配置负载均衡集群
一.Hello world 1.前期环境准备 准备两个解压版tomcat,如何同时启动两个tomcat,请看我的另一篇文章<一台机器同时启动多个tomcat>. nginx官网下载解压版n ...
- 利用 mount 指令解决 Read-only file system的问题
利用 mount 指令解决 Read-only file system的问题 在linux系统中创建一个文件提示: /application/report/shiwei # touch test.ct ...
- docker环境下使用xdebug进行断点调试
最近把本地环境切换成了docker的环境,便于快速运行和开发,确实比较给力,但是也遇到了问题,以前的本地xdebug断点调试都用不了,弄了几个小时终于搞定了 docker还是坑多,绕,下面把docke ...
- python(练习实例)
Python 练习实例1 题目:有四个数字:1.2.3.4,能组成多少个互不相同且无重复数字的三位数?各是多少? 我的代码:python 3+ #2017-7-20 list_h = [1,2,3,4 ...
- javaScript设计模式 -- 灵活的javaScript语言
因为好长时间的懒惰和懈怠,好久没有更新文章了,从现在开始我会按时更新一些自己总结的一些知识,和研究的东西,希望能让大家从我这里学到一点点的知识. 本文参考了张荣铭的javascript设计模式一书,算 ...