salesforce零基础学习(一百一十七)salesforce部署方式及适用场景
本篇参考:https://architect.salesforce.com/decision-guides/migrate-change
https://developer.salesforce.com/docs/atlas.en-us.sfdx_dev.meta/sfdx_dev/sfdx_dev_dev2gp.htm
很偶然看到了这篇文章,一下子就被吸引住了。尽管项目中的一些部署方式有用到过,考SF认证也有很多相关的靠题,也能二二三三的讲出点不同场景以及优缺点,但总不是很全面的了解,所以基于这篇进行一下翻译,也顺便让自己学习一下了。英语好的,直接看原文即可。
背景: 我们做项目不管是国内项目还是对日欧美项目,除了开发以外,少不了的要部署。可能针对一个字段的创建,直接生产创建,然后手动配置了FLS,或者部署一个 report type / report基于change set,又或者需要删除一个 apex class,通过 metadata api,比如使用ant,又或者是一个一两年的大型项目,使用 CI + CD的metadata api 部署。当然国内项目大部分都是二次开发为主,如果你是一个ISV,可能还要用到 managed package等等,那什么时候用到哪种部署方式呢? 作为新手可能想着是项目规定的,如果作为老手的话,还是可以基于官方的 best practice来进行一些参考,按照官方的建议,有七种不同的部署选项,从简单但不太可扩展的技术到更复杂但高度可扩展的方法依次是:
1. Manual Changes in Production
2. Change Sets
3. Metadata API: Direct Deployments
4. Metadata API: Deployment with Source Control + Continuous Integration
5. Org Dependent Packages
6. Unlocked Packaged
7. Managed Packages
下图中从左到右代表着部署方式更加的可扩展性。可扩展性意味着支持:
- 更多变化的更大部署
- 更多的团队或更大的团队同时处理更多的项目
- 更多的测试和自动化,实现更频繁的部署
- 更加一致和可靠的部署

当然,在实际的项目中或者工作中,并不一定要求更高的可扩展性,因为需要可扩展性,一定需要牺牲或者需要付出一些东西,比如:
- 放弃一些简单性,但获得更多可扩展性
- 需要提高所需的技术技能水平
- 将更多的时间花在流程上,而不是产品上
至少对于目前的场景来说, change set / metadata api / CI & CD metadata api可以搞定大部分项目的需要。
以下例举的是不同的部署模式所支持和不支持的选项。
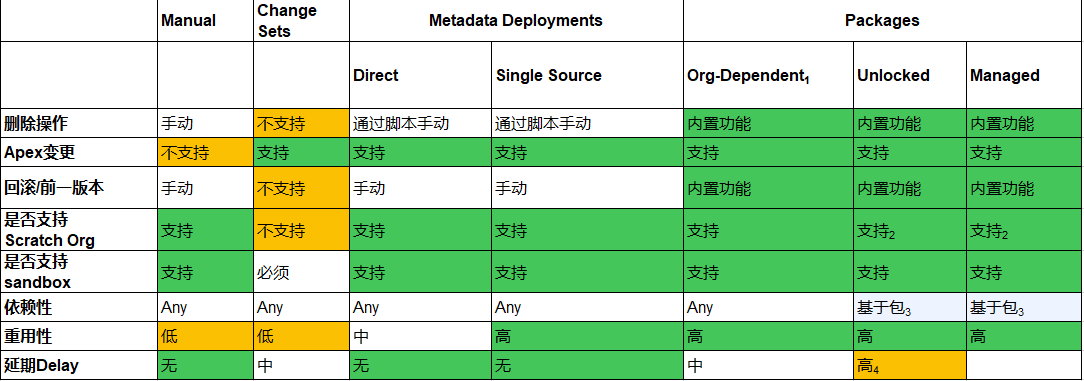
1.Org-dependent package是Winter '21 release发布的测试版。
2.即使不使用scratch org创建包,它也必须能够部署到scratch org,否则包创建将失败。
3.每个依赖项必须在包中或另一个包中。
4.可以通过命令上的标志跳过包版本创建时的验证,以减少包构建时间。
后续内容是针对不同的场景下,每种部署方式的限制,优缺点(何时选择,何时不选择)以及如何减轻部署的风险。
一. Manual Change In Production
1. 限制: 最大的限制莫过于没法直接更改 apex class,实际项目中很少会遇见不更改 apex class的项目,所以如果有 apex class相关的更改,则忽略此种方式。
2. 什么场景下选择此种部署方式(优点):以下场景可以参考。
- 针对一些类型的 metadata type,目前只支持 manual deploy.
