在生产中部署ML前需要了解的事
在生产中部署ML前需要了解的事
译自:What You Should Know before Deploying ML in Production
MLOps的必要性
MLOps之所以重要,有几个原因。首先,机器学习模型依赖大量数据,科学家和工程师很难持续关注这些数据以及机器学习模型中可调节的不同参数。有时候对机器学习模型的微小变更可能会导致结果大相径庭。此外还需要密切关注模型的功能。特征工程是机器学习生命周期的重要一环并极大影响了模型的准确性。
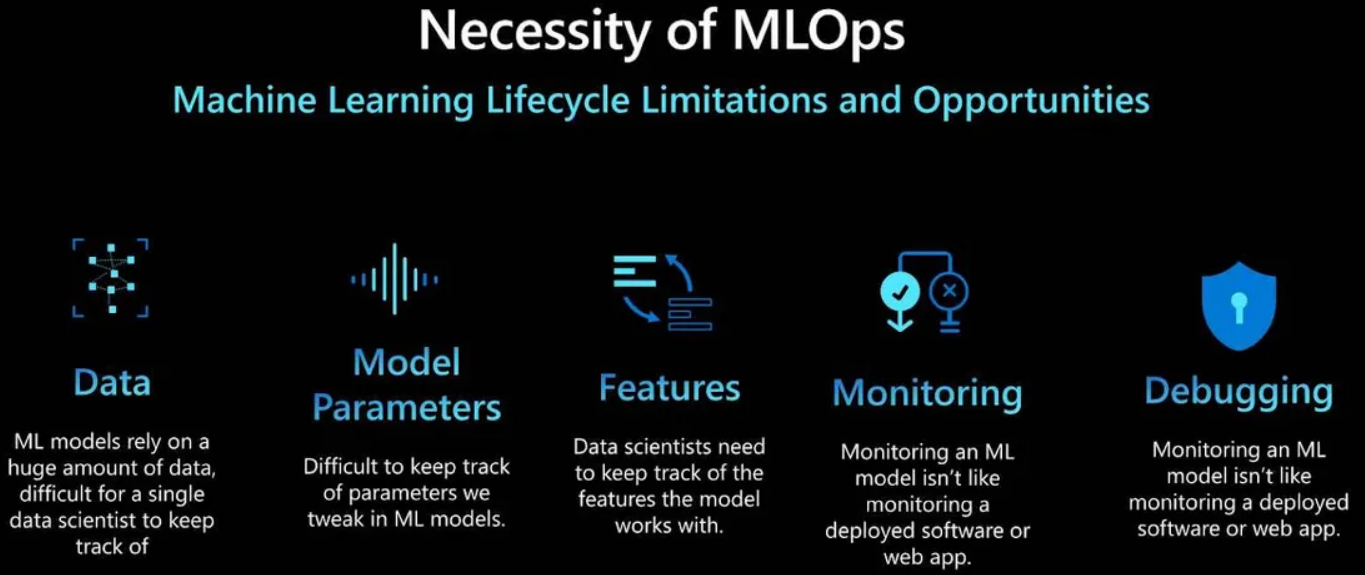
一旦进入生产,就不能像监控其他类型的软件(如web应用)一样监控机器学习模型,且调试机器模型的过程也相对复杂。模型会使用实际数据来生成预测结果,但实际数据可能会随时间变化。
由于数据会发生变化,因此有必要关注模型的性能,必要时需要升级模型。这意味着你不得不密切关注新数据的变化,并确保模型学习的正确性。
下面将讨论在生产环境中部署机器学习模型前应该关注的四个主要方面:MLOps的能力、开源集成、机器学习流水线和MLflow。
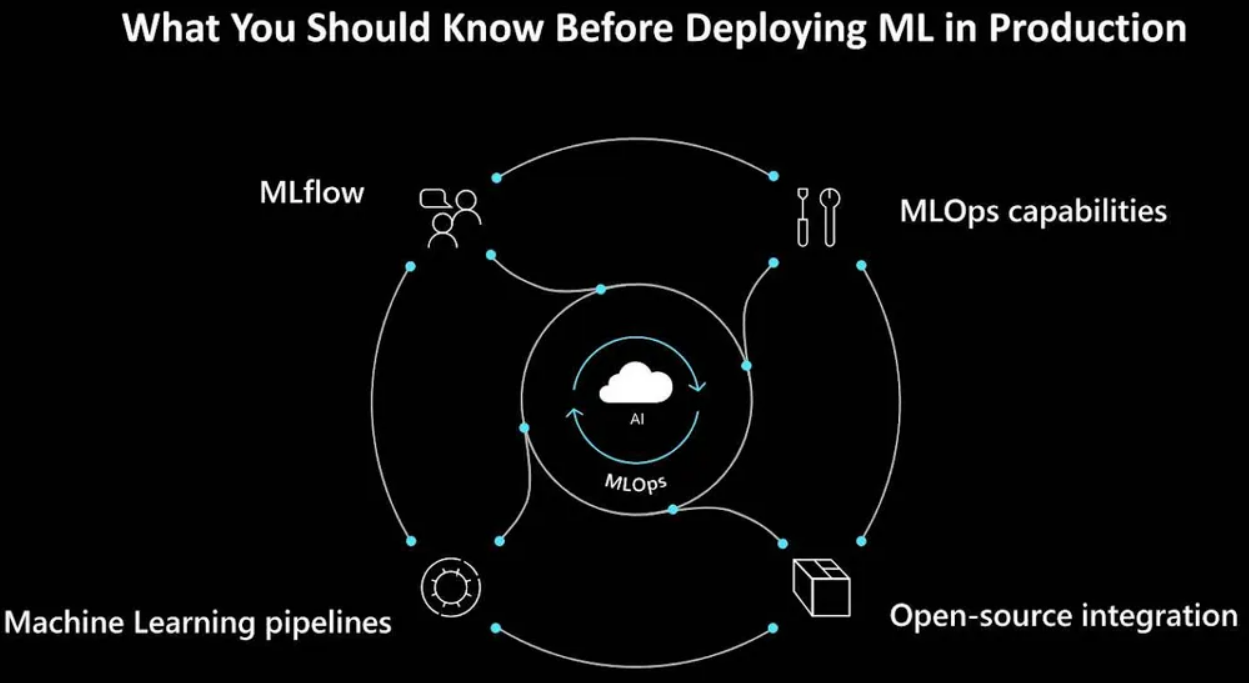
MLOps的能力
在部署到生产环境前可以考虑多种不同的MLOps能力。首先是创建可复制的机器学习流水线的能力。机器学习流水线可以为数据准备、训练和评分过程定义可重用的步骤。这些步骤包括为训练和部署模型创建可重用的软件环境,以及在任何地方注册、打包和部署模型的能力。通过流水线可以频繁更新模型,或与其他AI应用程序和服务一起推出新的模型。
