HashMap和Hashtable以及ConcurrentHashMap的区别
HashMap和Hashtable的区别
何为HashMap
HashMap是在JDK1.2中引入的Map的实现类。
HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
其次,HashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
如果不理解线程安全,可以看看我这篇文章:Java并发编程之多线程
HashMap 实现了**Serializable接口,因此它支持序列化**,实现了Cloneable接口,能被克隆。
HashMap中key和value都允许为null。key为null的键值对永远都放在以table[0]为头结点的链表中。
何为Hashtable
Hashtable同样也是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
也就是说,这两个东西大部分时相同的。
Hashtable与HashMap的不同
首先,从上面可以得出,线程安全是不同的。
- HashMap线程不安全,HashTable线程安全。
- 包含的contains方法不同,HashMap是没有contains方法的。
- Hashmap是允许key和value为null值的。
- 计算hash值方式不同。
- .扩容方式不同。
- 解决hash冲突方式不同。
- HashMap是继承自AbstractMap类,而Hashtable是继承自Dictionary类。
- 对外提供的接口不同,Hashtable比HashMap多提供了elements() 和contains() 两个方法。
如果你需要具体详细的了解不同,可以前往浏览器获取详细区别与原理。
ConcurrentHashMap作用
看看下面我箭头指的地方。

因为HashMap是线程不安全的,虽然Hashtable是线程安全的,可是他是一个被舍弃的类,既然淘汰了,那我们就基本不用了。
那什么东西可以替代Hashtable成为HashMap的线程安全类呢?
concurrentHashMap可以用于并发环境,他是支持线程安全的。
线程不安全的HashMap,线程不安全的HashMap,促使了ConcurrentHashMap在JDK5诞生。
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁。那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。 另外,ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
ConcurrentHashMap为了提高本身的并发能力,在内部采用了一个叫做Segment的结构,一个Segment其实就是一个类HashTable的结构,Segment内部维护了一个链表数组。
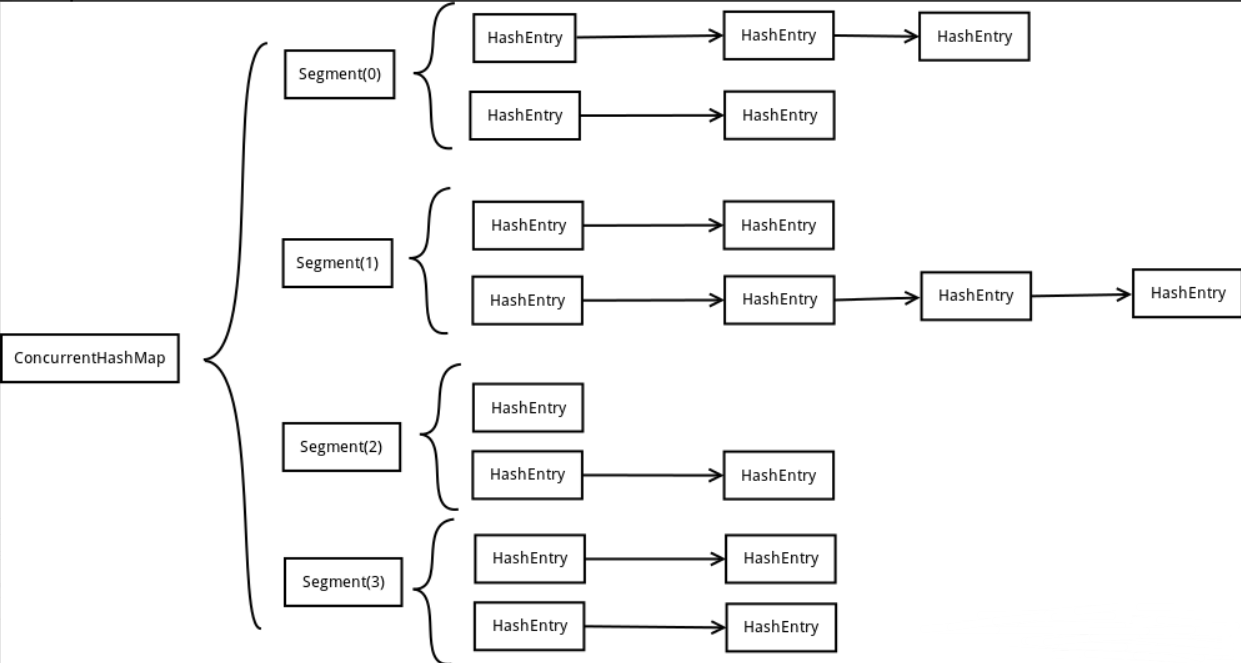
具体了解还是看看其他文章吧,我只是提出有这个东西可以实现并发集合。
ConcurrentHashMap与其他类的区别
与HashMap的区别是什么?
ConcurrentHashMap是HashMap的升级版,HashMap是线程不安全的,而ConcurrentHashMap是线程安全。而其他功能和实现原理和HashMap类似。
与Hashtable的区别是什么?