- 在业务的敏捷上是一种可以接受并且风险小的metadata, 比如 Report / ListView等。
- 针对小的变动,部署会特别快。比如要紧急关闭一个validation rule,或者针对一些权限的分析,可能需要临时创建 permission set测试一下权限,测试完成以后会删除这种。
- 如果在salesforce上线前第一次设置,在风险较低的情况下,并且在用户访问系统之前,有一个认真的测试计划,这将非常方便。比如生产环境先启用 enable account team或者 enable community等设置可以在项目最开始的时候,生产环境手动配置上。
3. 什么场景下不建议选择此种部署方式。以下场景可以参考。
- 许多类型的更改都是极其危险的:比如validation rule的条件,大于号写成了小于号。AND写成了OR,直接在生产环境操作这种都是极其危险的。
- 生产的metadata change很难进行测试。
- 对于一个团队来说不适合于扩展。比如平台有 sales cloud以及 service cloud并且两个cloud由两个团队来开发,两个团队都会用到 person account表,针对字段以及其他共用的情况就很容易出现冲突情况。
- 很难撤回或者放弃一些change。
- 当有客户在系统上时,很难部署大量的、复杂的更改。
4. 减轻手动更改可能面临的风险:如果有只能手动完成的更改,则可以通过首先在sandbox中完成更改的步骤,测试结果,然后在生产中重复相同的一系列步骤来验证这些更改。总体来说就是在sandbox多测试。
二. Change Set
此种部署方式应该是小型项目中经常遇见的方式。
1. 限制:
- change set只能和 sandbox一起搭配使用,并且sandbox只能从production org来创建。
- 可以单击View/Add Dependencies按钮来查找依赖项,但它可能无法捕获所有内容。举个例子,我们有一个Apex类,该类对其测试类没有正式的依赖关系,但我们在部署时必须具有测试覆盖率,因此如果不包含测试,则某个更改集将无法部署。在点击这个按钮时,这个测试类不会被自动捕获。
- 最多只能展示10000个文件。(由复选框表示的项目)
- 有时,sandbox位于与目标组织不同的版本上。当这种情况发生时,某些metadata类型无法部署.
- changeset没法删除任何metadata或配置。
2. 什么场景下选择此种部署方式(优点):以下场景可以参考。
- 它已经存在/运行了很长时间,所以大多数人都很熟悉它。
- 基于UI操作,admin操作友好。
- 与手动执行的更改不同,change set的更改同时影响生产,没有时延问题。
- 验证和部署时间可以有区别。比如周五在大家都在上班时验证好,周末进行部署操作。
- 验证/部署失败时,可以克隆 change set从而减少很多时间。
- 如果通过manual change做了一些紧急的变更,可以通过 change set同步到 sandbox。
- 方便追踪这些change 如何在不同的环境中的移动。
- 可以有权限来设置谁可以创建和部署 changeset。
3. 什么场景下不建议选择此种部署方式。以下场景可以参考。
- 在构建过程中,您必须跟踪您的更改。针对metadata,我们希望tracking什么时候谁更改。
- 如果我们在部署时,需要dev->sit->uat->prd,那么所有的 changeset都需要重新打包。
- 不是所有的 metadata都支持change set部署,比如 community相关,对 changeset支持就基本不可以。
- changeset打包发送是有时延的,从A sandbox到B sandbox不是实时就upload成功,可能需要几分钟或者几小时,不可保证。
4. 基于changeset部署转向到基于 metadata 部署:如果你的团队一直在使用change set,但正在考虑转移到基于源代码的部署,则可以通过Salesforce CLI检索change set。然后,一个CLI用户或脚本可以使用CLI命令通过名字检索change set并提取source。在这种情况下,我们便不使用 changeset方式进行部署,而是基于 metadata deploy方式。
三. Metadata API: Direct Deployments
