爬虫之图片懒加载技术、selenium工具与PhantomJS无头浏览器
图片懒加载
图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片,达到减少首屏图片请求数的技术就被称为“图片懒加载”。
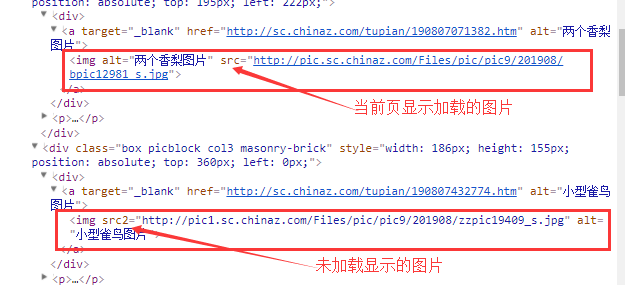
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original......)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。
因此在爬虫时,对当前页加载的数据进行分析发起请求获取解析数据会出现数据解析不完整,究其原因很有可能是图片的懒加载技术导致,因此要在爬虫时要特别注意准确解析数据!(比如站长素材高清图片的爬取)
selenium自动化(测试)工具
简介
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
环境安装
- 下载安装selenium:pip install selenium
- 下载浏览器驱动程序:
- 查看驱动和浏览器版本的映射关系:
以百度搜索为例:
'''
下载浏览器驱动程序:https://npm.taobao.org/mirrors/chromedriver
查看驱动和浏览器版本的映射:http://blog.csdn.net/huilan_same/article/details/51896672
'''
import time
from lxml.html.clean import etree from selenium import webdriver#pip install selenium 导入浏览器驱动
#(1)创建(谷歌等)浏览器,参数为浏览器驱动位置
browser=webdriver.Chrome(r"./chromedriver.exe") #(2)通过浏览器发起get请求
browser.get('https://www.baidu.com/') #(3)进行关键字搜索等页面操作
#①定位搜索框标签(可通过多种方式进行定位)
search_input=browser.find_element_by_id('kw')
#②定位搜索按钮
search_button=browser.find_element_by_xpath('//input[@id="su"]')
#③在输入框输入关键字
search_input.send_keys('selenium')
time.sleep(2)
#④清空输入框
search_input.clear()
time.sleep(2)
search_input.send_keys('selenium工具包')
time.sleep(2)
#⑤点击搜索按钮
search_button.click()
time.sleep(2)
#⑥向下滑动滚动条到底部
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(2)
#⑦向下滑动滚动条到顶部
browser.execute_script("window.scrollTo(0,-document.body.scrollHeight)")
time.sleep(2) #获取当前页面内容进行说数据解析
page_text=browser.page_source
print(etree.HTML(page_text).xpath('//span[@class="nums_text"]/text()')[0]) # 处理弹出的警告页面:确定accept() 和 取消dismiss()
# browser.switch_to_alert().accept()
# time.sleep(2) #(3)关闭浏览器
# browser.close()
browser.quit()
selenium简单使用案例--百度搜索
浏览器驱动
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
元素定位
webdriver 提供了一系列的元素定位方法,常用的有以下几种:
find_element_by_id()
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()注意
1、find_element_by_xxx找的是第一个符合条件的标签,find_elements_by_xxx找的是所有符合条件的标签。
2、根据ID、CSS选择器和XPath获取,它们返回的结果完全一致。
3、另外,Selenium还提供了通用方法
find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。
节点交互(文本输出与清空)
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用
send_keys()方法,清空文字时用clear()方法,点击按钮时用click()方法。import time
from selenium import webdriver
browser=webdriver.Chrome(r"./chromedriver.exe")
browser.get('https://www.baidu.com/')
search_input=browser.find_element_by_id('kw')search_input.send_keys('selenium')#输入文字
time.sleep(2) search_input.clear()#清空文字
time.sleep(2)
动作链
一些交互动作是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
# 实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现
import time
from selenium import webdriver
from selenium.webdriver import ActionChains browser = webdriver.Chrome(r'./chromedriver.exe')
browser.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable") # 分析页面标签可以发现页面中嵌套了html,实用的是frame框架,因此需要先定位iframe
browser.switch_to_frame("iframeResult") # 通过id定位iframe # 找到要拖动的标签和要拖动到的标签
start = browser.find_element_by_id("draggable")
end = browser.find_element_by_id("droppable")
# 实例化动作对象
actions = ActionChains(browser) # (1)拖拽动作,参数为起始对象,perform()立即执行
# actions.drag_and_drop(start,end).perform()
# time.sleep(2) # (2)缓慢执行拖动动作
actions.click_and_hold(start)
for i in range(5):
actions.move_by_offset(xoffset=18,yoffset=0).perform()
time.sleep(0.5)
actions.release()
start.click()
time.sleep(2) # 处理页面的弹出警示框
browser.switch_to_alert().accept()
time.sleep(2) browser.close()
browser.quit()
selenium动作链实例
执行JavaScript