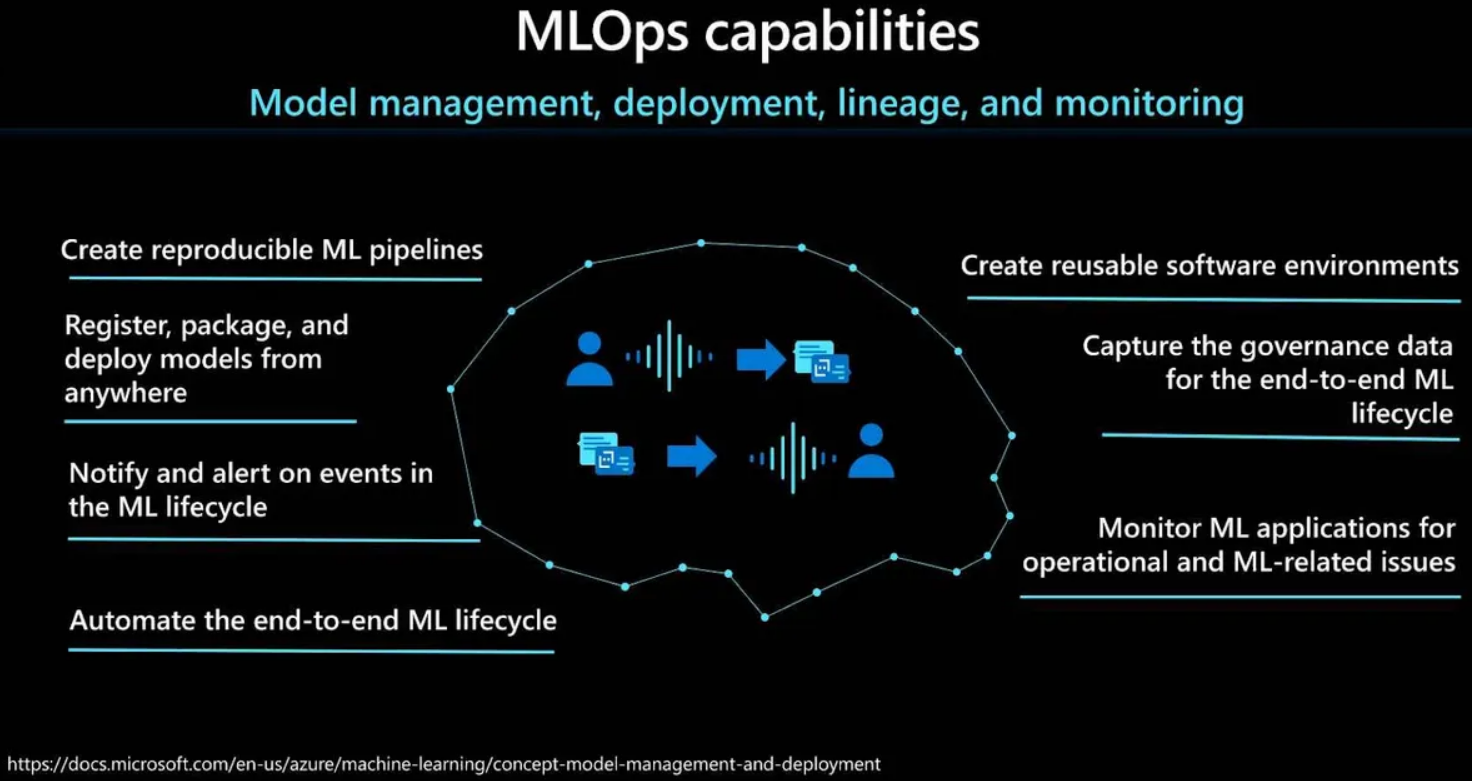
此外还需要关注使用模型和为端到端机器学习生命周期捕获治理数据所需的元数据。在后一种情况下,沿袭信息可以包括,如谁发布了模型,为什么在某个时间点进行了更改,以及在生产中部署或使用了不同的模型。
另一个要点是在机器学习生命周期中基于事件来进行通知和告警。例如,实验完成、注册模型、部署模型以及数据漂移检测等。除此之外,还需要监控机器学习应用的操作和ML相关的问题。这里,数据科学家需要通过比较训练时间和推理时间的模型输来探索特定模型的指标,并在机器学习基础设施上配置监控和告警。
开源集成
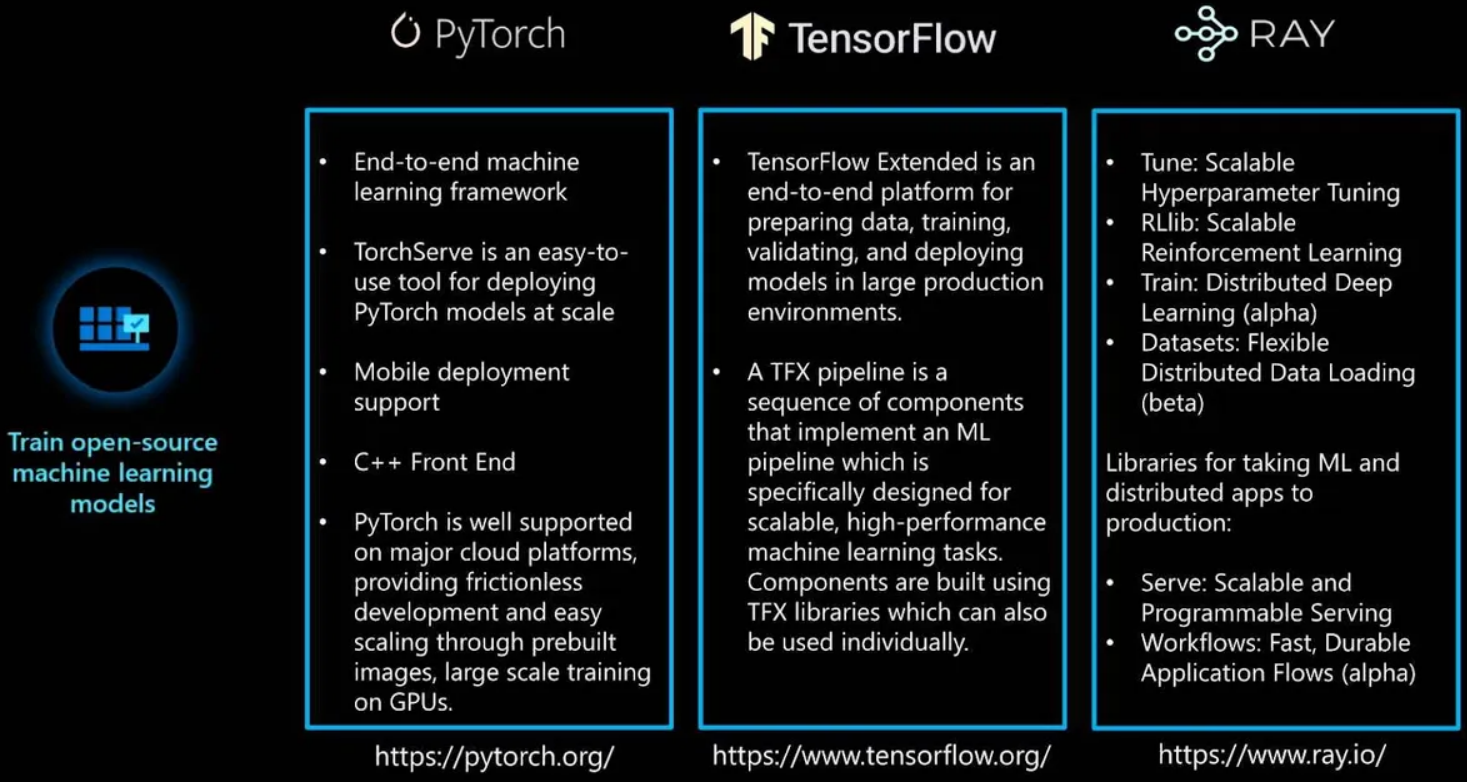
在生产环境中部署机器学习之前应该知道的第二点是开源集成。这里给出了三个非常重要的开源技术。第一个是开源训练框架,非常适合加速机器学习解决方案。第二个是用于可解释和公平模型的开源框架,最后是开源模型部署工具。
这里有三个不同的开源训练框架: PyTorch, TensorFlow 和 RAY。PyTorch 是一个端到端的机器学习框架,它包括TorchServe(一种方便扩展PyTorch模型的部署工具)。PyTorch还支持移动端部署和云平台。PyTorch有一个C++ 前端,它遵循Python前端的设计和体系结构。