Salesforce Metadata API 允许我们迁移metadata。当然我们实际场景中很少直接用 Metadata API,而是使用Ant脚本或者CLI。通过基于metadata部署方式,我们只需要针对我们想要部署的资源来添加或者修改即可。部署也只针对我们整理的资源,其他不在package.xml或者不在整理中的资源不会做任何操作。
1. 限制:
- 与change set类似,每个事务只允许最多10000个文件。
- 文件的总解压缩大小不能超过400MB。
- metadata api 不支持所有的metadata类型。
2. 什么场景下选择此种部署方式(优点):以下场景可以参考。
- 部署可以重复使用。资源可以重复部署使用,比如 dev->sit->uat,就可以使用同一个包进行部署
- 可以删除资源,比如删除 apex class
- 可以部署settings类型。举个例子,有些功能在PROD没有启用,你可以通过metadata部署方式进行启用和配置。
- 可脚本化。可以创建可重复的部署脚本,以确保这些项在部署之前和/或之后处于正确的状态。
3. 什么场景下不建议选择此种部署方式。以下场景可以参考。
- 很难进行追踪。比如我们想回滚到什么样的节点,我们不清楚这个期间谁进行过什么样的部署。
- 很难进行控制。多个开发人员如果部署,可能造成获取的资源不同的版本,容易进行覆盖操作。
4. 减轻手动更改可能面临的风险:部署人员减少,找专人进行部署,当然这个在减轻风险的情况下,也可能出现瓶颈问题。
四. Metadata API: Deployment With Source Control And Continuous Integration
这种部署方式应该是作为开发人员最舒服的方式,程序员只需要关注自己的功能做好,然后创建自己的分支,上传自己的资源,merge到主分支即可。部署人员通过CI/CD的一些工具(Jenkins,dockers等)即可进行持续继承持续部署。
1. 限制(和第三个相同):
- 与change set类似,每个事务只允许最多10000个文件。
- 文件的总解压缩大小不能超过400MB。
- metadata api 不支持所有的metadata类型。
2. 什么场景下选择此种部署方式(优点):以下场景可以参考。
- 源码控制是一个已解决的问题。许多公司已经为源代码控制和CI建立了高质量的工具。
- 开发人员知道它。这是Salesforce之外的开发者的默认操作模式。
- 支持自动化。从GitHub行动中进行部署,或者让你的CI系统订阅webhooks来进行这些行动。除了部署,这还允许测试自动化、代码分析和linter/styling来检查。
- 对于大项目来说,可扩展性更好。
- 分支有助于多个项目同时进行。即使在一个小团队中,你也可能同时有小功能、紧急情况、发布检查、错误修复、实验和大型项目的混合。把它们组织起来有助于你的团队更快地工作。
- 分支允许部分部署。假设多个分支情况下,如果测试人员只测试完成部分功能,可以支持部分功能对应的分支部署。
3. 什么场景下不建议选择此种部署方式。以下场景可以参考。
- 你的团队自定义内容很多的metadata type不支持metadata api部署或者部署的不是很好。
- 对你的团队来说,源代码控制是一个未知的领域。
- 公司的发布通常是大型的,而且不频繁。
- 没有能力投入时间来建立这种工具。
以下内容讲的是基于包的部署,那先来说一下包(package)的背景。
Salesforce自AppExchange推出以来就一直使用软件包,大多数管理员都熟悉在环境中安装的各种 managed package,比如conga什么的。第一代管理包主要是为这种ISV使用情况设计的。管理包的限制性很强;一旦你发布了一个包,有很多改变就不再被允许,因为开发者无法知道客户组织可能建立了什么依赖关系。也有一些客户使用非管理型软件包,这些软件包是不可能升级的。
第二代软件包是从源代码创建的,而不是从一个org的内容中创建的。现在的官方文档中,除了特意说明是第一代管理包之外,其他的说的package都是二代包(second-generation package),官方也建议除历史情况,否则都使用二代包。针对二代包的情况下,我们常说的有两种: unlocked & managed。接下来进入包部署的这几种情况。
包的基础知识
包的概念是有一个是有版本的metadata的子集。拥有以下特性
- 你可以升级到一个包的较新版本,或者在某些情况下恢复到以前的版本。