Hashtable也是线程安全的,但每次要锁住整个结构,并发性低。相比之下,ConcurrentHashMap获取size时才锁整个对象。
Hashtable对get/put/remove都使用了同步操作。ConcurrentHashMap只对put/remove同步。
Hashtable是快速失败的,遍历时改变结构会报错ConcurrentModificationException。ConcurrentHashMap是安全失败,允许并发检索和更新。
然后,在腾讯云社区,我还看到了一个区别,JDK8的ConcurrentHashMap和JDK7的ConcurrentHashMap的区别。
JDK8的ConcurrentHashMap和JDK7的ConcurrentHashMap有什么区别?

其他特性
ConcurrentHashMap是如何保证并发安全的?
JDK7中ConcurrentHashMap是通过ReentrantLock+CAS+分段思想来保证的并发安全的,ConcurrentHashMap的put方法会通过CAS的方式,把一个Segment对象存到Segment数组中,一个Segment内部存在一个HashEntry数组,相当于分段的HashMap,Segment继承了ReentrantLock,每段put开始会加锁。
在JDK7的ConcurrentHashMap中,首先有一个Segment数组,存的是Segment对象,Segment相当于一个小HashMap,Segment内部有一个HashEntry的数组,也有扩容的阈值,同时Segment继承了ReentrantLock类,同时在Segment中还提供了put,get等方法,比如Segment的put方法在一开始就会去加锁,加到锁之后才会把key,value存到Segment中去,然后释放锁。同时在ConcurrentHashMap的put方法中,会通过CAS的方式把一个Segment对象存到Segment数组的某个位置中。同时因为一个Segment内部存在一个HashEntry数组,所以和HashMap对比来看,相当于分段了,每段里面是一个小的HashMap,每段公用一把锁,同时在ConcurrentHashMap的构造方法中是可以设置分段的数量的,叫做并发级别concurrencyLevel.
JDK8中ConcurrentHashMap是通过synchronized+cas来实现了。在JDK8中只有一个数组,就是Node数组,Node就是key,value,hashcode封装出来的对象,和HashMap中的Entry一样,在JDK8中通过对Node数组的某个index位置的元素进行同步,达到该index位置的并发安全。同时内部也利用了CAS对数组的某个位置进行并发安全的赋值。
JDK8中的ConcurrentHashMap为什么使用synchronized来进行加锁?
JDK8中使用synchronized加锁时,是对链表头结点和红黑树根结点来加锁的,而ConcurrentHashMap会保证,数组中某个位置的元素一定是链表的头结点或红黑树的根结点,所以JDK8中的ConcurrentHashMap在对某个桶进行并发安全控制时,只需要使用synchronized对当前那个位置的数组上的元素进行加锁即可,对于每个桶,只有获取到了第一个元素上的锁,才能操作这个桶,不管这个桶是一个链表还是红黑树。
想比于JDK7中使用ReentrantLock来加锁,因为JDK7中使用了分段锁,所以对于一个ConcurrentHashMap对象而言,分了几段就得有几个ReentrantLock对象,表示得有对应的几把锁。
而JDK8中使用synchronized关键字来加锁就会更节省内存,并且jdk也已经对synchronized的底层工作机制进行了优化,效率更好。
JDK7中的ConcurrentHashMap是如何扩容的?
JDK7中的ConcurrentHashMap和JDK7的HashMap的扩容是不太一样的,首先JDK7中也是支持多线程扩容的,原因是,JDK7中的ConcurrentHashMap分段了,每一段叫做Segment对象,每个Segment对象相当于一个HashMap,分段之后,对于ConcurrentHashMap而言,能同时支持多个线程进行操作,前提是这些操作的是不同的Segment,而ConcurrentHashMap中的扩容是仅限于本Segment,也就是对应的小型HashMap进行扩容,所以是可以多线程扩容的。
每个Segment内部的扩容逻辑和HashMap中一样。
JDK8中的ConcurrentHashMap是如何扩容的?
首先,JDK8中是支持多线程扩容的,JDK8中的ConcurrentHashMap不再是分段,或者可以理解为每个桶为一段,在需要扩容时,首先会生成一个双倍大小的数组,生成完数组后,线程就会开始转移元素,在扩容的过程中,如果有其他线程在put,那么这个put线程会帮助去进行元素的转移,虽然叫转移,但是其实是基于原数组上的Node信息去生成一个新的Node的,也就是原数组上的Node不会消失,因为在扩容的过程中,如果有其他线程在get也是可以的。
JDK8中的ConcurrentHashMap是如何扩容的?
CounterCell是JDK8中用来统计ConcurrentHashMap中所有元素个数的,在统计ConcurentHashMap时,不能直接对ConcurrentHashMap对象进行加锁然后再去统计,因为这样会影响ConcurrentHashMap的put等操作的效率,在JDK8的实现中使用了CounterCell+baseCount来辅助进行统计,baseCount是ConcurrentHashMap中的一个属性,某个线程在调用ConcurrentHashMap对象的put操作时,会先通过CAS去修改baseCount的值,如果CAS修改成功,就计数成功,如果CAS修改失败,则会从CounterCell数组中随机选出一个CounterCell对象,然后利用CAS去修改CounterCell对象中的值,因为存在CounterCell数组,所以,当某个线程想要计数时,先尝试通过CAS去修改baseCount的值,如果没有修改成功,则从CounterCell数组中随机取出来一个CounterCell对象进行CAS计数,这样在计数时提高了效率。
所以ConcurrentHashMap在统计元素个数时,就是baseCount加上所有CountCeller中的value值,所得的和就是所有的元素个数。
注:其他特性部分来自于腾讯云+社区
HashMap和Hashtable以及ConcurrentHashMap的区别的更多相关文章
- HashMap、Hashtable和ConcurrentHashMap的区别
HashTable 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相 ...