TensorFlow 是另一个业界有名的端到端机器学习框架。对于MLOps,它使用了一个名为TensorFlow Extended (TFX) 的特性,这是一个端到端平台,用于在大型生产环境环境中准备数据、训练、校验和部署机器学习模型。一个TFX流水线是一个顺序的组件集,特别适用于可扩展的高性能机器学习任务。
RAY是一个强化学习(RL)框架,它包含几个有用的训练库: Tune, RLlib, Train和Dataset。Tune非常适合超参数调优。RLlib用于训练RL模型。Train用于分布式深度学习。Dataset用于分布式数据加载。RAY还有两个额外的库:Serve 和Workflows,用于将机器学习模型和分布式应用部署到生产环境。
为了创建可解释和公平模型,可以使用两个有用的框架: InterpretML 和Fairlearn。InterpretML是一个结合了几种机器学习可解释性技术的开源库,你可以训练可解释的玻璃盒模型(glassbox models),也可以解释黑盒系统(blackbox systems)。此外,还可以用于理解模型的整体行为,或理解个值预测背后的原因。
Fairlearn是一个Python库,它可以提供评估哪些组受到模型负面影响的指标,并可以使用公平性和准确性指来对比多个模型。它还支持多种算法,用于缓解各种AI 和机器学习任务中的不公平。