对于某些操作,Selenium API并没有提供。比如,下拉进度条,它可以直接模拟运行JavaScript,此时使用
execute_script()方法即可实现。
import time
from selenium import webdriver browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
time.sleep(1)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')#操作滚动条
time.sleep(2)
browser.execute_script('alert("123")')#操作警示弹窗
time.sleep(2)
browser.switch_to_alert().accept()
time.sleep(2)
browser.quit()
selenium执行js代码
获取页面源码数据
通过
page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取信息了。
import time
from lxml.html.clean import etree from selenium import webdriver browser=webdriver.Chrome(r"./chromedriver.exe")
browser.get('https://www.baidu.com/')
search_input=browser.find_element_by_id('kw')
search_button=browser.find_element_by_xpath('//input[@id="su"]')
search_input.send_keys('selenium工具包')
time.sleep(2)
search_button.click()
time.sleep(2) page_text=browser.page_source#获取页面源码
print(etree.HTML(page_text).xpath('//span[@class="nums_text"]/text()')[0])
browser.quit()
selenium获取页面源码
前进和后退
模拟浏览器的前进和回退功能
import time
from selenium import webdriver
browser=webdriver.Chrome() browser.get('https://www.baidu.com/')
browser.get('https://www.jd.com/')
browser.get('https://www.sina.com.cn/') time.sleep(3)
browser.back()#浏览器后退
time.sleep(3)
browser.forward()#浏览器前进
time.sleep(3)
browser.close()
selenium模拟浏览器前进后退
规避被检测识别
不少大网站有对selenium采取了监测机制。比如正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为 undefined。而使用selenium访问则该值为true。因此需要设置Chromedriver的启动参数来解决问题。
在启动Chromedriver之前,为Chrome开启实验性功能参数
excludeSwitches,它的值为['enable-automation']
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option=ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
browser=webdriver.Chrome(options=option) browser.get('https://www.baidu.com/')
selenium规避监测识别
Cookie处理
selenium模拟浏览器操作,可以不用考虑在页面数据获取时cookie问题,但是如果想操作cookie,使用Selenium也是可以实现的,例如获取、添加、删除Cookies等。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'value': ''})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
selenium操作cookie
phantomJS
PhantomJS是一款无界面的浏览器,其自动化操作流程和上述操作谷歌浏览器是一致的。由于是无界面的,为了能够展示自动化操作流程,PhantomJS为用户提供了一个截屏的功能,使用save_screenshot函数实现。PhantomJS下载地址:https://phantomjs.org/download.html,目前已经停止维护和更新,因此不建议使用,可以使用谷歌的无头浏览器。
from selenium import webdriver
import time # phantomjs路径
path = r'PhantomJS驱动路径'
browser = webdriver.PhantomJS(path) # 打开百度
url = 'http://www.baidu.com/'
browser.get(url) time.sleep(3) browser.save_screenshot(r'phantomjs\baidu.png') # 查找input输入框
my_input = browser.find_element_by_id('kw')
# 往框里面写文字
my_input.send_keys('美女')
time.sleep(3)
#截屏
browser.save_screenshot(r'phantomjs\meinv.png') # 查找搜索按钮
button = browser.find_elements_by_class_name('s_btn')[0]
button.click() time.sleep(3) browser.save_screenshot(r'phantomjs\show.png') time.sleep(3) browser.quit()
PhantomJS无头浏览器
谷歌无头浏览器
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 创建一个参数对象,用来控制chrome以无界面模式打开
chrome_options=Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu') #谷歌浏览器驱动路径
chrome_path=r'chromedriver.exe'#当前目录 #创建浏览器对象
# browser=webdriver.Chrome(executable_path=chrome_path, chrome_options=chrome_options)
browser=webdriver.Chrome(chrome_path,chrome_options=chrome_options) browser.get('https://www.baidu.com/')
time.sleep(4)
browser.save_screenshot('baidu.png')#截图
browser.quit()
selenium实现谷歌无头浏览器
爬虫之图片懒加载技术、selenium工具与PhantomJS无头浏览器的更多相关文章
- 爬虫之图片懒加载技术、selenium和PhantomJS
爬虫之图片懒加载技术.selenium和PhantomJS 图片懒加载 selenium phantomJs 谷歌无头浏览器 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http:/ ...
