Seaborn数据可视化入门
在本节学习中,我们使用Seaborn作为数据可视化的入门工具
Seaborn的官方网址如下:http://seaborn.pydata.org
一:definition
Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics.
Seaborn是基于matplotlib的数据可视化库,它的主要功能是做数据可视化
二:Setup the notebook
对数据进行初始化,引入相应的包
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
pirnt("Setup Complete")
三: Load the data
加载数据
file_path = "../input/fifa.csv"
fifa_data = pd.read_csv(file_path, index_col="Date", parse_Dates=True)

注:
file_path:
表示dataset的路径
idnex_col="Date" :
When we load the dataset, we want each entry in the first column to denote a different row. To do this, we set the value of index_col to the name of the first column ("Date", found in cell A1 of the file when it's opened in Excel).
parse_dates=True:
This tells the notebook to understand the each row label as a date (as opposed to a number or other text with a different meaning).
四: Examine the data
列出数据的前5行检验:
fifa_data.head()

五: Plot the data
- Line Chart
plt.figure(figsize=(16,6))
sns.lineplot(data=fifa_data)

注:
plt.figure(figsize=(16,6))
设定的是图形的宽度和高度
plt.title("name") 增加title,并命名为name
sns.lineplot(data=fifa_data)画出数据的线状图
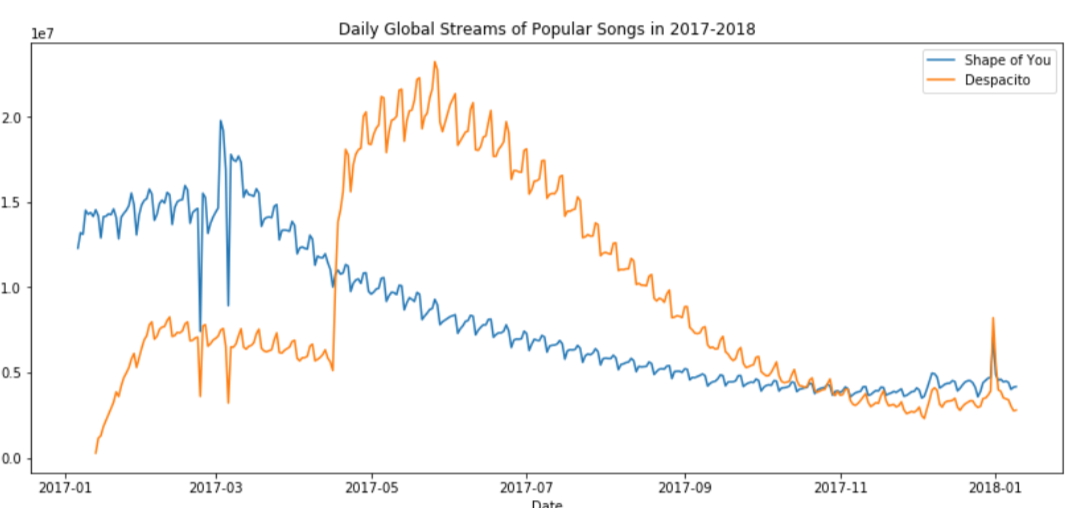
若想plot a subset of the data (仅仅画出一部分图线):
sns.lineplot(data=spotify["shape of you"],label=shape of you")
sns.lineplot(data=spotify["despacito"], label="despatito")
plt.xlabel("name X")
plt.blabel("name Y")
注:
plt.xlabel
plt.ylabel
是分别对label x, y 进行命名
- Bar Charts
plt.title("Average Arrival Delay for Spirit Airlines Flights, by Month")
sns.barplot(x=flight_data.index, y=flight_data['NK'])
plt.ylabel("Arrival delay (in minutes)"

注:
x=flight_data.index :
This determines what to use on the horizontal axis. In this case, we have selected the column that indexes the rows (in this case, the column containing the months).
- Heat Maps
plt.figure(figsize=(16,6))
plt.title("Average Arrival Delay for Each Airline, by Month")
sns.heatmap(data=flight_data,annot=True)
plt.xlabel("Airline")
注:
sns.heatmap:
This tells the notebook that we want to create a heatmap.
data=flight_data:
This tells the notebook to use all of the entries in flight_data to create the heatmap
annot=Ture:
This ensures that the vlaues for each cell appear on the chart.