第三个开源技术用于模型部署。当使用不同的框架和工具时,需要根据每个框架的要求来部署模型。为了标准化流程,可以使用ONNX格式。
ONNX 是Open Neural Network Exchange的简称。ONNX是一个机器学习模型的开源格式,用于支持不同框架的互操作性。这意味着,你可以使用某个机器学习框架(如PyTorch、TensorFlow或RAY)训练一个模型,然后在其他框架(如 ML.NET)中将其转换为ONNX格式。
ONNX Runtime (ORT)表示使用一组通用操作符的机器学习模型,这些操作符是机器学习和深度学习模型的构建块,允许模型在不同的硬件和操作系统上运行。ORT优化和加速了机器学习推理,可以实现更快的客户体验以及更低的产品成本。它支持如PyTorch和TensorFlow这样的深入学习框架模型,但也支持经典的机器学习库,如Scikit-learn。
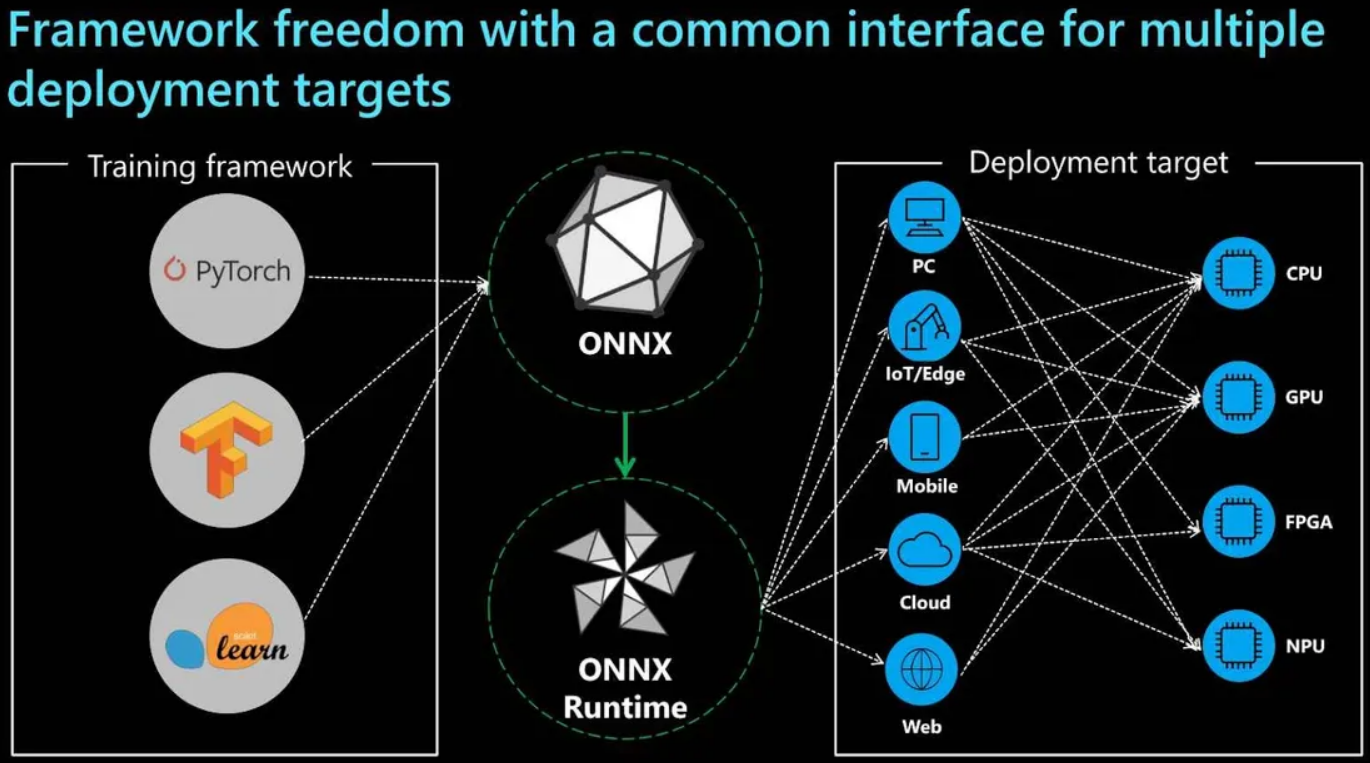
还有很多有名的框架可以支持转换为ONNX格式,如PyTorch内置了导出为ONNX格式,其他工具,如TensorFlow 或Keras则使用独立的安装包来处理转换逻辑。该过程非常直接:首先需要使用一个支持导出为ONNX格式的框架来训练出模型,然后使用ONNX Runtime加载并运行该模型,最后可以使用多种运行时配置或硬件加速器来调节性能。
机器学习流水线