- 你可以干净地卸载一个包,而不需要知道其中的所有内容。
- 你可以从一个包中删除一些元数据,当包被安装时,元数据就会从org中删除。
- 包可以建立在其他包的基础上,并有明确声明的依赖关系。
- 包使得在多个组织间共享代码变得容易。
其他知识如下:
- 当你创建一个软件包版本时,该版本开始处于Beta状态。你可以将软件包安装在Scratch orgs和sandbox中,但不能直接安装在生产环境中。要在生产中部署,你必须首先将软件包提升到发布状态。通过控制这个阶段,软件包可以方便地测试以及受控的发布。
五. Org-Dependent Packages
Org-dependent 包在技术上是在创建时带有特殊标志(-skipvalidation)的unlocked package。它们依赖你的组织中的某些东西。比如你的 package的资源有一个flow,flow引用了自定义的notification type,这个 notifycation type还不支持打包。这种场景下这个包部署在你的环境中,只能乐观的认为你的环境存在 notification type。如果不存在,则抛出自定义异常。
1. 限制:
- 其他的package不能依赖于 org-dependent package;
- org-dependent package 不能依赖于其他的package。
2. 什么场景下选择此种部署方式(优点):以下场景可以参考。
- 你想要创建一个 package,这个package依赖于没有package支持的东西。
- 你在org中有一些元数据,还没有准备好被打包。例如,它有一些纠缠不清的循环依赖关系,使得这个过程很困难。
- 你想要一些packaging的好处,但却不能控制你所依赖的元数据(例如,它被你公司的另一个团队所拥有)
- 你想要一些打包的好处,但你不能将你现有的元数据模块化
- 你可以在现有的未打包的元数据上进行部署
- 你无法创建一个支持你的包的内容的scratch org,即使它没有外部依赖性。因为依赖于org的包跳过了在scratch org中验证包的步骤,你可以用它们来解决这个限制。
3. 什么场景下不建议选择此种部署方式。以下场景可以参考。
- 如果你的软件包可以包含/声明所有的依赖关系,那么最好选择unlocked package。你可以避免部署时出现意外的错误。
- 你希望能够将软件包部署到一个scratch org。例如,你有使用scratch orgs的自动CI测试。Org-dependent 的包必须进入某种类型的sandbox,在那里满足依赖性,这可能需要更长的时间来创建,并且不能立即销毁。
- 所有的包都需要大量的时间来创建、发布和安装。
注: 老实说,项目中还没有用到过 Org-dependent package,感觉这种大部分场景都可以被 unlocked package取代而且unlocked package还很好使用。
六. Unlocked Packages
1. 限制:
- 依赖关系图中的所有东西都必须是可打包的,已打包的,并在依赖关系清单中。
- 你必须能够配置一个 scratch org 来支持你的包所需要的一切。
- 75%的最低Apex测试覆盖率。
2. 什么场景下选择此种部署方式(优点):以下场景可以参考。
- 它提供了你的metadata的一个已知的、良好的状态。
- 你知道metadata在任何时间点的确切状态。该组织有一个软件包版本部署的记录,并且软件包与源控制相联系。
- 包可以被部署到Scratch org进行测试。
- 你可以恢复到以前的版本。
- 你可以在unpackaged 的metadata上进行部署。
3. 什么场景下不建议选择此种部署方式。以下场景可以参考。
- 生产上的metadata change会被新的软件包部署所覆盖。
- 大型重构可能导致你无法升级的情况。
- 所有的包都需要大量的时间来创建、发布和安装
4. 减轻手动更改可能面临的风险:对于打算用于非生产环境的软件包,你可以跳过软件包验证步骤在新窗口打开链接。这加快了打包过程,所以你可以更快部署并获得测试结果。如果你正在使用自动化测试和频繁的构建,这可能是有用的。
七. Managed Packages
Managed Package比Unlocked Package有更多的限制。它们通常是由AppExchange的合作伙伴使用的,他们希望防止客户在设计时没有被依赖的代码或组件上创建依赖关系。
1. 限制:
- 一旦你暴露了一些东西,就很难将其删除(打包时假设可能有你不知道的依赖关系)。
