百度NLP预训练模型ERNIE2.0最强实操课程来袭!【附教程】
2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨。经过短短几个月时间,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基于此框架的ERNIE 2.0预训练模型。继1.0后,ERNIE英文任务方面取得全新突破,在共计16个中英文任务上超越了BERT和XLNet, 取得了SOTA效果。
本篇内容可以说是史上最强实操课程,由浅入深完整带大家试跑ERNIE,大家可前往AI Studio fork代码 (https://aistudio.baidu.com/aistudio/projectdetail/117030),运行即可获赠12小时GPU算力,每天都有哦~
一、基础部分
1.1 准备代码、数据、模型
step1:下载ERNIE代码。温馨提示:如果下载慢,暂停重试
!git clone --depth 1 https://github.com/PaddlePaddle/ERNIE.git
step2:下载并解压finetune数据
!wget --no-check-certificate https://ernie.bj.bcebos.com/task_data_zh.tgz
!tar xf task_data_zh.tgz
step3:下载预训模型
!wget --no-check-certificate https://ernie.bj.bcebos.com/ERNIE_1.0_max-len-512.tar.gz
!mkdir -p ERNIE1.0
!tar zxf ERNIE_1.0_max-len-512.tar.gz -C ERNIE1.0
备用方案,如果下载慢的话,可以用我们预先下载好的代码和数据
%cd ~
!cp -r work/ERNIE1.0 ERNIE1.0
!cp -r work/task_data task_data
!cp -r work/lesson/ERNIE ERNIE
完成ERNIE代码部分的准备之后,让我们一起以一个序列标注任务来举例。
什么是序列标注任务?
下面这张图可以概括性的让大家理解序列标注任务:

序列标注的任务可以用来做什么?
可以:信息抽取、数据结构化,帮助搜索引擎搜索的更精准
可以:…
序列标注任务: 一起来看看这个任务的数据长什么样子吧?
序列标注任务输入数据包含2部分:
1)标签映射文件:存储标签到ID的映射。
2)训练测试数据:2列,文本、标签(文本中每个字之间使用隐藏字符\2分割,标签同理。)
# 标签映射文件
!cat task_data/msra_ner/label_map.json
{
"B-PER": 0,
"I-PER": 1,
"B-ORG": 2,
"I-ORG": 3,
"B-LOC": 4,
"I-LOC": 5,
"O": 6
}
# 测试数据
!head task_data/msra_ner/dev.tsv

B: Begin
I: Inside
O: Outside
ERNIE应用于序列化标注
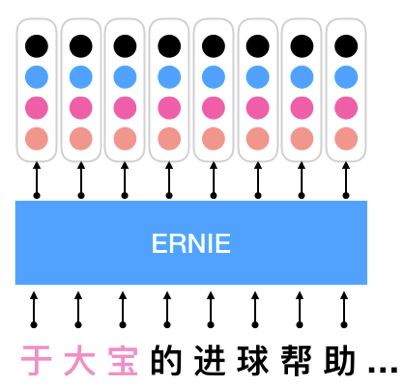
1.2 利用ERNIE做Finetune
step1:设置环境变量
%cd ERNIE
!ln -s ../task_data
!ln -s ../ERNIE1.0
%env TASK_DATA_PATH=task_data
%env MODEL_PATH=ERNIE1.0
!echo "task_data_path: ${TASK_DATA_PATH}"
!echo "model_path: ${MODEL_PATH}"
step2:运行finetune脚本
!sh script/zh_task/ernie_base/run_msra_ner.sh
1.3将Finetune结果打印
在finetune过程中,会自动保存对test集的预测结果,我们可以查看预测结果是否符合预期。
由于Finetune需要一些时间,所以不等Finetune完了,直接查看我们之前已经Finetune收敛后的模型与test集的预测结果
%cd ~
show_ner_prediction('work/lesson/test_result.5.final')
二、进阶部分
2.1 GPU显存过小,如何使用ERNIE?
脚本进阶:模型太大,无法完全放进显存的情况下,如何只使用前3层参数热启Finetune?
如果能只加载几层模型就好了!
方法:只需要修改一行配置文件ernie_config.json,就能自动的使用前3层参数热启Finetune。
提示:ernie_config.json在ERNIE1.0发布的预训练模型中
TODO 结合“终端”标签,运行一下吧
提示:您可以需要用到sed与pwd命令
step1:设置环境变量
%cd ~%cd ERNIE
!ln -s ../task_data
!ln -s ../ERNIE1.0
%env TASK_DATA_PATH=task_data
%env MODEL_PATH=ERNIE1.0
!echo "task_data_path: ${TASK_DATA_PATH}"
!echo "model_path: ${MODEL_PATH}"
!pwd
!sh script/zh_task/ernie_base/run_msra_ner.sh
2.2如何将ERNIE适配我的业务数据?