- Scatter plots
(1) sns.scatterplot (x=insurance_data['bmi'], y=insurance_data['charges'])

注:
the horizontal x-axis (x=insurance_data['bmi'])
the vertical y-axis (y=insurance_data['charges'])
(2) 为了看出点的关系强度,可以使用regression line(回归线)
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])

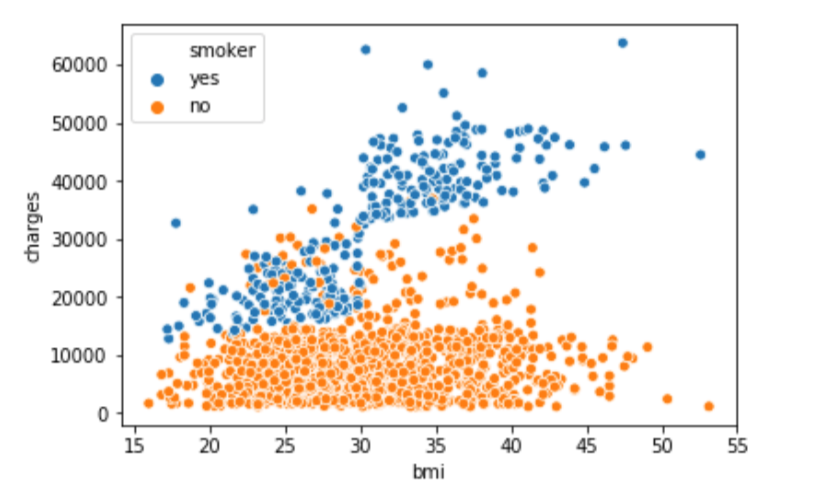
(3) sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])
hue=insurance_data['smoker']:按照hue来对数据进行标色
- Histograms
sns.distplot(a=iris_data['Petal Length (cm)'], kde=False)

- Density plots
更平滑的图:
sns.kdeplot(data=iris_data['Petal Length(cm)'], shade=True)