- 你需要一个与你的Dev Hub相关的命名空间,任何引用包的代码都需要在引用中使用该命名空间。
2. 什么场景下选择此种部署方式(优点):以下场景可以参考。
- 你是一个希望在AppExchange上构建和提供打包解决方案的合作伙伴。
- 你正在多个org工作,并正在创建一个用于这些组织的软件包,而且你有一个迫切的需求,即阻止生产中的变化,这不能仅仅通过治理和权限来实现。
- 你有一个迫切的需求来正式确定一个包所暴露的内容,并更好地封装一些内部因素,而这些因素无法通过解锁包的同等能力来满足。
- 你迫切需要访问命名空间,以帮助保持代码的组织性和模块化,这不能仅通过治理和开发标准来实现,并且有足够的工程专业知识来设计增加的复杂性,如LWC跨命名空间操作在新窗口打开链接。
3. 什么场景下不建议选择此种部署方式。以下场景可以参考。
- 你不是AppExchange的合作伙伴,也没有令人信服的理由去使用它们。
- 你不能100%确定元数据如何被重用,并且不想阻止所有的重用。
- 包的功能经常变化或可能需要允许重大的重构。例如,一些用于处理安全或缓存的自定义Apex实用程序可能比密集的业务逻辑更适合。
- 你的团队对如何为包的开发者和用户设计额外的命名空间相关的复杂性没有绝对把握。这在使用动态代码或配置的地方尤其如此。
- 所有的包都需要大量的时间来创建、发布和安装。
总结:上述内容为SF官方整理的一些部署方式以及这些部署方式的适用场景以及不适用场景。文中后续还有很多其他知识的介绍,感兴趣的小伙伴可以自行查看。我们实际项目中,可能manual / changeset/ metadata部署使用的较多。基于 package的话 unlocked package偶尔也会使用。其他两种目前本人还没有使用过,当然好的部署模式不如好的部署习惯。找一个自己最擅长的,最不出错的更佳。篇中有错误地方欢迎指出,有问题欢迎留言。
salesforce零基础学习(一百一十七)salesforce部署方式及适用场景的更多相关文章
- salesforce零基础学习(八十七)Apex 中Picklist类型通过Control 字段值获取Dependent List 值
注:本篇解决方案内容实现转自:http://mysalesforceescapade.blogspot.com/2015/03/getting-dependent-picklist-values-fr ...
- salesforce零基础学习(九十七)Big Object
本篇参考: https://developer.salesforce.com/docs/atlas.en-us.224.0.bigobjects.meta/bigobjects/async_query ...
- salesforce 零基础学习(四十七) 数据加密简单介绍
对于一个项目来说,除了稳定性以及健壮性以外,还需要有较好的安全性,此篇博客简单描述salesforce中关于安全性的一点小知识,特别感谢公司中的nate大神和鹏哥让我学到了新得知识. 项目简单背景: ...
- salesforce 零基础学习(二十七)VF页面等待(loading)效果制作
进行查询的情况下,显示友好的等待效果可以让用户更好的了解目前的状态以及减少用户消极的等待,例如下图所示. VF提供了<apex:actionStatus>标签,,此标签用于显示一个AJAX ...
- salesforce 零基础学习(六十七)SingleEmailMessage 那点事
在salesforce开发中,发送邮件是一个很常见的功能.比如在进入审批流以后的通过和拒绝的操作需要发送邮件给记录的owner,和其他系统交互以后更改了某些状态通知相关的User或者Contact等等 ...
- salesforce零基础学习(九十七)Event / Task 针对WhoId的浅谈
我们在Sales Cloud中经常会创建顾客,如果针对TO C业务,会启用个人顾客,比如针对车企行业,有一些场景是需要卖给个人的,而不只是企业采购.当通过打电话或者其他的场景有潜在客户并且转换成客户以 ...
- salesforce 零基础学习(三十七) DML及Database方法简单描述
在apex中通过soql查询可以使用两种方式,使用DML语句或者使用Database的方法. 使用DML语句和使用Database类的方法对于我们来说用的都很多,并且都很常见.对于数据库常见的操作:增 ...