在生产环境中部署机器学习前应该考虑的第三点时如何为机器学习解决方案构建流水线。流水线的第一个任务是数据预处理,包括导入、校验、清理、转换和规范化数据。
接下来,流水线包含训练配置,包括参数、文件路径、日志和报告等。然后以高效且可复用的方式执行实际训练和验证工作。效率可能受自特定的数据子集、不同的硬件、计算资源、分布式处理以及过程监控的影响。最后是部署阶段,包含版本、扩展、资源调配和访问控制。
流水线技术的选择取决于特定的需求,通常分为如下三种场景:模型编排、数据编排或代码或应用编排。每个场景都围绕一个作为该技术主要用户的角色以及一个标准流水线(这是典型的工作流)。
在模型编排场景中,重要角色是数据科学家。这种场景下的标准流水线涉及从数据到模型。在开源技术选项方面,可以选择Kubeflow Pipelines。
对于数据编排场景,主要角色是数据科学家,标准流水线涉及从数据到数据。这种场景下通常会使用Apache Airflow。
最后一个是代码和应用编排。主要的角色是应用开发人员。标准流水线涉及从代码+模型到服务。通常选择的开源解决方案是Jenkins。
下图展示了在Azure Machine Learning上创建流水线的过程。对于每一个阶段,Azure Machine Learning 服务都会计算所需的硬件计算资源、OS资源(如Docker镜像)、软件资源(如 Conda)和数据输入。