数据进阶:如何修改输入格式?
假设msra ner任务的输入数据格式变了,每条样本不是以行式保存,而是以列式保存。列式保存是指,每条样本由多行组成,每行包含一个字符和对应的label,不同样本间以空行分割,具体样例如下:
text_a label
海 O
钓 O
比 O
赛 O
地 O
点 O
在 O
厦 B-LOC
门 I-LOC
与 O
金 B-LOC
门 I-LOC
之 O
间 O
的 O
海 O
域 O
。 O

当输入数据为列式时,我们如何修改ERNIE的数据处理代码,以适应新的数据格式。
首先,我们先大致了解一下ERNIE的数据处理流程:
- ERNIE对于finetune任务的所有数据处理代码都在reader/task_reader.py中,里面已经预先写好了适合多种不同类型任务的Reader类,ERNIE通过Reader读取并处理数据给后续模型使用。
- Reader类对数据处理流程做了以下几步抽象:
step 1. 从文件中逐条读取样本,通过_read_tsv等方法,读取不同格式的文件,并将读取的每条样本存入一个list
step 2. 逐一将读取的样本转化为Record。Record中包含了一条样本经过数据处理后,模型所需要的所有features。处理成Record的流程一般又分以下几步:
1. 将文本tokenize,超过最大长度时截断;
2. 加入'[CLS]'、'[SEP]'等标记符后,将文本ID化;
3. 生成每个token对应的position和token_type信息。
step 3. 将多个Record组成batch,同一个batch内feature长度不一致时,padding至batch内最大的feature长度。
了解了ERNIE的数据处理流程以后,我们发现当输入数据格式变了,我们只需要修改第1步的代码,保持其他代码不变,就能适应新的数据格式。具体来说,只需要在reader/task_reader.py的 SequenceLabelReader 类中,加入下面的 _read_tsv 函数(重写基类 BaseReader 的 _read_tsv)。
def _read_tsv(self, input_file, quotechar=None):
with open(input_file, 'r', encoding='utf8') as f:
reader = csv_reader(f)
headers = next(reader)
text_indices = [
index for index, h in enumerate(headers) if h != 'label'
]
Example = namedtuple('Example', headers) examples = []
buf_t, buf_l = [], []
for line in reader:
if len(line) != 2:
assert len(buf_t) == len(buf_l)
example = Example(u'^B'.join(buf_t), u'^B'.join(buf_l))
examples.append(example)
buf_t, buf_l = [], []
continue
if line[0].strip() == '':
continue
buf_t.append(line[0])
buf_l.append(line[1])
if len(buf_t) > 0:
assert len(buf_t) == len(buf_l)
example = Example(u'^B'.join(buf_t), u'^B'.join(buf_l))
examples.append(example)
buf_t, buf_l = [], []
return examples
我们将已经修改好的数据和代码,预先放在work/lesson/2目录中,可以替换掉ERNIE项目中对应的文件,然后尝试运行
%cd ~
!cp -r work/lesson/2/msra_ner_columnwise task_data/msra_ner_columnwise
!cp -r work/lesson/2/task_reader.py ERNIE/reader/task_reader.py
!cp -r work/lesson/2/run_msra_ner.sh ERNIE/script/zh_task/ernie_base/run_msra_ner_columnwise.sh
%cd ERNIE
!ln -s ../task_data
!ln -s ../ERNIE1.0
%env TASK_DATA_PATH=task_data
%env MODEL_PATH=ERNIE1.0 !sh script/zh_task/ernie_base/run_msra_ner_columnwise.sh
2.3在哪里改模型结构?
模型进阶:如何将序列标注任务的损失函数替换为CRF?
目前序列标注任务的finetune代码中,以 softmax ce 作为损失函数,该损失函数较为简单,没有考虑到序列中词与词之间的联系,如何替换一个更优秀的损失函数呢?
