数据可视化 seaborn绘图(1)
seaborn是基于matplotlib的数据可视化库.提供更高层的抽象接口.绘图效果也更好.

用seaborn探索数据分布
- 绘制单变量分布
- 绘制二变量分布
- 成对的数据关系可视化
绘制单变量分布
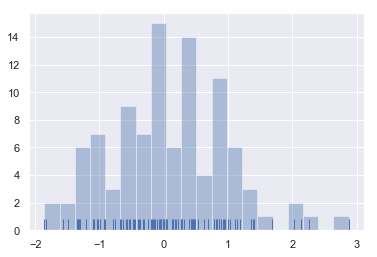
seaborn里最常用的观察单变量分布的函数是distplot()。默认地,这个函数会绘制一个直方图,并拟合一个核密度估计.如下所示:
x = np.random.normal(size=100)
sns.distplot(x);

首先解释一下啥叫核密度估计.wiki wiki里的一大堆数学证明看着就可怕....
简单地说:所谓核密度估计,就是采用平滑的峰值函数(“核”)来拟合观察到的数据点,从而对真实的概率分布曲线进行模拟.
说人话的话,就是:我们有很多样本,但再多的样本,也是离散的.所谓核密度估计,就是根据离散采样,估计连续密度分布. 所以样本量得大,假如你就3,5个样本,还有什么好估计的.
那核密度估计的原理是啥呢?
你上网搜索的话,大概率会搜到这个:
核密度函数的原理比较简单,在我们知道某一事物的概率分布的情况下,如果某一个数在观察中出现了,我们可以认为这个数的概率密度很大,和这个数比较近的数的概率密度也会比较大,而那些离这个数远的数的概率密度会比较小。
基于这种想法,针对观察中的第一个数,我们可以用K去拟合我们想象中的那个远小近大概率密度。对每一个观察数拟合出的多个概率密度分布函数,取平均。如果某些数是比较重要的,则可以取加权平均。
说实在的,我还是觉得很难理解.......
好在,一图胜千言!
x = np.random.normal(0, 1, size=30)
bandwidth = 1.06 * x.std() * x.size ** (-1 / 5.)
support = np.linspace(-4, 4, 200) kernels = []
for x_i in x: kernel = stats.norm(x_i, bandwidth).pdf(support)
kernels.append(kernel)
plt.plot(support, kernel, color="r") sns.rugplot(x, color=".2", linewidth=3);
.
即:假如有x个样本,如果我们用Gaussian Kernel Density(就是常说的正态分布啦),对每一个样本,我们都认为这个样本处在一个正态分布的峰值位置,(因为我们已经发现这个样本了).这样,就拟合出了x个正态分布曲线. 将这些曲线叠加取平均再正则化,就得到了最终的核密度估计分布曲线.
这里我们用的是kernel是gaussian.其实kernel有很多种,其中gau是最常用的.
kernel : {‘gau’ | ‘cos’ | ‘biw’ | ‘epa’ | ‘tri’ | ‘triw’ }, optional
displot参数
sns.distplot(x, kde=False, rug=True);
rug=True:绘制出离散样本

sns.distplot(x, bins=20, kde=False, rug=True);
bins=20:直方图的"柱子"的个数
更多参数,看文档去吧:displot api
绘制双变量分布
最常用的方法是散点图绘制 matplotlib.scatter seaborn中是jointplot
首先我们生成一个二元正态分布矩阵
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"]) 散点图绘制sns.jointplot(x="x", y="y", data=df);
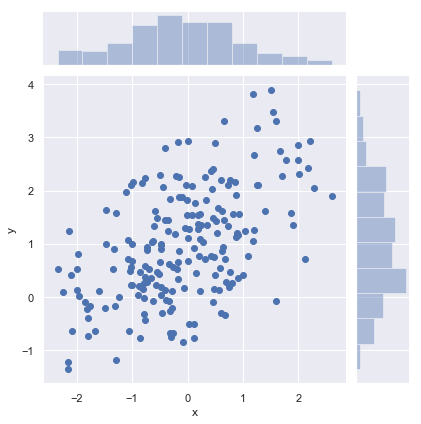
这种散点图有一个问题,相同的点会覆盖在一起.导致我们看不出来浓密和稀疏.
sns.jointplot(x=x, y=y, kind="hex", color="k");
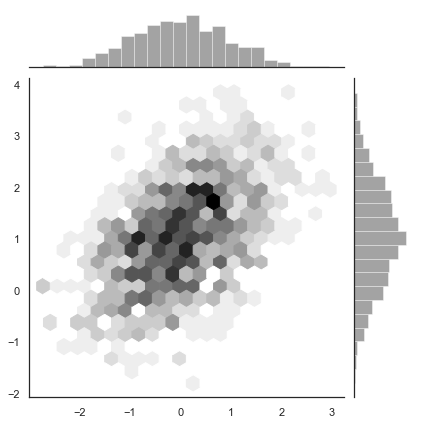
核密度分布估计