- 08.Python网络爬虫之图片懒加载技术、selenium和PhantomJS
引入 今日概要 图片懒加载 selenium phantomJs 谷歌无头浏览器 知识点回顾 验证码处理流程 今日详情 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材ht ...
- Python网络爬虫之图片懒加载技术、selenium和PhantomJS
引入 图片懒加载 selenium phantomJs 谷歌无头浏览器 知识点回顾 验证码处理流程 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.ch ...
- Python爬虫之图片懒加载技术、selenium和PhantomJS
一.引入 2.概要 图片懒加载 selenium phantomJs 谷歌无头浏览器 3.回顾 验证码处理流程 一.今日详情 动态数据加载处理 1.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素 ...
- python爬虫之图片懒加载、selenium和phantomJS
一.什么是图片懒加载 在网页中,常常需要用到图片,而图片需要消耗较大的流量.正常情况下,浏览器会解析整个HTML代码,然后从上到下依次加载<img src="xxx"> ...
- 爬虫之图片懒加载技术及js加密
图片懒加载 图片懒加载概念: 图片懒加载是一种网页优化技术.图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间.为了 ...
- 爬虫(七)图片懒加载技术、selenium和PhantomJS
动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/中的图片数据 #!/usr/bin/env python # -*- coding ...
- 图片懒加载,Selenium,PhantomJS
引入 今日概要 图片懒加载 selenium phantomJs 谷歌无头浏览器 知识点回顾 验证码处理流程 今日详情 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材ht ...
- 爬虫之 图片懒加载, selenium , phantomJs, 谷歌无头浏览器
一.图片懒加载 懒加载 : JS 代码 是页面自然滚动 window.scrollTo(0,document.body.scrollHeight) (重点) bro.execute_ ...
随机推荐
- NC使用练习之通达OA-2017版本漏洞复现后续
利用上一篇通达OA的漏洞环境,练习NC工具的使用. 步骤: 1.本机启动nc.exe监听端口: 确认端口是否成功监听成功: 2.用冰蝎将nc.exe上传至目标机: 3.用命令行在目标机启动nc.exe ...
- Vue tools开发工具报错Cannot read property '__VUE_DEVTOOLS_UID__' of undefined
使用 vue tools 开发工具,不显示调试面板中的组件,点击控制台报错: Cannot read property 'VUE_DEVTOOLS_UID' of undefined 在 main.j ...
- 在Jetson TX2上捕获、显示摄像头视频
参考文章:How to Capture and Display Camera Video with Python on Jetson TX2 与参考文章大部分都是相似的,如果不习惯看英文,可以看看我下 ...
- 题目分享E 二代目
题意:一棵点数为n的树,每个节点有点权,要求在树中中找到一个最小的x,使得存在一个点满足max(该点点权,该点相邻的点的点权+1,其他点的点权+2)=x 分析:首先要能把题目转化为上述题意 首先题目让 ...
- c/c++获取文件夹下所有文件名
如何获取某一文件夹下所有文件名,是一个很有意思的问题.网上代码很多,找了个简单的,特此收录. #include <iostream> #include <io.h> #incl ...
- linux进程管理相关命令
ps ps aux ps -ef | grep -E "supervisor|PPID" top 可以按一定规则对top的结果进行排序 # 监控单一进程 top -p pid ...
- linux关于suid提权笔记
suid全称是Set owner User ID up on execution.这是Linux给可执行文件的一个属性,上述情况下,普通用户之所以也可以使用ping命令,原因就在我们给ping这个可执 ...
- Hadoop-wordCount实例代码编写(Hadoop学习第四天)
1.新建一个maven项目2.pom文件中引入以下jar包<dependency> <groupId>org.apache.hadoop</groupId> < ...
- 戴尔服务器ipmi报错
戴尔服务器ipmi配置完成,用浏览器打开报错 查看器已终止,网络已中断 原因:这个问题是java报错,用火狐打开报错 解决方法: 用IE打开就没问题,IE要用较高版本的,楼主的是win10-IE11
- c#一些常用知识点
UID自动生成随机数 UID.Text = Guid.NewGuid().ToString(); GridView中常用格式化公式 <asp:BoundField DataField=" ...