我们只需要修改其中的create_model函数,将 softmax ce 损失函数部分,替换为 linear_chain_crf 即可,具体代码如下:
def create_model(args, pyreader_name, ernie_config, is_prediction=False):
pyreader = fluid.layers.py_reader(
capacity=50,
shapes=[[-1, args.max_seq_len, 1], [-1, args.max_seq_len, 1],
[-1, args.max_seq_len, 1], [-1, args.max_seq_len, 1],
[-1, args.max_seq_len, 1], [-1, args.max_seq_len, 1], [-1, 1]],
dtypes=[
'int64', 'int64', 'int64', 'int64', 'float32', 'int64', 'int64'
],
lod_levels=[0, 0, 0, 0, 0, 0, 0],
name=pyreader_name,
use_double_buffer=True) (src_ids, sent_ids, pos_ids, task_ids, input_mask, labels,
seq_lens) = fluid.layers.read_file(pyreader) ernie = ErnieModel(
src_ids=src_ids,
position_ids=pos_ids,
sentence_ids=sent_ids,
task_ids=task_ids,
input_mask=input_mask,
config=ernie_config,
use_fp16=args.use_fp16) enc_out = ernie.get_sequence_output()
enc_out = fluid.layers.dropout(
x=enc_out, dropout_prob=0.1, dropout_implementation="upscale_in_train")
logits = fluid.layers.fc(
input=enc_out,
size=args.num_labels,
num_flatten_dims=2,
param_attr=fluid.ParamAttr(
name="cls_seq_label_out_w",
initializer=fluid.initializer.TruncatedNormal(scale=0.02)),
bias_attr=fluid.ParamAttr(
name="cls_seq_label_out_b",
initializer=fluid.initializer.Constant(0.)))
infers = fluid.layers.argmax(logits, axis=2) ret_infers = fluid.layers.reshape(x=infers, shape=[-1, 1])
lod_labels = fluid.layers.sequence_unpad(labels, seq_lens)
lod_infers = fluid.layers.sequence_unpad(infers, seq_lens)
lod_logits = fluid.layers.sequence_unpad(logits, seq_lens) (_, _, _, num_infer, num_label, num_correct) = fluid.layers.chunk_eval(
input=lod_infers,
label=lod_labels,
chunk_scheme=args.chunk_scheme,
num_chunk_types=((args.num_labels-1)//(len(args.chunk_scheme)-1))) probs = fluid.layers.softmax(logits)
crf_loss = fluid.layers.linear_chain_crf(
input=lod_logits,
label=lod_labels,
param_attr=fluid.ParamAttr(
name='crf_w',
initializer=fluid.initializer.TruncatedNormal(scale=0.02)))
loss = fluid.layers.mean(x=crf_loss) graph_vars = {
"inputs": src_ids,
"loss": loss,
"probs": probs,
"seqlen": seq_lens,
"num_infer": num_infer,
"num_label": num_label,
"num_correct": num_correct,
} for k, v in graph_vars.items():
v.persistable = True return pyreader, graph_vars
我们将已经修改好的数据和代码,预先放在work/lesson/3 目录中,可以替换掉ERNIE项目中对应的文件,然后尝试运行
%cd ~
!cp -r work/lesson/3/sequence_label.py ERNIE/finetune/sequence_label.py
%cd ERNIE
!ln -s ../task_data
!ln -s ../ERNIE1.0
%env TASK_DATA_PATH=task_data
%env MODEL_PATH=ERNIE1.0
!sh script/zh_task/ernie_base/run_msra_ner_columnwise.sh
修改后重新运行finetune脚本:
sh script/zh_task/ernie_base/run_msra_ner.sh等待运行完后,取最后一次评估结果,对比如下:

以上便是实战课程的全部操作,直接fork可点击下方链接:
https://aistudio.baidu.com/aistudio/projectdetail/117030
划重点!
查看ERNIE模型使用的完整内容和教程,请点击下方链接,建议Star收藏到个人主页,方便后续查看。
GitHub:https://github.com/PaddlePaddle/ERNIE
版本迭代、最新进展都会在GitHub第一时间发布,欢迎持续关注!
也邀请大家加入ERNIE官方技术交流**QQ群:760439550**,可在群内交流技术问题,会有ERNIE的研发同学为大家及时答疑解惑。
百度NLP预训练模型ERNIE2.0最强实操课程来袭!【附教程】的更多相关文章
- 中文预训练模型ERNIE2.0模型下载及安装
2019年7月,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基于此框架的ERNIE 2.0预训练模型, 它利用百度海量数据和飞桨(PaddlePaddle)多机多卡高效训练优 ...
- NLP预训练模型-百度ERNIE2.0的效果到底有多好【附用户点评】
ERNIE是百度自研的持续学习语义理解框架,该框架支持增量引入词汇(lexical).语法 (syntactic) .语义(semantic)等3个层次的自定义预训练任务,能够全面捕捉训练语料中的词法 ...
