ConcurrentHashMap比其他并发集合的安全效率要高一些?

- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
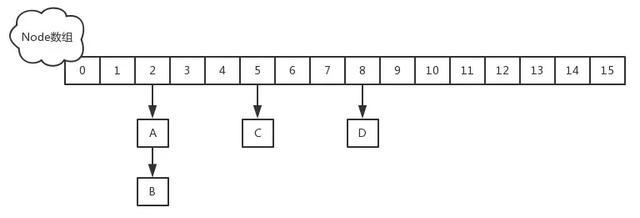
- 首先计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
- 以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
- volatile关键字对于基本类型的修改可以在随后对多个线程的读保持一致,但是对于引用类型如数组,实体bean,仅仅保证引用的可见性,但并不保证引用内容的可见性。。
- 禁止进行指令重排序。
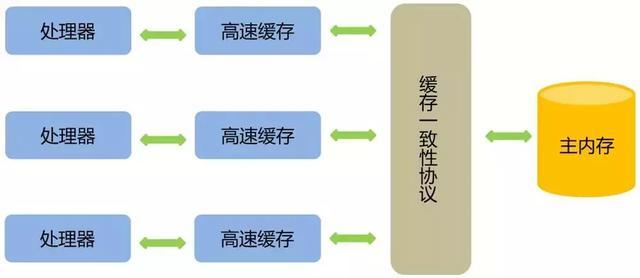
- 如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。
- 在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,当某个CPU在写数据时,如果发现操作的变量是共享变量,则会通知其他CPU告知该变量的缓存行是无效的,因此其他CPU在读取该变量时,发现其无效会重新从主存中加载数据。

- 在1.8中ConcurrentHashMap的get操作全程不需要加锁,这也是它比其他并发集合比如hashtable、用Collections.synchronizedMap()包装的hashmap;安全效率高的原因之一。
- get操作全程不需要加锁是因为Node的成员val是用volatile修饰的和数组用volatile修饰没有关系。
- 数组用volatile修饰主要是保证在数组扩容的时候保证可见性。
ConcurrentHashMap比其他并发集合的安全效率要高一些?的更多相关文章
- java多线程中并发集合和同步集合有哪些?区别是什么?
java多线程中并发集合和同步集合有哪些? hashmap 是非同步的,故在多线程中是线程不安全的,不过也可以使用 同步类来进行包装: 包装类Collections.synchronizedMap() ...
- Java并发集合的实现原理
本文简要介绍Java并发编程方面常用的类和集合,并介绍下其实现原理. AtomicInteger 可以用原子方式更新int值.类 AtomicBoolean.AtomicInteger.AtomicL ...
- Java多线程 阻塞队列和并发集合
转载:大关的博客 Java多线程 阻塞队列和并发集合 本章主要探讨在多线程程序中与集合相关的内容.在多线程程序中,如果使用普通集合往往会造成数据错误,甚至造成程序崩溃.Java为多线程专门提供了特有的 ...
- Java 并发集合的实现原理
http://www.codeceo.com/article/the-implementation-principle-of-java-concurrent-collection.html 阿凡卢 ...
- Java并发编程之同步/并发集合
同步集合 Java中同步集合如下: Vector:基于数组的线程安全集合,扩容默认增加1倍(ArrayList50%) Stack:继承于Vector,基于动态数组实现的一个线程安全的栈 Hashta ...
- .Net多线程编程—并发集合
并发集合 1 为什么使用并发集合? 原因主要有以下几点: System.Collections和System.Collections.Generic名称空间中所提供的经典列表.集合和数组都不是线程安全 ...
- 《C#并行编程高级教程》第4章 并发集合 笔记
这一章主要介绍了System.Collections.Concurrent下的几个类. ConcurrentQueue<T> 并发队列.完全无锁,使用CAS(compare-and-swa ...
- 转载 .Net多线程编程—并发集合 https://www.cnblogs.com/hdwgxz/p/6258014.html
集合 1 为什么使用并发集合? 原因主要有以下几点: System.Collections和System.Collections.Generic名称空间中所提供的经典列表.集合和数组都不是线程安全的, ...
- C#并发集合(转)
出处:https://www.cnblogs.com/Leo_wl/p/6262749.html?utm_source=itdadao&utm_medium=referral 并发集合 1 为 ...
随机推荐
- 【故障公告】数据库服务器 CPU 近 100% 引发的故障(源于 .NET Core 3.0 的一个 bug)
非常抱歉,这次故障给您带来麻烦了,请您谅解. 今天早上 10:54 左右,我们所使用的数据库服务(阿里云 RDS 实例 SQL Server 2016 标准版)CPU 突然飙升至 90% 以上,应用日 ...
- python进程池与线程池
为什么会进行池化? 一切都是为了效率,每次开启进程都会分配一个属于这个进程独立的内存空间,开启进程过多会占用大量内存,系统调度也会很慢,我们不能无限的开启进程. 进程池原来大概如下图 假设有100个任 ...
- Fortran文件读写--xdd
1.常规读写 program FileWriteRead implicit none open(unit=,file="F:\desktop\File.txt") !open(un ...
- T1110-计算线段长度
原题链接: https://nanti.jisuanke.com/t/T1010 题目简述: 已知线段的两个端点的坐标A(Xa,Ya),B(Xb,Yb)A(X_a,Y_a),B(X_b,Y_b)A(X ...
- SpringAOP之使用切入点创建通知
之前已经说过了SpringAOP中的几种通知类型以及如何创建简单的通知见地址 一.什么是切入点 通过之前的例子中,我们可以创建ProxyFactory的方式来创建通知,然后获取目标类中的方法.通过不同 ...
- CentOS 7 Keepalive 脚本不执行解决
目录 问题 问题一 括号问题 问题二 脚本名称问题 问题 起因是在测试部署 Altls + Keepalive 高可用读写分离,测试停止Atlas服务的时候,发现Keepalive不会自动主从切换,就 ...
- mysql那些事(6) WHERE条件 字符串的引号
前言:所谓的坑,两个意思,一个是软件本身的bug,一个是使用者常犯的错误. phper在日常开发中经常和mysql打交道.特别是在没有分层的中小应用中,phper开发要关注sql语句的实现. 入正题, ...
- PTA 1139 1138 1137 1136
PAT 1139 1138 1137 1136 一个月不写题,有点生疏..脑子跟不上手速,还可以啦,反正今天很开心. PAT 1139 First Contact 18/30 找个时间再修bug 23 ...
- tp5引用第三方类vendor或extend(多种方法)
extend 方法一:命名空间引入 我们只需要把自己的类库包目录放入EXTEND_PATH目录(默认为extend,可配置),就可以自动注册对应的命名空间,例如: 我们在extend目录下面新增一个l ...
- js学习——1
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...