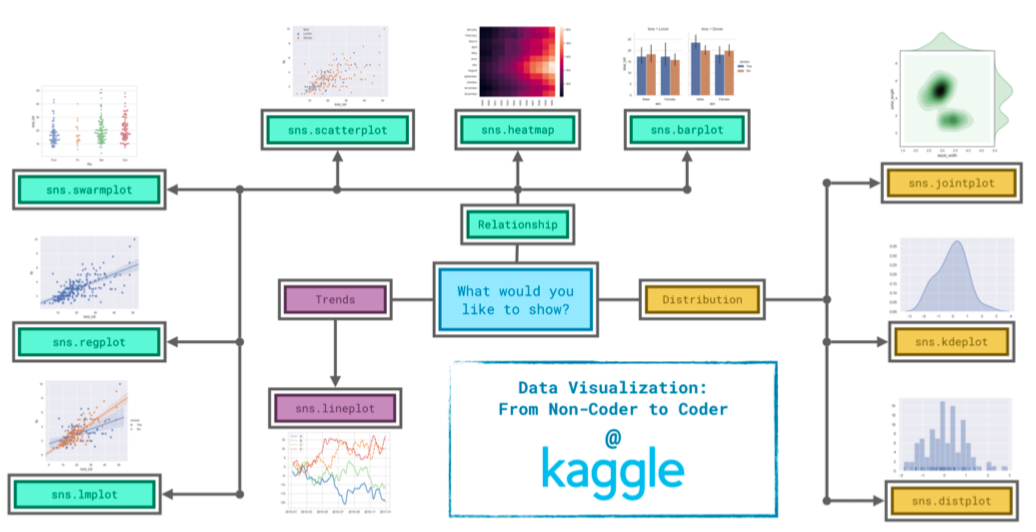
六:Conclusion
下图显示,在seaborn中,选择图形需要根据需求来决定
Seaborn数据可视化入门的更多相关文章
- 数据可视化入门之show me the numbers
数据的可视化一直是自己瞎玩着学,近来想系统的学数据可视化的东西,于是搜索资料时看到有人推荐<show me the numbers>作为入门. 由于搜不到具体的书籍内容,只能 ...
- seaborn 数据可视化(一)连续型变量可视化
一.综述 Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,图像也更加美观,本文基于seaborn官方API还有自己的一些理解. 1.1.样式控制: ...
- python学习笔记(2):科学计算及数据可视化入门
一.NumPy 1.NumPy:Numberical Python 2.高性能科学计算和数据分析的基础包 3.ndarray,多维数组(矩阵),具有矢量运算的能力,快速.节省空间 (1)ndarray ...
- seaborn 数据可视化(二)带有类别属性的数据可视化
Seaborn的分类图分为三类,将分类变量每个级别的每个观察结果显示出来,显示每个观察分布的抽象表示,以及应用统计估计显示的权重趋势和置信区间: 第一个包括函数swarmplot()和stripplo ...
- PoPo数据可视化周刊第4期
PoPo数据可视化 聚焦于Web数据可视化与可视化交互领域,发现可视化领域有意思的内容.不想错过可视化领域的精彩内容, 就快快关注我们吧 :) 微信号:popodv_com 由于国庆节的原因,累计 ...
- Python数据可视化-seaborn库之countplot
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是s ...
- kaggle入门项目:Titanic存亡预测(三)数据可视化与统计分析
---恢复内容开始--- 原kaggle比赛地址:https://www.kaggle.com/c/titanic 原kernel地址:A Data Science Framework: To Ach ...
- 数据可视化 seaborn绘图(1)
seaborn是基于matplotlib的数据可视化库.提供更高层的抽象接口.绘图效果也更好. 用seaborn探索数据分布 绘制单变量分布 绘制二变量分布 成对的数据关系可视化 绘制单变量分布 se ...
- Python图表数据可视化Seaborn:3. 线性关系数据| 时间线图表| 热图
1. 线性关系数据可视化 lmplot( ) import numpy as np import pandas as pd import matplotlib.pyplot as plt import ...
随机推荐
- oracle 断电启动失败:ORA-00600: internal error code, arguments
转载地址: http://www.2cto.com/database/201312/261602.html 由于服务器断电,启动 oracle 时报 ORA-00600 错误 查看 oracle tr ...
- 12、面向对象的思想(OOP)
面向对象与面向过程 1.都是解决问题的思维方式,都是代码的组织的方式: 2.解决简单的问题可以使用面向过程: 3.解决复杂的问题建议使用面向对象,微观处理依旧会使用面向过程. 对象的进化史(数据管理的 ...
- CSS3: @font-face 介绍与使用
@font-face 是CSS3中的一个模块,他主要是把自己定义的Web字体嵌入到你的网页中,随着@font-face模块的出现,我们在Web的开发中使用字体不怕只能使用Web安全字体,你们当中或许有 ...
- collection介绍
1.collection介绍 在mongodb中,collection相当于关系型数据库的表,但并不需提前创建,更不需要预先定义字段 db.collect1.save({username:'mayj' ...
- Promise对象的resolve回调函数和reject回调函数使用
Promise是ES6中用来结局回调地狱的问题的但是并不能帮我们减少代码量 Promise是一个构造函数 new Promise() 得到一个Promise一个实例 在Promise上有两个函数分别是 ...
- Salesforce LWC学习(四) 父子component交互 / component声明周期管理 / 事件处理
我们在上篇介绍了 @track / @api的区别.在父子 component中,针对api类型的变量,如果声明以后就只允许在parent修改,son component修改便会导致报错. sonIt ...
- 解决OneNote同步出错
问题: onenote同步出现黄色叹号. 解决: 分析: 对每个分区进行设置密码,不能设置的证明该分区有问题.(可能不只一个分区卡同步) 解决方法: 1,将有问题的分区分制一份,然后删掉原来的分区 2 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2不容错过(上)
背景 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 数据湖的核心功能, ...
- thinkPhP 引入Smarty模板引擎及配置
做配置: TMPL_ENGINE_TYPE = “Smarty” 给smarty做配置: TMPL_ENGINE_CONFIG = array( 左标记, 右标记, )
- springBoot入门教程(图文+源码+sql)
springBoot入门 1 springBoot 1.1 SpringBoot简介 Spring Boot让我们的Spring应用变的更轻量化.比如:你可以仅仅依靠一个Java类来运行一个Spr ...