- 最强中文NLP预训练模型艾尼ERNIE官方揭秘【附视频】
“最近刚好在用ERNIE写毕业论文” “感觉还挺厉害的” “为什么叫ERNIE啊,这名字有什么深意吗?” “我想让艾尼帮我写作业” 看了上面火热的讨论,你一定很好奇“艾尼”.“ERNIE”到底是个啥? ...
- 【转载】最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
本文介绍了一种新的语言表征模型 BERT--来自 Transformer 的双向编码器表征.与最近的语言表征模型不同,BERT 旨在基于所有层的左.右语境来预训练深度双向表征.BERT 是首个在大批句 ...
- zookeeper之二:zookeeper3.7.0安装过程实操
前面分享了zookeeper的基本知识,下面分享有关zookeeper安装的知识. 1.下载 zookeeper的官网是:https://zookeeper.apache.org/ 在官网上找到下载链 ...
- 使用Huggingface在矩池云快速加载预训练模型和数据集
作为NLP领域的著名框架,Huggingface(HF)为社区提供了众多好用的预训练模型和数据集.本文介绍了如何在矩池云使用Huggingface快速加载预训练模型和数据集. 1.环境 HF支持Pyt ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- 预训练模型——开创NLP新纪元
预训练模型--开创NLP新纪元 论文地址 BERT相关论文列表 清华整理-预训练语言模型 awesome-bert-nlp BERT Lang Street huggingface models 论文 ...
- NLP与深度学习(五)BERT预训练模型
1. BERT简介 Transformer架构的出现,是NLP界的一个重要的里程碑.它激发了很多基于此架构的模型,其中一个非常重要的模型就是BERT. BERT的全称是Bidirectional En ...
随机推荐
- 003-python函数式编程,模块
1.函数式编程 1.1 高阶函数 把函数作为参数传入,这样的函数称为高阶函数,函数式编程就是指这种高度抽象的编程范式 函数名也是变量,函数名其实就是指向函数的变量!对于abs()这个函数,完全可以把函 ...
- Scala Eclipse org.eclipse.e4.workbench异常奔溃修复
Scala Eclipse org.eclipse.e4.workbench异常奔溃修复: 找到<workspace>/.metadata/.plugins/org.eclipse.e4 ...
- B/S 端构建的基于 WebGL 3D 可视化档案馆管理系统
前言 档案管理系统是通过建立统一的标准以规范整个文件管理,包括规范各业务系统的文件管理的完整的档案资源信息共享服务平台,主要实现档案流水化采集功能.为企事业单位的档案现代化管理,提供完整的解决方案,档 ...
- mac系统Intellij Idea的java环境配置:JDK + Tomcat + Maven
一.JAVA JDK查看与配置 1.查看java路径详细信息: /usr/libexec/java_home -V 2.java默认路径 jdk1.6: /System/Library/Java/Ja ...
- 02-22 决策树C4.5算法
目录 决策树C4.5算法 一.决策树C4.5算法学习目标 二.决策树C4.5算法详解 2.1 连续特征值离散化 2.2 信息增益比 2.3 剪枝 2.4 特征值加权 三.决策树C4.5算法流程 3.1 ...
- A-02 梯度下降法
目录 梯度下降法 一.梯度下降法详解 1.1 梯度 1.2 梯度下降法和梯度上升法 1.3 梯度下降 1.4 相关概念 1.4.1 步长 1.4.2 假设函数 1.4.3 目标函数 二.梯度下降法流程 ...
- centos7 安装 mysql5.7 版本(全)
centos 安装 版本说明 :centos7,mysql5.7 ,不是 centos7 可能有些命令不兼容 安装 mysql-server # 下载并安装 mysql yum wget -i -c ...
- x509: certificate is valid for 10.96.0.1, 172.18.255.243, not 120.79.23.226
服务器:阿里云服务器 master:120.79.23.226 node:39.108.131.246 系统:Centos 7.4 node节点加入集群中是报错: x509: certificate ...
- (未完)XSS漏洞实战靶场笔记
记录下自己写的XSS靶场的write up,也是学习了常见xss漏洞类型的实战场景
- 爬虫3:html页面+webdriver模块+demo
保密性好的网站,不能使用request请求页面信息,这样可以使用webdriver模块先开启一个浏览器,然后爬去信息,甚至还可以click等操作对页面操作,再爬取. demo 一般流程: 1)包含se ...