而后服务会确定步骤之间的依赖关系,从而生成一个动态执行图。当执行动态执行图中的步骤时,服务会配置必要的硬件和软件环境。该步骤还会向其包含的实验对象发送日志记录和监控信息。当步骤结束时,其输出会作为下一步骤的输入。最后,确定并分离不需要的资源。
MLflow
最后一个在生产环境中部署机器学习前应该考虑的工具是MLlow。 MLflow 是一个管理端到端机器学习生命周期的开源平台。包含四个生命周期中非常重要的主要组件。
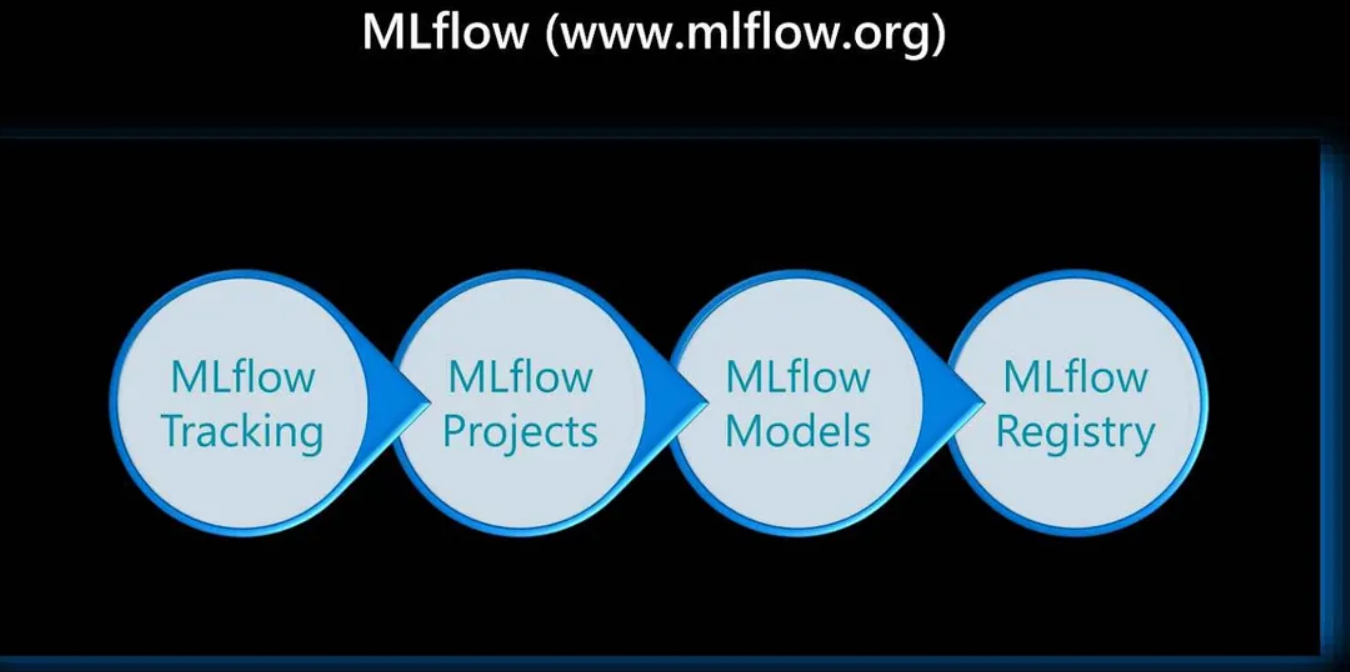
第一个是 MLflow Tracking,它会对实验进行跟踪,记录并比较参数和结果。MLflow可以将执行过程记录到一个本地文件和兼容 SQLAlchemy的数据库或远程追踪服务器中。可以使用Python、R、Java或REST API来记录执行数据。MLflow允许分组运行,用于比较执行过程,也可以用于比较用于处理特定任务的执行过程。
下一个是MLflow Projects,它可以以一种可重用的形式将ML代码打包到项目中,以便与其他数据科学家共享代码或将代码传输到生产环境。它根据约定指定了打包数据科学代码的格式。此外,该组件还包含一个API以及命令行工具,用于执行项目,使其能够将多个项目链接到工作流中。
下一个是MLflow Models,它管理和部署从各种机器学习库到模型服务和推理平台的模型。通过使用标准格式来打包机器学习模型,使其能够适用于多种下游工具。例如,通过REST API或基于Apache Spark的批量推断来提供实时服务。每个模型都是一个包含任意文件的目录,且根目录中包含一个模型文件,该目录可以定义多种模型查看风格。