jointpoint函数使用JointGrid对象来绘图.为了提供更多的灵活性,jointpoint()返回一个JointGrid对象,你可以绘制出自己定制的图.
g = sns.jointplot(x="x", y="y", data=df, kind="kde", color="m")
g.plot_joint(plt.scatter, c="w", s=30, linewidth=1, marker="+")
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels("$X$", "$Y$");

绘制成对的数据关系可视化
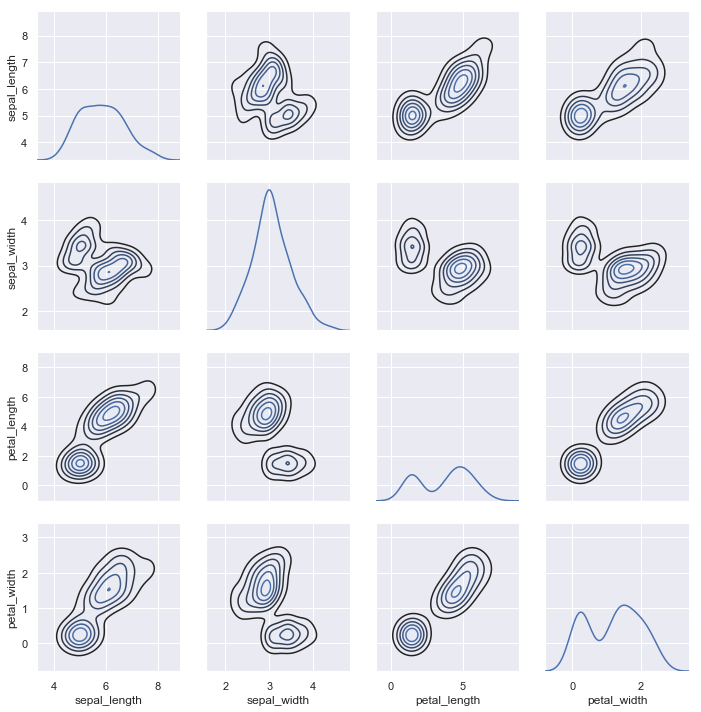
以著名的iris数据集为例. iris数据集有4个特征.那么两两组成一个pair的话,就有16种组合.用pairplot()绘制如下:
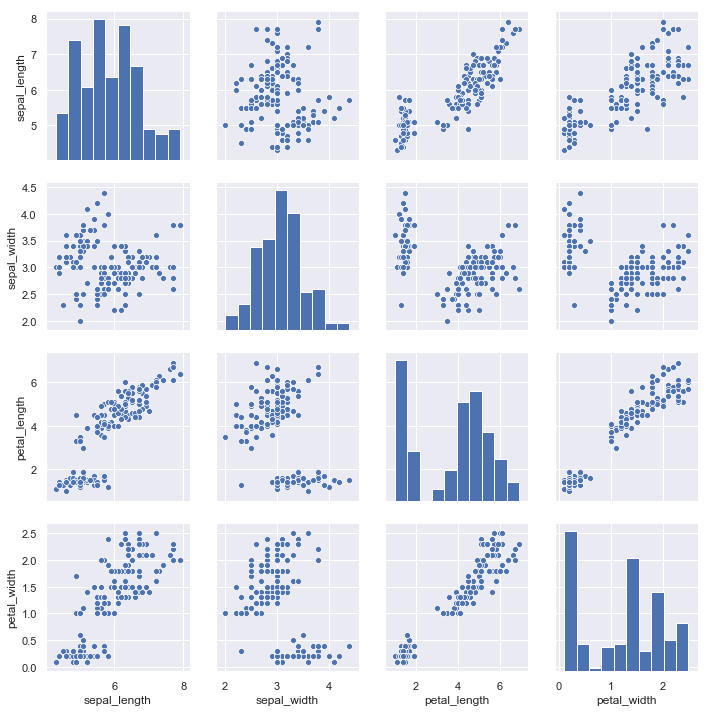
和jointplot类似,pairplot是基于PairPlot对象的.直接用PairPlot对象,可以更加灵活地绘制你想要的图
比如绘制iris数据集的核密度分布估计.
g = sns.PairGrid(iris)
g.map_diag(sns.kdeplot)
g.map_offdiag(sns.kdeplot, n_levels=6);
数据可视化 seaborn绘图(1)的更多相关文章
- 数据可视化 seaborn绘图(2)
统计关系可视化 最常用的关系可视化的函数是relplot seaborn.relplot(x=None, y=None, hue=None, size=None, style=None, data=N ...
- Python数据可视化-seaborn库之countplot
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是s ...
- Python图表数据可视化Seaborn:2. 分类数据可视化-分类散点图|分布图(箱型图|小提琴图|LV图表)|统计图(柱状图|折线图)
1. 分类数据可视化 - 分类散点图 stripplot( ) / swarmplot( ) sns.stripplot(x="day",y="total_bill&qu ...
- Python图表数据可视化Seaborn:1. 风格| 分布数据可视化-直方图| 密度图| 散点图
conda install seaborn 是安装到jupyter那个环境的 1. 整体风格设置 对图表整体颜色.比例等进行风格设置,包括颜色色板等调用系统风格进行数据可视化 set() / se ...
- Python图表数据可视化Seaborn:3. 线性关系数据| 时间线图表| 热图
1. 线性关系数据可视化 lmplot( ) import numpy as np import pandas as pd import matplotlib.pyplot as plt import ...
- Python图表数据可视化Seaborn:4. 结构化图表可视化
1.基本设置 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns ...
- Python数据可视化-seaborn
详细介绍可以看seaborn官方API和example galler. 1 set_style( ) set( ) set_style( )是用来设置主题的,Seaborn有五个预设好的主题: d ...