- salesforce 零基础学习(五十七)Test 类中创建TestUser帮助类
我们写Test Class的时候往往都需要指定一个uesr去run test method. TestUserHelper类如下: public class TestUserHelper { publ ...
- salesforce零基础学习(七十七)队列的实现以及应用
队列和栈简单的区别为栈是后进先出,队列是先进先出.队列也是特殊的线性表,所以队列也分为顺序存储结构和链式存储结构.本篇主要描述顺序存储结构. 我们先假定一个队列里有5个元素,当我们添加新元素时,添加到 ...
- salesforce零基础学习(八十二)审批邮件获取最终审批人和审批意见
项目中,审批操作无处不在.配置审批流时,我们有时候会用到queue,related user设置当前步骤的审批人,审批人可以一个或者多个.当审批人有多个时,邮件中获取当前记录的审批人和审批意见就不能随 ...
随机推荐
- 10.5 详解Android Studio项目结构
Android项目的结构很复杂,并不像HTML项目,最简单的直接一个HTML文件就行了,相信学完上一节的同学就明白,哪怕是一个HelloWorld这样一个项目的文件可能都有几十个,所以我们需要搞清楚, ...
- Min_25 筛与杜教筛
杜教筛 \(\) 是 \(\) 的前缀和,\(\), \(\) 同理. 假设 \( × = ℎ\) ,并且 \(, \) 易求出,\(\) 难求出. 那么 \[H () = \sum_{ \cdot ...
- 抓到 Netty 一个隐藏很深的内存泄露 Bug | 详解 Recycler 对象池的精妙设计与实现
欢迎关注公众号:bin的技术小屋,如果大家在看文章的时候发现图片加载不了,可以到公众号查看原文 本系列Netty源码解析文章基于 4.1.56.Final版本 最近在 Review Netty 代码的 ...
- 临近梯度下降算法(Proximal Gradient Method)的推导以及优势
邻近梯度下降法 对于无约束凸优化问题,当目标函数可微时,可以采用梯度下降法求解:当目标函数不可微时,可以采用次梯度下降法求解:当目标函数中同时包含可微项与不可微项时,常采用邻近梯度下降法求解.上述三种 ...
- Linux操作系统(2):组管理和权限管理
组管理和权限管理 Outline 1.查看文件所有者:ls -ahl 2.更改文件或目录权限命令:chmod 3.更改文件或目录所有者命令:chown 4.更改文件或目录所属组命令:chgrp 1)组 ...
- CMU15445 (Fall 2019) 之 Project#3 - Query Execution 详解
前言 经过前面两个实验的铺垫,终于到了给数据库系统添加执行查询计划功能的时候了.给定一条 SQL 语句,我们可以将其中的操作符组织为一棵树,树中的每一个父节点都能从子节点获取 tuple 并处理成操作 ...
- 从零开始完整开发基于websocket的在线对弈游戏【五子棋】,只用几十行代码完成全部逻辑。
五子棋是规则简单明了的策略型游戏,先形成五子连线者获胜.本课程习作采用两人在线对弈的方式进行比赛,拿着手机在上下班路上玩特别合适. 整个过程在众触低代码应用平台进行,使用表达式描述游戏逻辑(高度简化版 ...
- Kubernetes组件介绍
一.api-server 基本概念 该端口默认值为6443,可通过启动参数"--secure-port"的值来修改默认值. 默认IP地址为非本地(Non-Localhost)网 ...
- ArrayList的操作和对象数组
ArrayList是List接口的一个实现类,它是程序中最常见的一种集合. ArrayList内部的数据存储结构时候数组形式,在增加或删除指定位置的元素时,会创建新的数组,效率比较低,因此不适合做大量 ...
- Bika LIMS 开源LIMS集—— SENAITE的使用(分析/测试、方法)
分析/测试项目分类(Test Category) 定义检测项目的分类,例如理化检测.微生物检测,或者按样品的维度定义,例如食品检测.水质检测等. 分析方法(Test Method) 定义实验室分析方法 ...