最后一个组件是 MLflow Registry,它是一个集中式的模型存储、一组APIs和以协作的方式管理一个MLflow模型的完整生命周期的UI。它提供了模型沿袭、模型版本控制、阶段转换和注释。如果你正在寻找一个集中的模型存储和一组不同的API,以便管理机器学习模型的整个生命周期,那么可以选择Registry。
总结
这四个方面:MLOps能力、开源集成、机器学习流水线和MLflow可以帮助创建一个简单且可重复的流程,方便在生产中部署机器学习。这使数据科学家能够快速、轻松地使用不同的模型和框架进行实验。此外,通过改进生产的机器学习系统操作流程,使你能够在实际数据随时间变化时快速更新模型,从而将限制转化为机会。
在生产中部署ML前需要了解的事的更多相关文章
- Git 还没push 前可以做的事(转)
Git 版本控制系統(3) 還沒 push 前可以做的事 转载:http://ihower.tw/blog/archives/2622 這一集要講的是:還沒 push 前可以做的壞事,也就是 re ...
- 项目测试环境自动化部署[jenkins前后端配置、Nginx配置]
持续部署:关注点在于项目功能部署到服务器后可以正常运行,为下一步测试环节或最终用户正式使用做准备.(问题点:一个环节有问题,其他环节跟着有问题) 持续集成:关注点是在于尽早发现项目整体运行问题,尽早解 ...