- HashMap、HashTable、ConcurrentHashMap的区别
一.相关概念 1.Map的概念 javadoc中对Map的解释如下: An objectthat maps keys to values . Amap cannot contain duplicate ...
- HashMap、HashTable与ConcurrentHashMap的区别
1.HashTable与HashMap (1)HashTable和HashMap都实现了Map接口,但是HashTable的实现是基于Dictionary抽象类. (2)在HashMap中,null可 ...
- HashMap,HashTable,ConcurrentHashMap的实现原理及区别
http://youzhixueyuan.com/concurrenthashmap.html 一.哈希表 哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即 ...
- 集合 HashMap 的原理,与 Hashtable、ConcurrentHashMap 的区别
一.HashMap 的原理 1.HashMap简介 简单来讲,HashMap底层是由数组+链表的形式实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表 ...
- HashMap HashTable和ConcurrentHashMap的区别
HashMap和Hashtable都实现了Map接口,其主要的区别有:线程安全性,同步(synchronization),以及效率. HashMap和Hashtable基本上没啥区别,除了HashMa ...
- HashMap、HashTable、ConcurrentHashMap、HashSet区别 线程安全类
HashMap专题:HashMap的实现原理--链表散列 HashTable专题:Hashtable数据存储结构-遍历规则,Hash类型的复杂度为啥都是O(1)-源码分析 Hash,Tree数据结构时 ...
- HashMap,Hashtable,ConcurrentHashMap 和 synchronized Map 的原理和区别
HashMap 是否是线程安全的,如何在线程安全的前提下使用 HashMap,其实也就是HashMap,Hashtable,ConcurrentHashMap 和 synchronized Map 的 ...
- [转帖]HashMap、HashTable、ConcurrentHashMap的原理与区别
HashMap.HashTable.ConcurrentHashMap的原理与区别 http://www.yuanrengu.com/index.php/2017-01-17.html 2017年1月 ...
随机推荐
- 洛谷 P2375 动物园
题目详情 题目描述 近日,园长发现动物园中好吃懒做的动物越来越多了.例如企鹅,只会卖萌向游客要吃的.为了整治动物园的不良风气,让动物们凭自己的真才实学向游客要吃的,园长决定开设算法班,让动物们学习算法 ...
- Windows10运行Cura源代码,搭建环境教程
参考官方文档 https://github.com/Ultimaker/Cura/wiki/Running-Cura-from-Source-on-Windows#python-3810 注意 这些说 ...
- 通过PROFINET网络实现SINAMICS 120的PN IO OPC通讯,起动及调速控制 | OPC通讯
1 概述 TCP/IP 通讯的传输时间可能太长,并且该时间具有不确定性,无法满足生产自动化领域的要求.因此,在进行时间要求苛刻的IO 有效载荷数据通讯时,PROFINET IO 不使用TCP/IP,而 ...
- 利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进 程的信息?
ps -ef (system v 输出) ps -aux bsd 格式输出 ps -ef | grep pid
- SpringMVC的入门程序
1.环境准备(jar包) 2.在web.xml中配置前端控制器 <!-- springmvc 前端控制器 --> <servlet> <servlet-name>s ...
- IOC——Spring的bean的管理(注解方式)
注解(简单解释) 1.代码里面特殊标记,使用注解可以完成一定的功能 2.注解写法 @注解名称(属性名称=属性值) 3.注解使用在类上面,方法上面和属性上面 注意:注解方式不能完全替代配置文件方式 Sp ...
- 学习git(一)
一.自动化运维 1.网络层(接入层.汇聚层.核心层): 1 LB+HA(L4.L7): 2 服务层(reverse proxy cache.应用层.web层.SOA层.分布式层.DAL): 3 数据层 ...
- eclipse开发工具之“指定Maven仓库和setting.xml文件位置”
1.先点击window,然后选择Preferences按钮进入设置 2.找到Maven,选择UserSettings 点击Browse控件,添加setting.xml 点击Reindex控件,添加依赖 ...
- canvas 实现 github404动态效果
使用canvas来完成github404的动态效果 前几天使用css样式和js致敬了一下github404的类似界面,同时最近又接触了canvas,本着瞎折腾的想法,便借着之前的js的算法,使用can ...
- Javascript Symbol 隐匿的未来之星
ES6中基础类型增加到了7种,比上一个版本多了一个Symbol,貌似出现了很长时间,但却因没有使用场景,一直当作一个概念层来理解它,我想,用它的最好的方式,还是要主动的去深入了解它吧,所以我从基础部分 ...