- 《Python数据分析》笔记——数据可视化
数据可视化 matplotlib绘图入门 为了使用matplotlib来绘制基本图像,需要调用matplotlib.pyplot子库中的plot()函数 import matplotlib.pyplo ...
- seaborn 数据可视化(一)连续型变量可视化
一.综述 Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,图像也更加美观,本文基于seaborn官方API还有自己的一些理解. 1.1.样式控制: ...
随机推荐
- Core Expression
https://docs.oracle.com/cd/E12058_01/doc/doc.1014/e12030/cron_expressions.htm A Cron Expressions Cro ...
- Visual Studio Code and local web server
It is the start of a New Year and you have decided to try Visual Studio Code, good resolution! One o ...
- 学习笔记----html的lang属性
lang属性的取值应该遵循 BCP 47 - Tags for Identifying Languages. 单一的 zh 和 zh-CN 均属于废弃用法. 问题主要在于,zh 现在不是语言code了 ...
- jQuery-事件命名空间
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- La protezione del puntatore laser
Questo puntatore laser è sempre sufficientemente efficiente per eseguire il test più accurato su qua ...
- 【阿里聚安全·安全周刊】苹果证实 iOS 源代码泄露|英国黑客赢下官司
本周的七个关键词:iOS 源代码泄露 丨 阿里软件供应链安全大赛 丨 个人数据安全 丨 Android P 丨 黑客赢下官司 丨 备忘录泄露美国安全局机密 丨 机器学习系统 -1 ...
- 包建强的培训课程(3):App竞品技术分析
@import url(http://i.cnblogs.com/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/c ...
- 12、json、GridView、缓存
1.解析json数据: public class PhotosData { public int retcode; public PhotosInfo data; public class Photo ...
- IntelliJ IDEA 的使用方法总结
创建普通 Java 项目 1.首次新建一个项目 如果是首次使用,在这个界面可以点击 Create New Project ,创建一个新项目. 选择Java,然后选好 JDK 的位置,接着点击下一步 N ...
- JavaScript 数组方法
数组方法: 1.Array.join([param]) 方法:将数组中所有的元素都转换为字符串并连接起来,通过字符 param 连接,默认使用逗号,返回最后生成的字符串 2.Array.reverse ...