- win2008服务器部署系统前需要做的一些工作
一.打开.net framework及IIS管理器 win2008系统自带是有.net framework3.5的,但是默认该功能是没有开启的,需要手动开启(和win7一样).点击控制面板->程 ...
- 第四章 部署K8s前准备工作
一.主机准备 1.硬件 准备5台2C/2g/50g虚拟机: Centos7.6系统 2.集群规划 使用10.4.7.0/24网络 IP 主机名 10.4.7.11 hdss7-11.host.com ...
- Spring boot中最大连接数、最大线程数与最大等待数在生产中的异常场景
在上周三下午时,客户.业务和测试人员同时反溃生产环境登录进入不了系统,我亲自测试时,第一次登录进去了,待退出后再登录时,复现了客户的问题,场景像是请求连接被拒绝了,分析后判断是spring boot的 ...
- oneinstack一键部署linux生产环境那点事(ubuntu)
http://oneinstack.com/install/ (1)将oneinstack-full.tar.gz最新版安装文件上传至/usr/local/下 (2)解压tar xzvf oneins ...
- salesforce零基础学习(一百一十七)salesforce部署方式及适用场景
本篇参考:https://architect.salesforce.com/decision-guides/migrate-change https://developer.salesforce.co ...
- 通过带Flask的REST API在Python中部署PyTorch
在本教程中,我们将使用Flask来部署PyTorch模型,并用讲解用于模型推断的 REST API.特别是,我们将部署一个预训练的DenseNet 121模 型来检测图像. 备注: 可在GitHub上 ...
- Kubernetes容器化工具Kind实践部署Kubernetes v1.18.x 版本, 发布WordPress和MySQL
Kind 介绍 Kind是Kubernetes In Docker的缩写,顾名思义是使用Docker容器作为Node并将Kubernetes部署至其中的一个工具.官方文档中也把Kind作为一种本地集群 ...
随机推荐
- Windows中Nginx配置nginx.conf不生效解决方法
转:https://lucifer.blog.csdn.net/article/details/83860644?utm_medium=distribute.pc_relevant.none-task ...
- 时序数据库influxDB介绍
https://www.jianshu.com/p/68c471bf5533 https://www.cnblogs.com/wzbk/p/10569683.html
- Codeforces Round #133 (Div. 2), A.【据图推公式】 B.【思维+简单dfs】
Problem - 216A - Codeforces Problem - B - Codeforces A Tiling with Hexagons 题意: 给出a b c ,求里面有多少个六边形 ...
- Dockerfile 中对常用命令详解
说明 Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明. 在Dockerfile 中命令书写对先后顺序及表示其执行对顺序,在书写时需注意. 约定 命令不 ...
- Unity实现A*寻路算法学习2.0
二叉树存储路径节点 1.0中虽然实现了寻路的算法,但是使用List<>来保存节点性能并不够强 寻路算法学习1.0在这里:https://www.cnblogs.com/AlphaIcaru ...
- StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程)
@ 目录 StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程) 一.下载ELK的安装包上传并解压 1.Elasticsearch下载 2.Logstash下载 3.Kibana ...
- 引入『客户端缓存』,Redis6算是把缓存玩明白了…
原创:微信公众号 码农参上,欢迎分享,转载请保留出处. 哈喽大家好啊,我是没更新就是在家忙着带娃的Hydra. 在前面介绍两级缓存的文章中,我们总共给出了4种实现方案,在项目中整合了本地缓存Caffe ...
- kill -9 进程杀不掉,怎么办?
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 用ps和grep命令寻找僵尸进程 ps -A -ostat,ppid,pid,cmd | gr ...
- 干货 | 手把手教你搭建一套OpenStack云平台
1 前言 今天我们为一位朋友搭建一套OpenStack云平台. 我们使用Kolla部署stein版本的OpenStack云平台. kolla是用于自动化部署OpenStack的一个项目,它基于dock ...
- windows下载安装JDK8
一 .下载链接 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 根据自己的电脑安 ...